















Disclaimer: This article is translated by DeepL, there is the original post in Chinese.
Customer Profile
Founded in 2007, Globalegrow is committed to building a global B2C cross-border e-commerce new retail ecology. In 2014, the listing was completed through the merger and acquisition with Baiyuan Trousers, and the listed company "Global Top (SZ002640)" is the first stock of the Chinese Stock Market listed cross-border e-commerce. After years of efforts, it has established a broad sales network in overseas markets and has been widely recognized by customers in many countries such as the United States and Europe, and the company's business has maintained a 100% growth rate over the years.
Data Platform Status and Requirements
Globalegrow provides global cross-border e-commerce services and chose AWS as the cloud service provider. At that time, the big data platform of Globalegrow faced several problems: the HDFS cluster based on EC2 and EBS was very expensive.
- The cost of HDFS cluster based on EBS was very high.
- Hadoop clusters lacked elasticity and scalability
The customer hope to reduce the cost of HDFS storage while not causing too much loss in performance. When it comes to cost reduction, it is natural to think of S3, which provides up to 11 9 data persistence while also being able to achieve low enough storage costs. But is migrating from HDFS to S3 the only option for big data cluster storage? What are the problems encountered in migration and usage? We'll cover all of this in more detail later, but first let's look at why EBS's self-built HDFS clusters are costly.
Pain points of self-built HDFS on the cloud
EBS is an easy-to-use, high-performance data block storage service that provides nearly unlimited storage capacity by mounting to EC2. To ensure the availability of data on EBS, all data is automatically replicated within the same availability zone to prevent data loss.
HDFS is the most commonly used distributed file system in Big Data today, with each file consisting of a series of data blocks. Similarly, to ensure data availability, HDFS automatically replicates these data blocks to multiple nodes in the cluster by default, for example, when the number of copies is set to 3, there will be 3 copies of the same data block in the cluster.
The difference is that EBS replicates data only for each storage volume (i.e., disk), while HDFS replicates data for the entire cluster. This dual redundancy mechanism is actually somewhat redundant and increases storage costs in disguise. The multi-copy nature of HDFS makes the actual available capacity of the cluster much smaller, for example, when the number of copies is 3, the actual available capacity is actually only 1/3 of the total disk space size, plus the cluster will usually be expanded when the space reaches a certain level, which will further compress the available capacity. For these reasons, the cost of self-built HDFS clusters on the cloud via EBS can often be as high as $150/TB/month.
What do we need to consider when migrating from HDFS to S3?
Hadoop Community Edition already supports reading and writing data from S3 by default, which is commonly referred to as "S3A". But if you look at the official documentation for S3A, you'll see a couple of big warnings at the beginning that list some of the problems that exist in S3-like object storage.
Consistency Model
S3's Consistency Model is Eventual Consistency, which means that when a new file is created, it is not necessarily seen immediately. When a delete or update operation is performed on a file, it is possible that the old data will still be read. These consistency problems can lead to program crashes, such as the common java.io.FileNotFoundException, and can also lead to incorrect computation results, which are more problematic because they are difficult to detect. During our testing, we experienced frequent errors in the execution of the DistCp task due to S3 consistency issues, which resulted in a serious impact on data migration.
No real directory
The "directories" in S3 are actually simulated by prefixing object names, so they are not equivalent to the directories we normally see in HDFS. For example, when traversing a directory, the S3 implementation searches for objects with the same prefix. This leads to several serious problems:
- Traversing a directory can be very slow. The time complexity of the traversal depends on the total number of files in the directory.
- Renaming directories can also be slow. As with traversing directories, the total number of files is an important factor in performance. Also S3 renaming a file is actually copying it to a new path and then deleting the original file, a process that is also more time consuming.
- Renaming or deleting a directory is not an atomic operation. An operation that takes only O(1) on HDFS becomes O(n) on S3. If the task fails during the operation, it will cause the data to become an intermediate and unknowable state.
Authentication Model
The S3 authentication model is implemented inside the S3 service based on IAM, which is different from the traditional file system. Therefore, when accessing S3 through Hadoop, you will see that the file owner and group dynamically change depending on the identity of the current user, and the permissions for files are 666, while the permissions for directories are 777. This authentication model, which is very different from HDFS, complicates the management of permissions and is not generic enough to be limited to AWS. This authentication model, which is very different from HDFS, complicates permissions management and is not general enough to be used within AWS.
What does JuiceFS bring to the table?
JuiceFS implements a strongly consistent distributed file system based on object storage, maintaining S3's elastic and scalable unlimited capacity and 99.999999999% data durability on the one hand, and solving all the aforementioned S3 "problems" on the other. At the same time, JuiceFS is fully compatible with various components of the Hadoop ecosystem, so it can be seamlessly accessed by users. The authentication model of JuiceFS follows the user/group permission control method similar to HDFS to ensure data security, and it can also interface with Kerberos, Ranger, Sentry and other components commonly used in the Hadoop ecosystem. More importantly, compared to the existing EBS-based storage solution of Globalegrow, the use of JuiceFS will save at least 70% of the monthly storage cost per TB.
What is the performance of this significant reduction in storage costs? We share the test results below.
Test Results
The test environment is a self-built CDH cluster on AWS, with CDH version 5.8.5. The test compute engines include Hive and Spark, and the data formats include plain text and ORC, using two datasets of TPC-DS 20G and 100G size. The comparison storage systems are S3A, HDFS and JuiceFS.
Create table
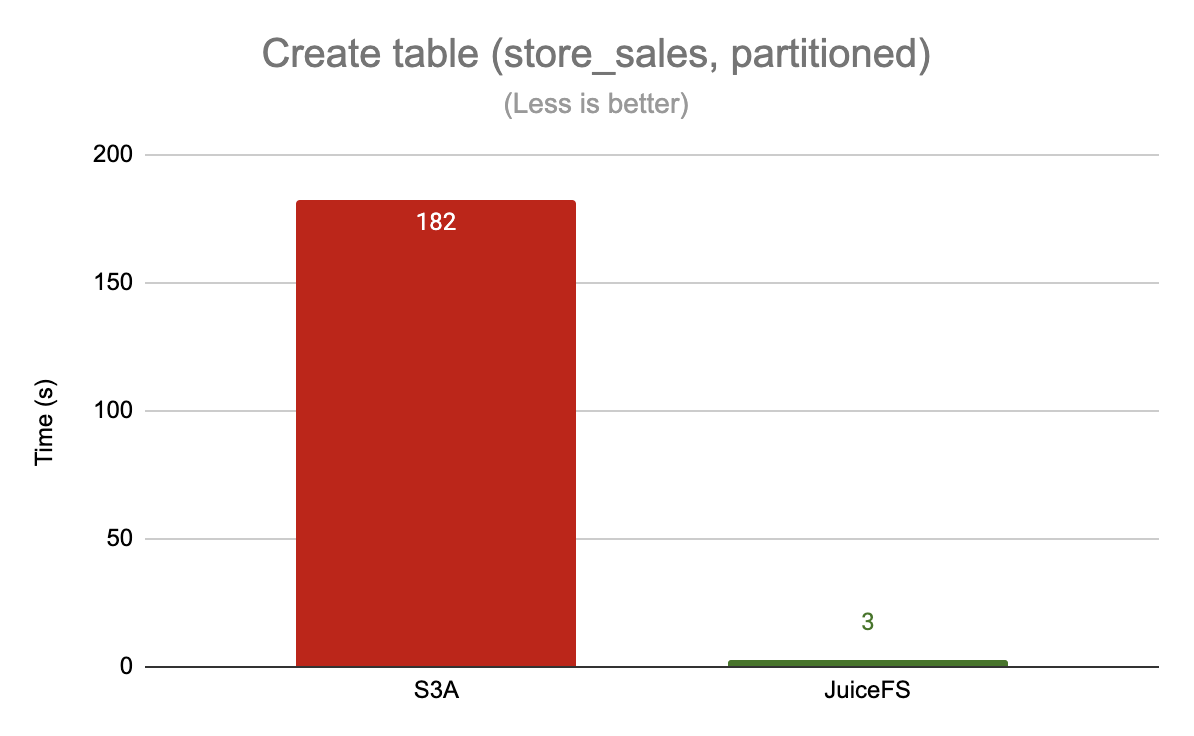
Here is an example of creating the partitioned table store_sales
Repair the table partition
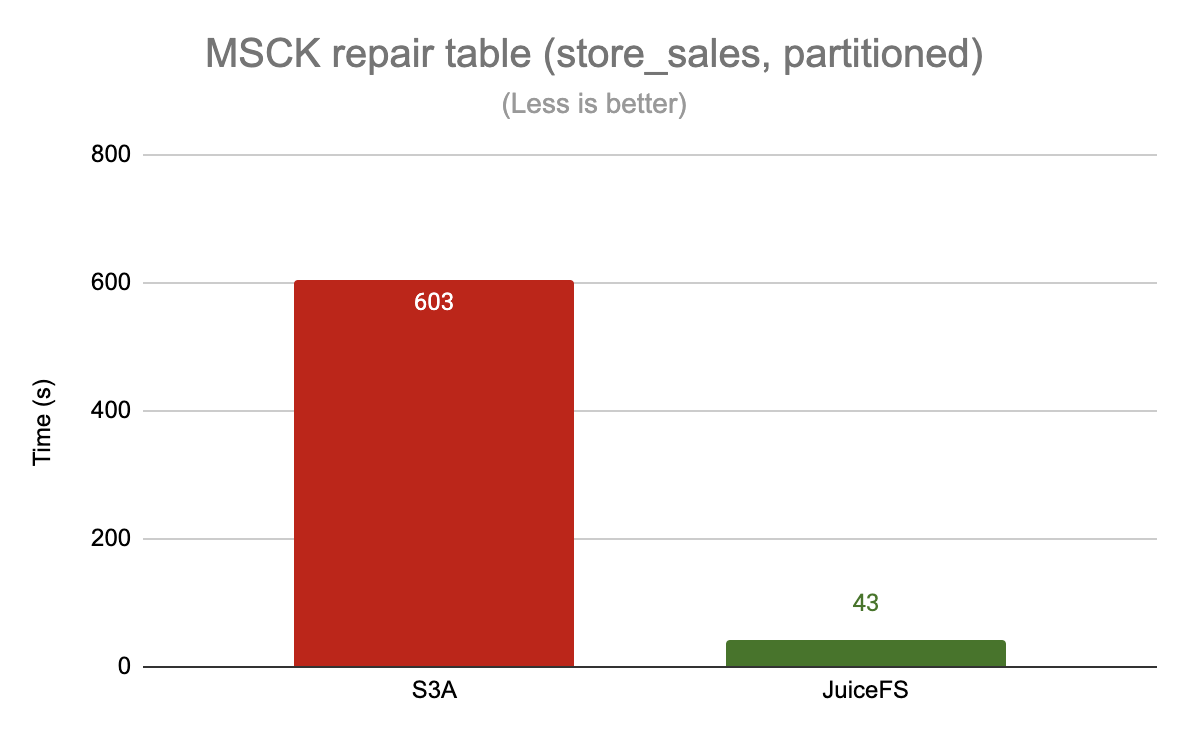
Here is an example of repairing the partition of the table store_sales
Write data
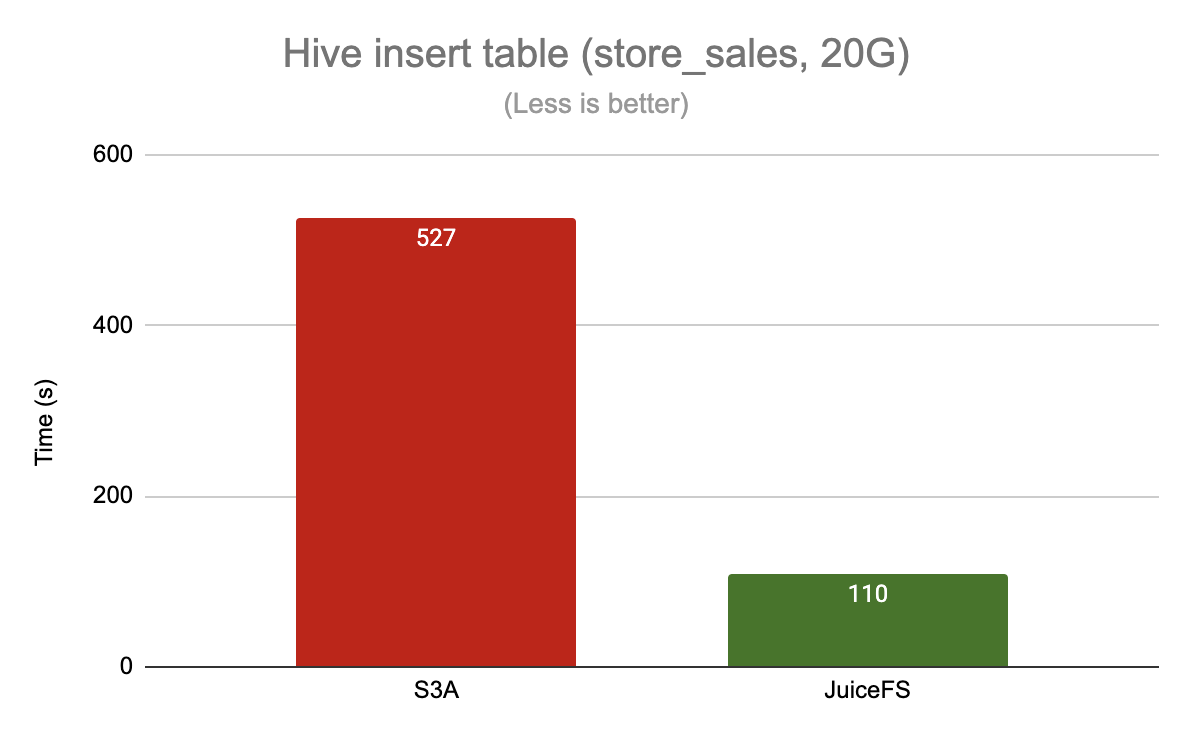
Here is an example of reading the partitioned table store_sales and inserting a temporary table
Read data in plain text format
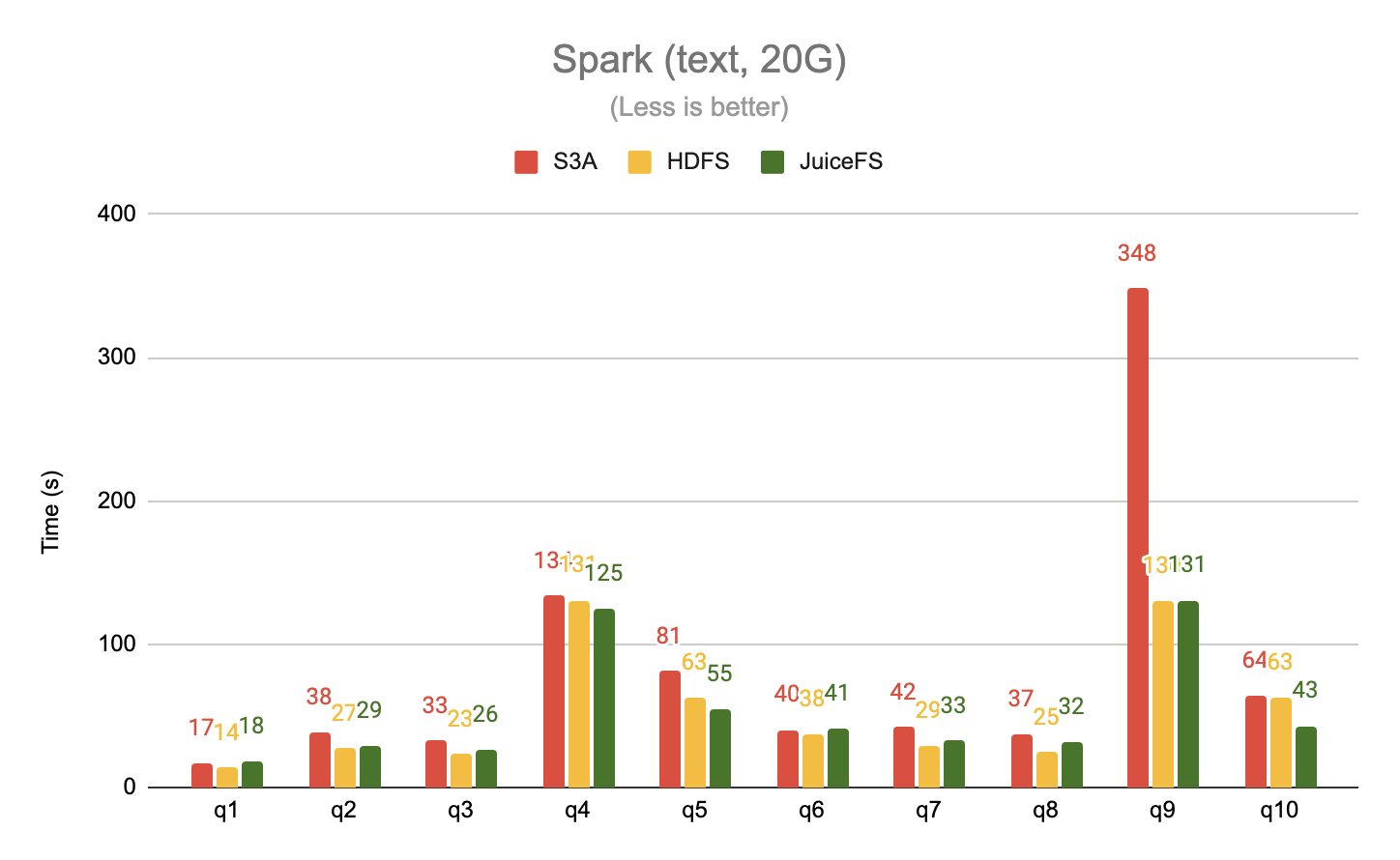
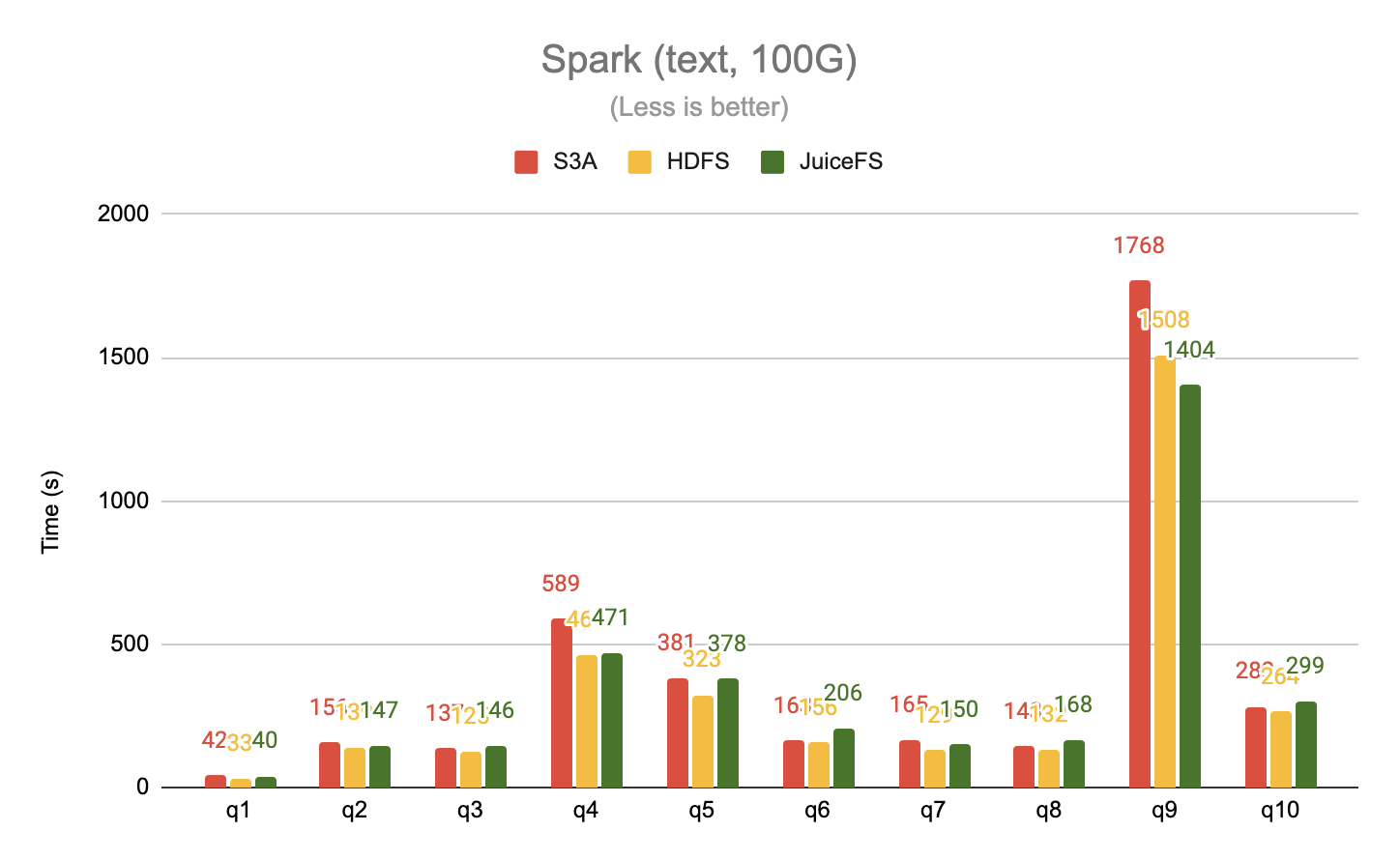
Tested the 20G and 100G datasets separately with Spark, taking the first 10 queries from TPC-DS, in plain text format.
Read data in ORC format
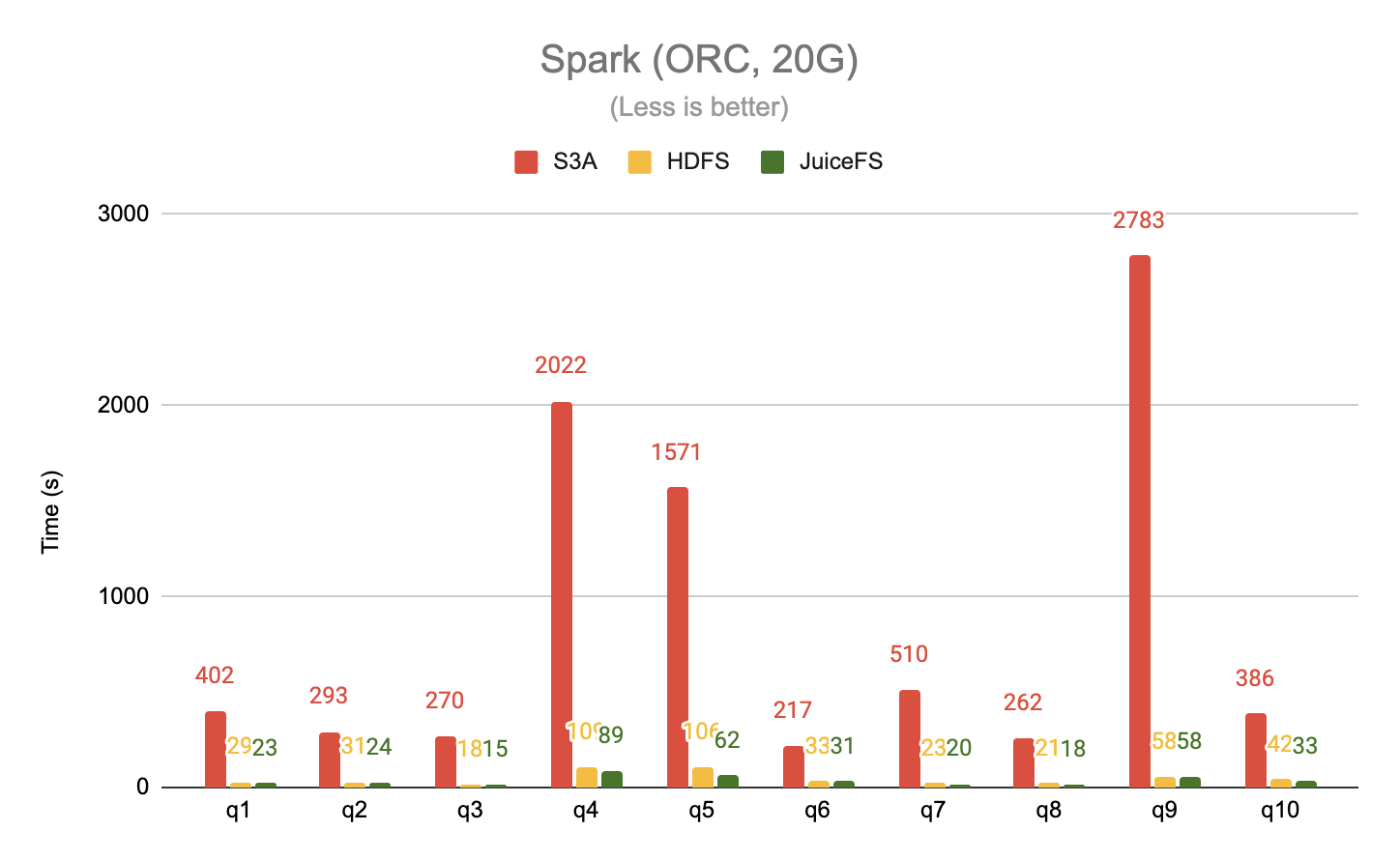
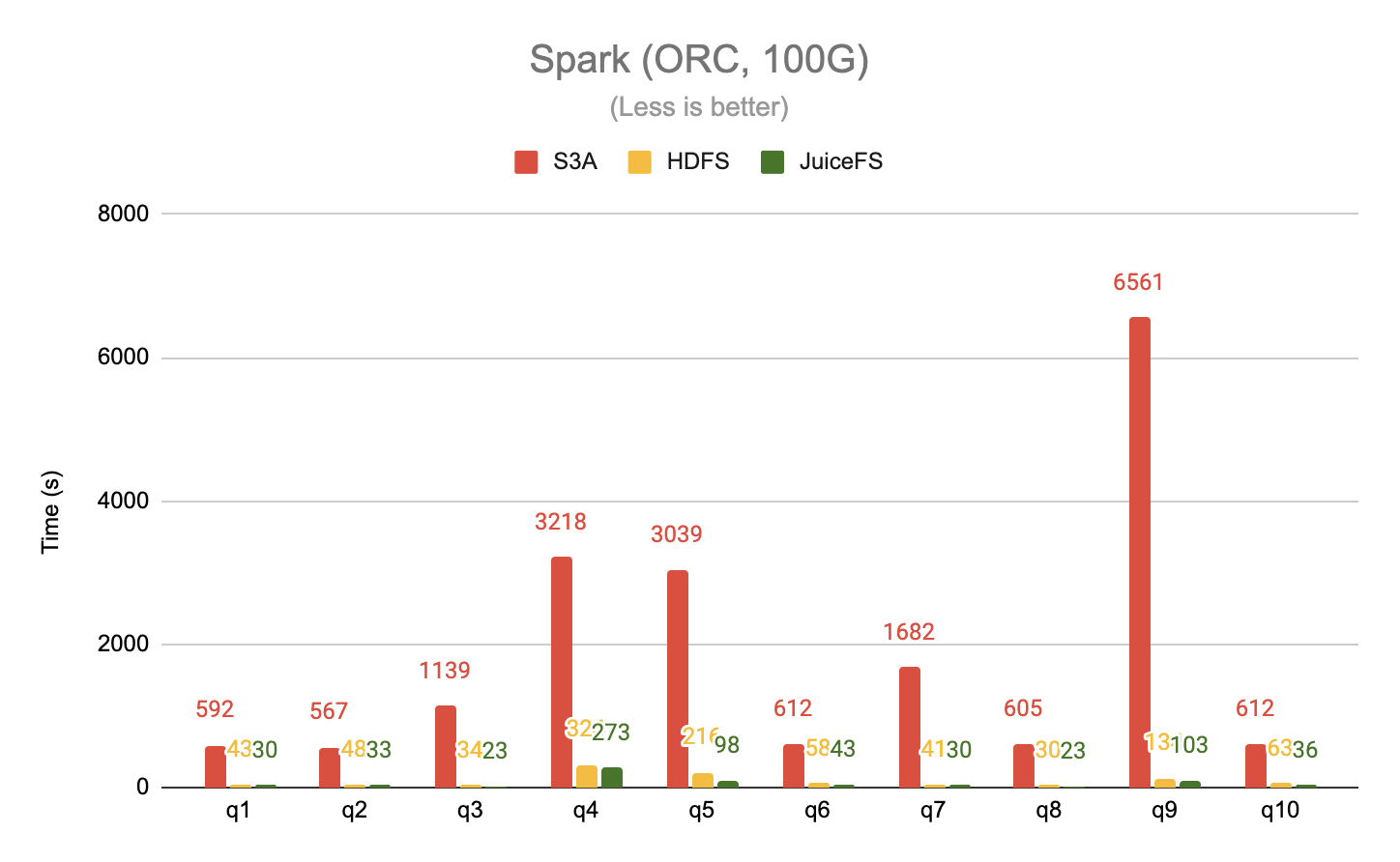
The 20G and 100G datasets were tested separately using Spark, taking the first 10 queries from TPC-DS, with data in ORC format.
Summary of test results
For operations like building tables and repairing table partitions, JuiceFS outperforms S3A by a significant margin, up to 60x, because of its reliance on frequent access to the underlying metadata (e.g., traversing directories).
In write data scenarios, JuiceFS has a 5x performance improvement over S3A. This is important for ETL-type tasks, which typically involve the creation and destruction of multiple temporary tables, a process that generates a lot of metadata operations (e.g. renaming, deleting).
When reading data in a columnar storage format like ORC, which generates a lot of random accesses as opposed to the sequential read mode of plain text files, JuiceFS again outperforms S3A by a significant margin, up to 63x. JuiceFS also delivers up to a 2x performance improvement over HDFS.
Data Migration
Globalegrow's big data platform has accumulated a large amount of data and business over a long period of time, and how to migrate from the existing solution to the new one is also an important factor in evaluating the suitability of the new solution. In this regard, JuiceFS provides a variety of data migration methods.
- Copy the data to JuiceFS. This approach has the best read performance, makes efficient use of local disk cache and distributed cache, and also ensures strong consistency of data. However, it involves data copying, so the migration cost is higher.
- Importing data from S3 via import command. This approach only involves importing metadata and importing the objects on S3 into the directory tree of JuiceFS. This approach does not need to copy data and migration is fast. However, there is no way to guarantee strong consistency, and you cannot take advantage of cache acceleration. 3.
- Fusing existing data with new data via symbolic links. JuiceFS can create symbolic links not only within the file system, but also across the file system. For example, with the command
ln -s hdfs://dir /jfs/hdfs_diryou can create a symbolic link to HDFS. Based on this approach, you can link historical data directly into JuiceFS and then access all other Hadoop file systems through the unified JuiceFS namespace.
Final Choice
After a comprehensive comparison of HDFS, S3 and JuiceFS with the test results and comprehensive cost analysis, Globalegrow decided to replace the self-built HDFS with JuiceFS because of its significant performance and cost advantages over the other two solutions.
First, JuiceFS can achieve a smooth migration from HDFS, which is fully compatible with the upstream computing engine and consistent with the existing permission management system without any degradation in performance. Without such a foundation, the migration of the data platform will be a time-consuming and labor-intensive battle. And with such a foundation, the client completed the business and data migration in less than a month.
Second, in terms of cost, as explained in the section "Pain Points of Self-Built HDFS on Cloud", the cost of self-built HDFS based on EBS alone is about $150/TB/month, while JuiceFS is only 27%. This is not even the TCO cost, which should also include the CPU, memory, and labor cost of operation and management consumed by HDFS, which is at least double the empirical value. JuiceFS customers use a fully managed service without any O&M investment. This results in a cost savings of nearly 90% from a TCO perspective.
Finally, and most importantly. After the storage engine of the big data platform is changed from HDFS to JuiceFS, the whole platform achieves the separation of storage and computation, which is described in the Why disaggregated compute and storage is future? article analyzes the pain points of storage compute coupling in detail, and some practices in the industry. Now JuiceFS, as a fully HDFS-compatible cloud-native file system, is the perfect storage solution for big data platforms built on Hadoop ecosystem. The separation of storage and computation is the basis for the elastic scaling of big data platform, and this step of transformation is also of great significance to the architecture design of Globalegrow data platform. Next, the data team of Globalegrow will go deeper into the research and practice of cluster elastic scaling and mixed workload deployment.