









Disclaimer: This article is translated by DeepL, there is the original post in Chinese.
Author Bio
- Zhenhua Wang, Director of Big Data, Head of Qutoutiao Big Data.
- Haisheng Wang, Big Data Engineer of Qutoutiao, has 10 years experience in the Internet industry, and has worked in eBay, Vipshop and other companies on Big Data development, with rich experience in Big Data implementation.
- Changjian Gao, solution architect of Juicedata, has 10 years of experience in Internet industry, and has worked in Zhihu, Jike, Xiaohongshu, and many other companies.
Background
The big data platform of Qutoutiao currently has an HDFS cluster with nearly 1,000 nodes, carrying the function of storing hot data in recent months, and the scale of daily new data has reached 100 TB. The daily ETL and ad-hoc tasks all rely on this HDFS cluster, which leads to a continuous increase in cluster load. Especially for ad-hoc tasks, because the business model of Qutoutiao requires frequent queries for the latest data, the large number of daily ad-hoc query requests further increases the pressure on the HDFS cluster and also affects the performance of ad-hoc queries, with obvious long-tail phenomenon. The high cluster load also affects the stability of many business components, such as the failure of Flink task checkpoint and the loss of Spark task executor.
Therefore, we need a solution to make ad-hoc queries not rely on the data of HDFS cluster as much as possible, which can reduce the overall pressure of HDFS cluster and ensure the stability of daily ETL tasks on one hand, and reduce the fluctuation of ad-hoc query time consumption and optimize the long-tail phenomenon on the other hand.
Solution Design
The Hadoop SDK of JuiceFS can be seamlessly integrated into Presto to automatically analyze each query in a non-intrusive way without changing any code, and automatically copy the data that needs to be read frequently from HDFS to JuiceFS, so that subsequent ad-hoc queries can directly access the existing cached data on JuiceFS, avoiding requests to HDFS and thus reducing the pressure on the HDFS cluster.
In addition, since the Presto cluster is deployed on Kubernetes, it needs to be able to persist cached data because of the need to scale the cluster elastically. The cost of using standalone HDFS or some caching solution would be very high, so OSS is the ideal choice.
The overall solution design is shown in the figure below. The green part represents the components of JuiceFS, which consists of two main parts: JuiceFS Metadata Service (JuiceFS Cluster in the figure below) and JuiceFS Hadoop SDK (the component associated with Presto worker in the figure below).
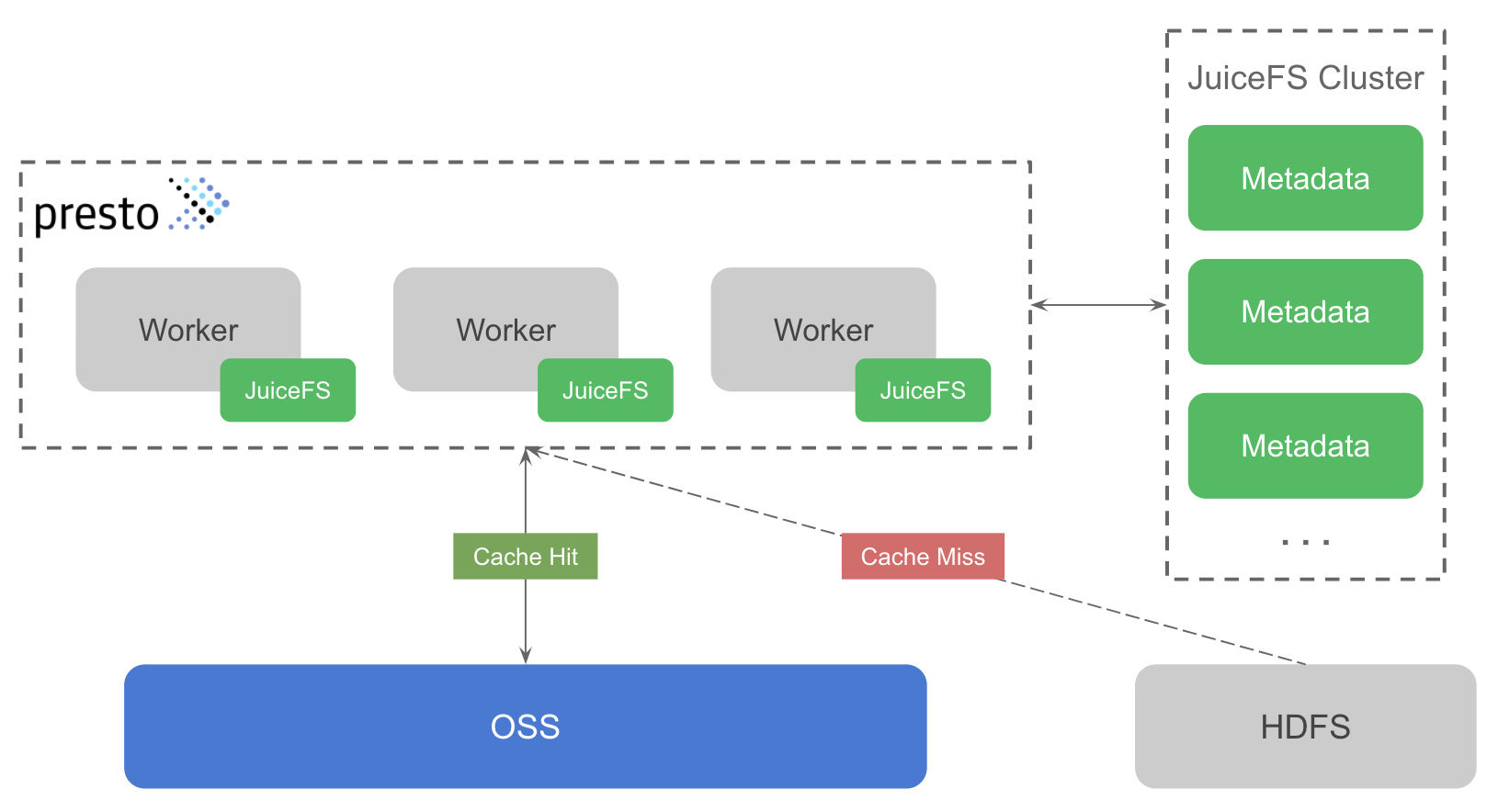
The JuiceFS metadata service is used to manage meta information about all files in the file system, such as file name, directory structure, file size, modification time, etc. The metadata service is a distributed cluster, based on Raft consistency protocol, which ensures strong consistency of metadata while ensuring the availability of the cluster.
The JuiceFS Hadoop SDK (hereafter referred to as SDK) is a client library that can be seamlessly integrated into all Hadoop ecosystem components, in this case into Presto worker. The SDK supports multiple usage models, either replacing HDFS with JuiceFS as the underlying storage for the Big Data platform, or as a caching system for HDFS. This solution uses the latter model, where the SDK supports transparent caching of data from HDFS to JuiceFS without changing the Hive Metastore, so that ad-hoc queries no longer need to request HDFS if they hit the cache. The SDK also ensures data consistency between HDFS and JuiceFS, which means that when the data in HDFS changes, the cached data in JuiceFS can be synchronized and updated without any impact on the business. This is achieved by comparing the modification time (mtime) of the files in HDFS and JuiceFS, because JuiceFS implements a full file system function, so the files have the property of mtime, and the consistency of cached data is ensured by comparing mtime.
To prevent the cache from taking up too much space, the cached data needs to be cleaned up periodically. JuiceFS supports cleaning up data from N days ago based on the access time (atime) of the file. The atime is chosen to ensure that data that is frequently accessed will not be deleted by mistake. Note that many file systems do not update atime in real time to ensure performance. For example, HDFS controls the time interval for updating atime by setting dfs.namenode.accessstime.precision, which by default is as fast as once an hour. There are also certain rules for cache creation, which combine the attributes of file atime, mtime and size to decide whether to cache or not, to avoid caching some unnecessary data.
Test solution
In order to verify the overall effectiveness of the above scheme, including but not limited to the stability, performance, and load of HDFS clusters, we divided the testing process into multiple phases, each phase is responsible for collecting and verifying different metrics, and may also conduct horizontal comparison of data between different phases.
Test results
HDFS Cluster Load
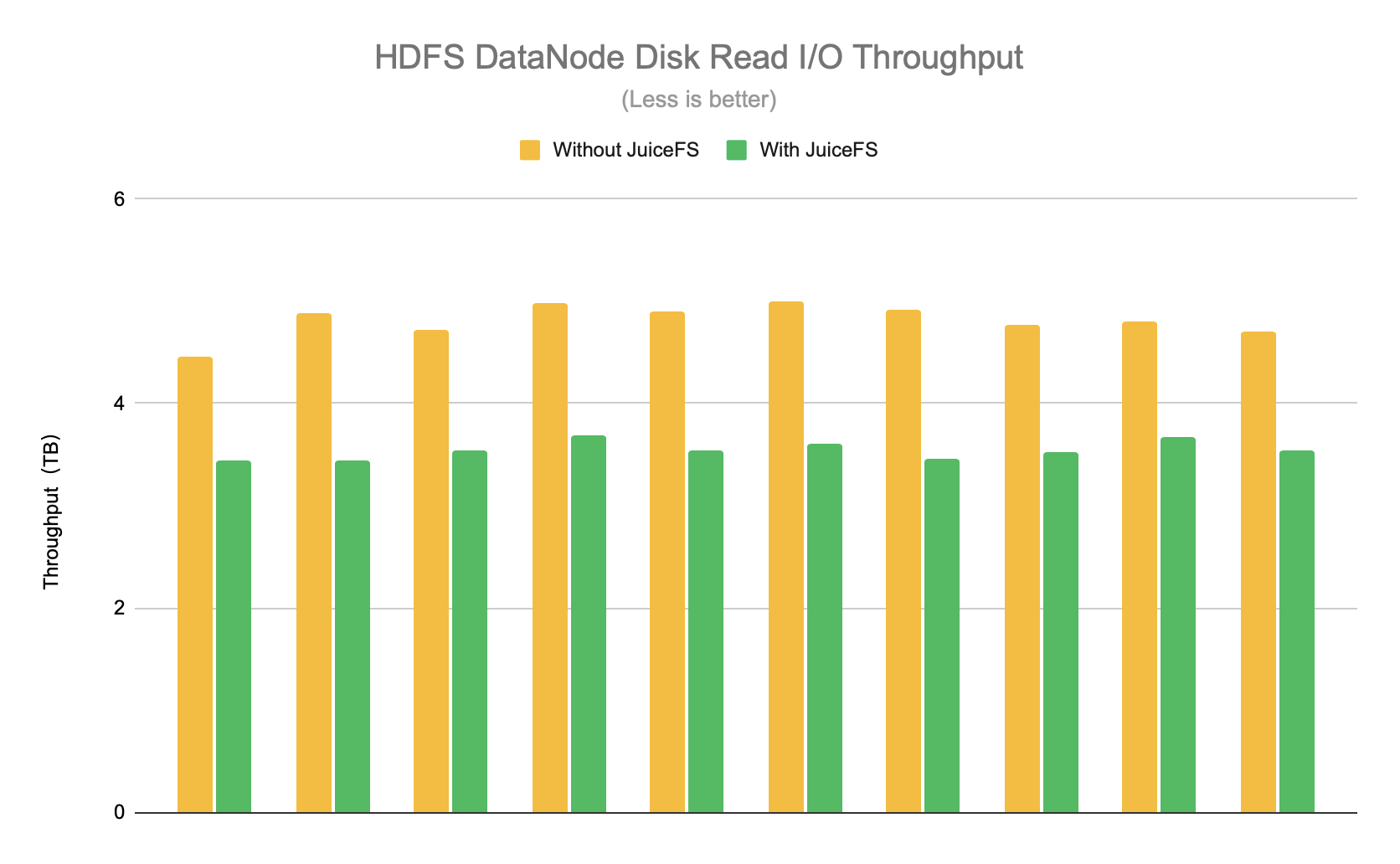
We designed two phases to turn JuiceFS on and off respectively. The average daily disk read I/O throughput of each DataNode in this phase is about 3.5TB. So using JuiceFS reduces the load on the HDFS cluster by about 26%, as shown in the figure below.
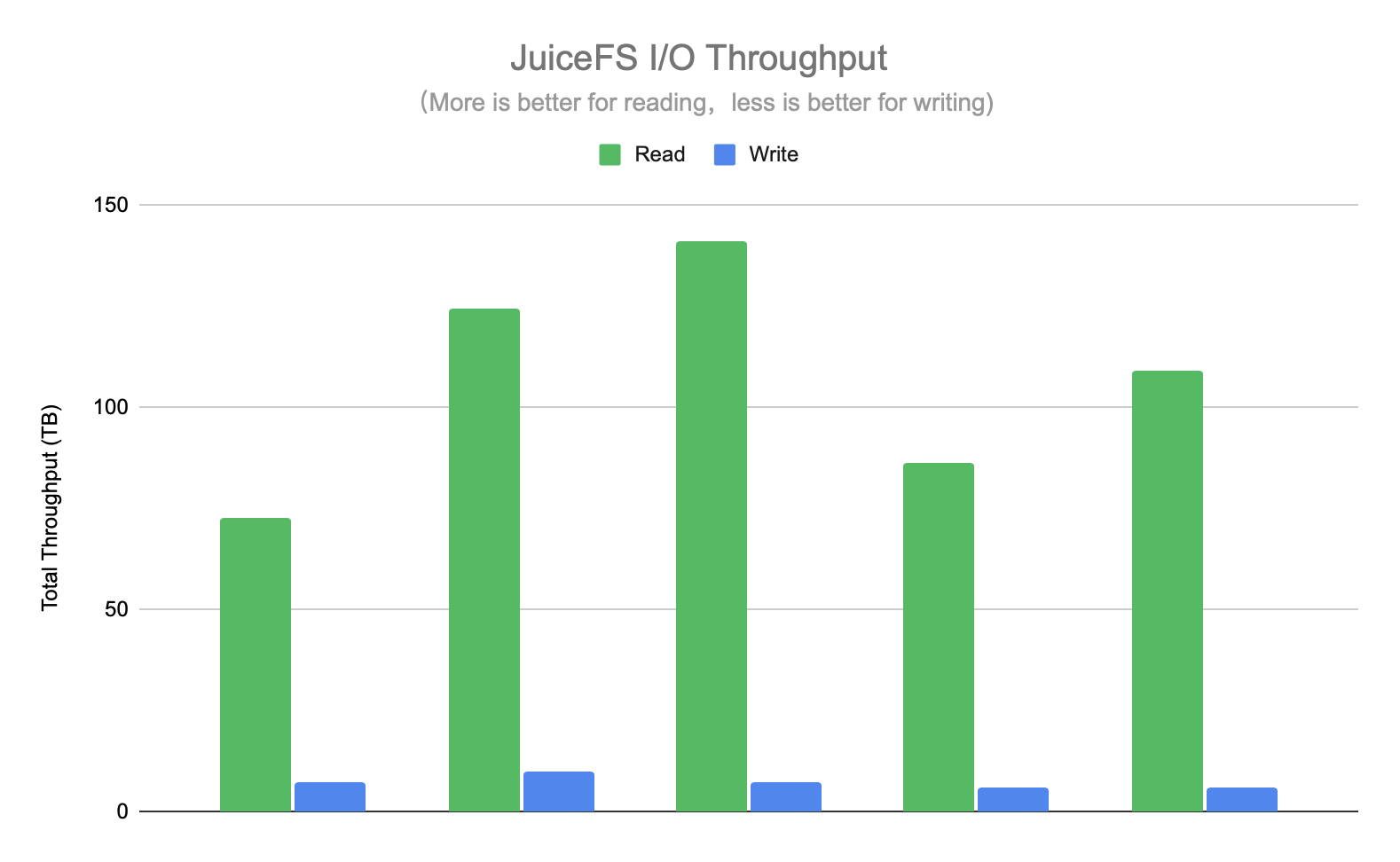
The read I/O of JuiceFS represents the reduced I/O of the HDFS cluster, which would have been directly queried by HDFS if JuiceFS had not been used. JuiceFS write I/O represents the amount of data copied from HDFS, and these requests increase the pressure on HDFS. The larger the read I/O total the better, and the smaller the write I/O total the better. The figure below shows the total read and write I/O for a few days, and you can see that the read I/O is basically 10 times more than the write I/O, which means that the hit rate of JuiceFS data is above 90%, i.e. more than 90% of ad-hoc queries do not need to request HDFS.
Average query time
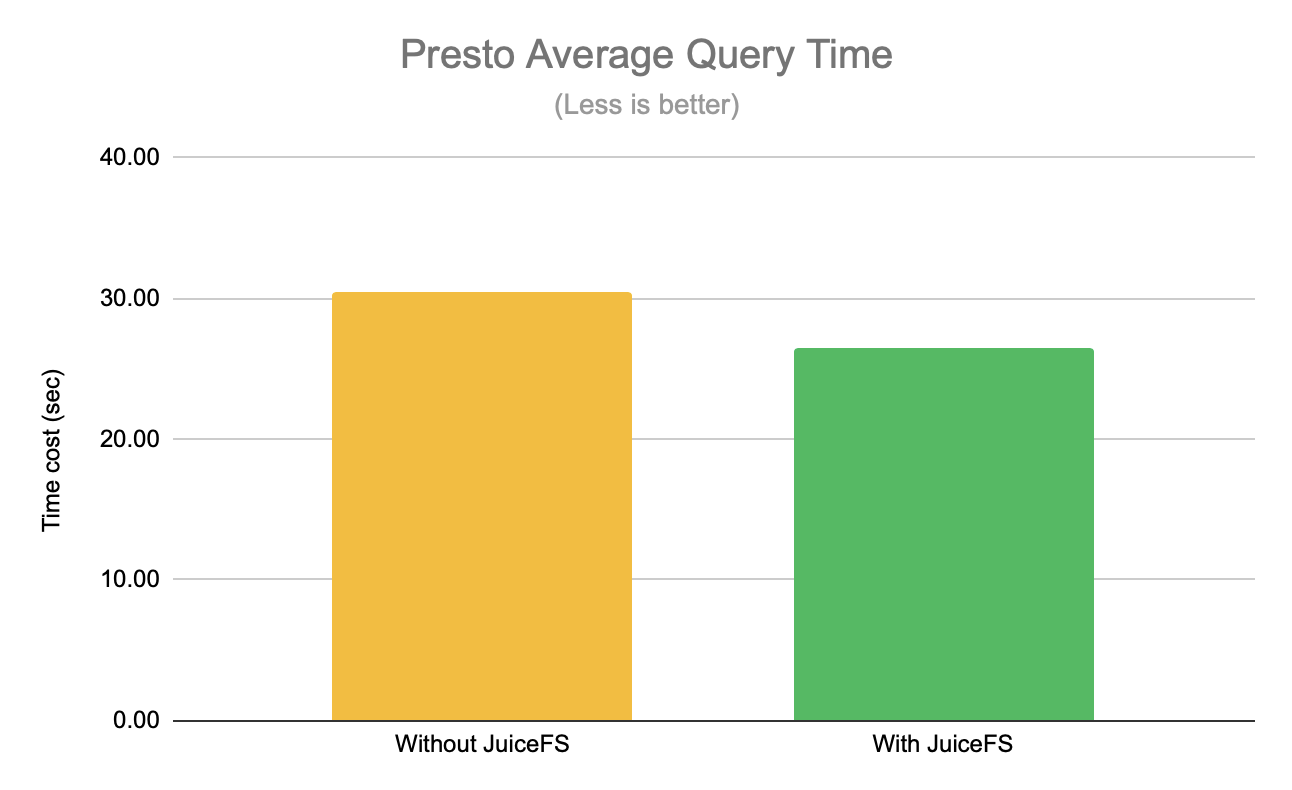
At a certain stage, 50% of the query requests of each traffic are assigned to the two clusters without and with JuiceFS, and the average query time is counted separately. As you can see from the graph below, the average query time is reduced by about 13% with JuiceFS.
Test Summary
The JuiceFS solution dramatically reduces the load on the HDFS cluster in a way that is transparent to the business without changing the business configuration, eliminating the need to request HDFS for over 90% of Presto queries and reducing the average Presto query latency by 13%, exceeding the initial test goals. The long-standing problem of instability of the Big Data component was also resolved.
Notably, the entire testing process was also smooth, with JuiceFS completing basic functional and performance validation of the test environment in just a few days, and quickly moving to the canary testing phase in the production environment. JuiceFS also ran very smoothly in the production environment, withstanding the pressure of full volume of requests, and any problems encountered in the process were quickly fixed.
Future Outlook
Looking ahead, there are more things to try and optimize.
- Further improve the hit rate of JuiceFS cached data and reduce the load on HDFS clusters.
- Increase the space of Presto worker local cache disk to improve the hit rate of local cache and optimize the long-tail problem.
- Spark cluster accesses JuiceFS to cover more ad-hoc query scenarios.
- Smoothly migrate HDFS to JuiceFS to completely separate storage and computation, reduce operation and maintenance costs, and improve resource utilization.



