















NAVER is an Internet company with South Korea's largest search engine. It actively invests in cutting-edge fields such as artificial intelligence (AI) and autonomous driving.
Facing storage challenges in our AI platform, we evaluated various options, including public cloud platforms, Alluxio, and high-performance dedicated storage solutions. Finally, we chose JuiceFS, an open-source cloud-native distributed file system. With JuiceFS, we successfully upgraded our internal storage resources to a high-performance solution suitable for AI workloads.
In this post, I’ll share our AI platform’s storage challenges, why we chose JuiceFS over Alluxio, how we built a storage solution with JuiceFS, and our performance test results.
Storage challenges for our AI platform
AiSuite is an AI platform used by NAVER developers, supporting the development and operations of various NAVER services. Operating on a Kubernetes-based container environment, AiSuite efficiently manages expensive GPU resources. It supports Kubeflow, enabling the construction of AI pipelines that integrate development, training, and serving. Additionally, AiSuite allows the use of in-house data platforms in Kubeflow pipeline components.
The main challenge of operating an AI platform is providing suitable storage for AI workloads.With the widespread use of large language models (LLM), the size of data required to generate effective AI models is increasing. Moreover, for distributed learning, concurrent accesses from multiple nodes is necessary. The platform also needs to easily incorporate various emerging LLM open source projects like Llama 2 and MPT without modifications.
The storage requirements for an AI platform include:
- Ability to handle large-scale data
- High performance for repetitive training
- Support for Kubernetes PersistentVolumes (PVs) using Kubernetes CSI Driver
- POSIX compatibility to seamlessly use various open source projects and libraries
- Support for concurrent accesses for distributed learning and large-scale serving (refer to ReadWriteMany, ReadOnlyMany)
- Ensuring data consistency
- Minimizing operational overhead
Finding a storage solution that met all these requirements was not an easy task. While cloud platforms like AWS EFS and Google Filestore offered services with similar requirements, their costs were much higher compared to object storage services like AWS S3 or Google Cloud Storage. Additionally, since AiSuite was deployed internally at NAVER, external cloud storage services like AWS and GCP were not viable. Specialized storage solutions, such as DDN EXAScaler, could be introduced, but they came with high costs.
Storage solution selection
We explored open-source solutions like GlusterFS and CephFS, but they would impose significant operational complexity.
| Solution | POSIX | RWO | ROX | RWX | Scalability | Caching | Interface | Note |
|---|---|---|---|---|---|---|---|---|
| HDFS | ✕ | - | - | - | ◯ | ✕ | CLI, REST | No support for K8s CSI Driver |
| nubes | △ | - | - | - | ◯ | ✕ | CLI, REST, S3, POSIX | No support for K8s CSI Driver |
| Ceph RBD | ◯ | ◯ | ✕ | ✕ | △ | ✕ | POSIX | No support for multiple clients |
| NFS | ◯ | ◯ | ◯ | ◯ | ✕ | ✕ | POSIX | Has scaling and HA issues |
| Local Path | ◯ | ◯ | ✕ | ✕ | ✕ | ✕ | POSIX | No support for data durability, tricky scheduling |
| Alluxio | △ | ◯ | ◯ | ◯ | ◯ | ◯ | POSIX | Not fully support POSIX, data inconsistency |
Therefore, we initially considered internal storage solutions provided by NAVER. However, it was challenging to find a solution within NAVER that satisfied all the requirements:
- C3 Hadoop Distributed File System (HDFS): Handles large-scale data but doesn't support Kubernetes CSI Driver, making it unsuitable for use as Kubernetes PVs.
- Nubes (object storage): Supports various interfaces but lacks full POSIX API compatibility and Kubernetes CSI Driver support.
- Ceph RBD: Doesn't support
ReadWriteManyorReadOnlyMany, preventing concurrent accesses by multiple Pods. - NFS: Simple to set up but faces scalability and high availability (HA) issues.
- Local Path: Stores data on the disks of Kubernetes nodes, providing fast access but doesn't support concurrent accesses by multiple users.
Why we abandoned Alluxio
To quickly and easily use data processed and stored on HDFS in Hadoop clusters within AiSuite, we introduced Alluxio. However, Alluxio had shortcomings, such as incomplete POSIX compatibility, data inconsistency, and increased operational pressure.
Incomplete POSIX compatibility
While Alluxio could be used as a Kubernetes PV, it lacked support for certain POSIX APIs such as symbolic links, truncation, fallocate, append, and xattr. For example, attempting to perform an append operation after mounting Alluxio at the path /data may fail:
$ cd /data/
$ echo "appended" >> myfile.txt
bash: echo: write error: File exists
Many AI open-source software and libraries assumed that data was located on a local file system. Without support for certain POSIX APIs, normal functioning might be compromised. Therefore, when we used Alluxio, there were instances where data needed to be copied to ephemeral storage before use. This caused inconvenience and inefficiency in AI development.
Data inconsistency
Alluxio functions more like a caching layer on top of existing storage systems rather than an independent storage solution. When changes are made directly to HDFS without passing through Alluxio, inconsistencies between Alluxio and HDFS data may arise.
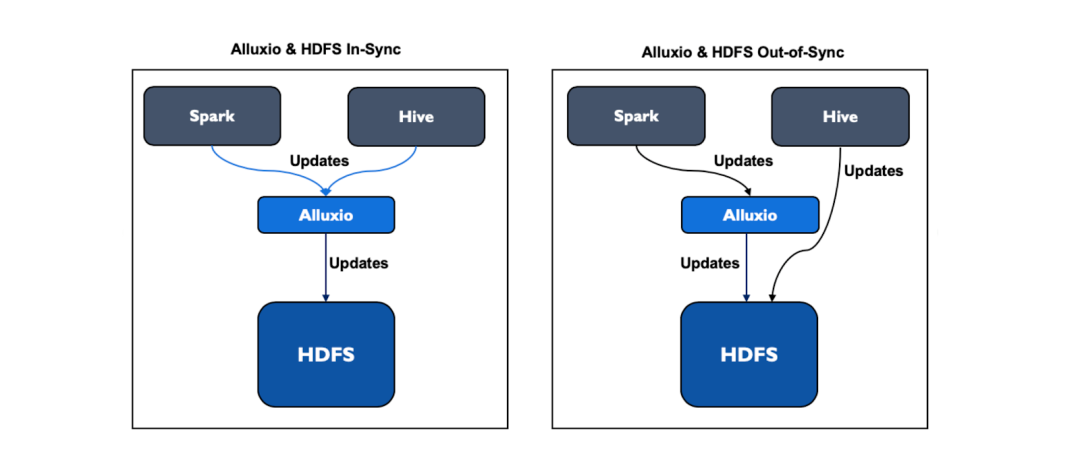
In Alluxio, users can configure the time intervals for syncing with the original storage data. For details, see UFS Metadata Sync. However, if syncing occurs too frequently, it can result in an excessive number of metadata requests to the original storage.
AiSuite operated an Alluxio instance with HDFS as the original storage to interact with Hadoop-based data platforms. Nevertheless, frequent syncing led to an increased load on the NameNode that managed HDFS metadata.
Increased operational pressure
Alluxio requires running a separate cluster consisting of master and worker servers. This increases operational overhead. Moreover, since all users of AiSuite shared this system, any issues could potentially impact all users.
Why we chose JuiceFS
JuiceFS is a distributed file system with a data-metadata separated architecture. File data is stored in object storage like Amazon S3, while metadata can be stored in various databases like Redis, MySQL, TiKV, and SQLite. JuiceFS allows enterprises to leverage existing storage and databases, addressing the challenges posed by traditional storage and overcoming the limitations of object storage.
This section will share why we adopted JuiceFS, its architecture, key features, and how it addressed our storage requirements for AI platforms.
JuiceFS architecture
The figure below shows the JuiceFS architecture:
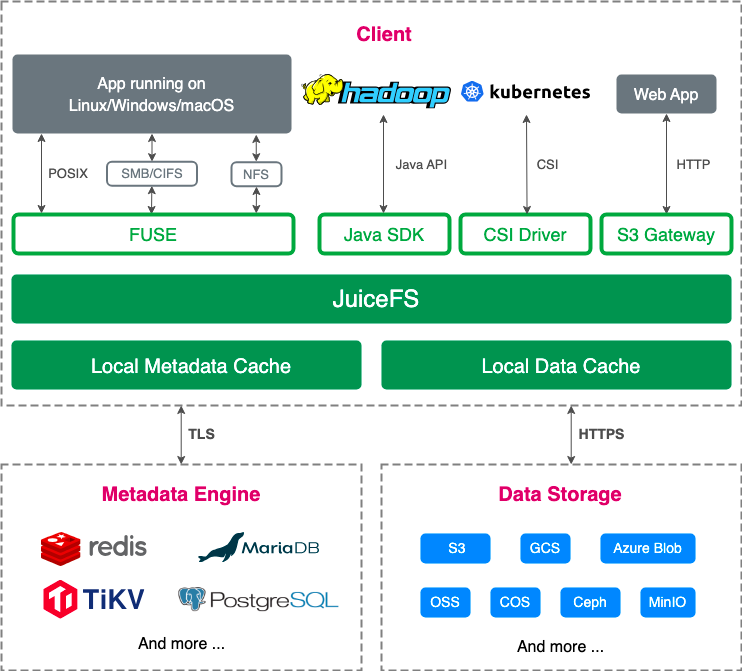
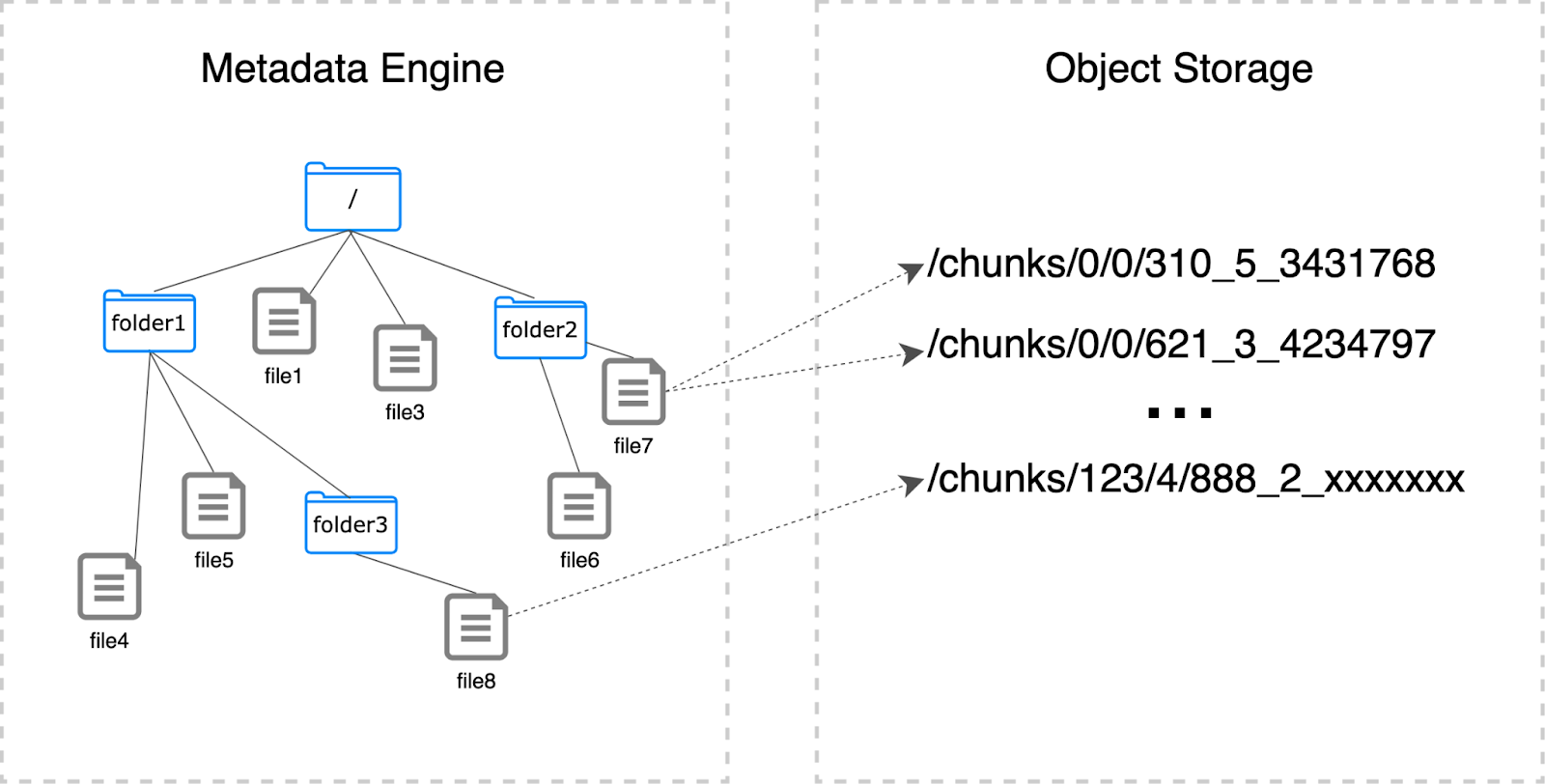
A JuiceFS file system consists of three components:
- The metadata engine: It manages file metadata like file names and size and supports various databases such as Redis, TiKV, MySQL/MariaDB, and PostgreSQL. This offers flexibility in choosing the backend.
- Data storage: It’s where actual data is stored, supporting a variety of storage solutions like S3, OpenStack Swift, Ceph, MinIO, and HDFS.
- The JuiceFS client: The client interacts with the metadata engine and data storage, performing file I/O operations. It supports multiple interfaces, making it adaptable to diverse environments.
JuiceFS allows for the use of existing and familiar storage and databases. This makes it suitable for storage in Kubernetes environments without the need to build and operate a new storage system. With a storage ready for data storage and a database serving as the metadata engine, no additional server operation is required; only a client is necessary.
For example, with S3 object storage and Redis in place, JuiceFS can be employed to create a high-performance storage solution with various features. This is why JuiceFS captured our interest. Using storage and databases supported internally by NAVER, we could easily establish a storage system.
JuiceFS features
JuiceFS offers a range of features that make it suitable for AI platforms and other storage requirements:
- POSIX compatibility: Functions like a local file system.
- HDFS compatibility: Supports the HDFS API for integration with data processing frameworks like Spark and Hive.
- S3 compatibility: Can be accessed through an S3-compatible interface using the S3 gateway.
- Cloud-native: Supports CSI Driver for Kubernetes PV usage.
- Distributed: Enables concurrent accesses across multiple servers.
- Strong consistency: Committed changes are immediately valid on all servers.
- Excellent performance: Refer to the performance benchmark for detailed insights.
- Data security: Supports data encryption.
- File locking: Supports BSD locking (flock) and POSIX locking (fcntl).
- Data compression: Supports LZ4 and Zstandard for saving storage space.
Storage principles
JuiceFS introduces the following concepts to handle files, aiming to address the data physical dispersion in distributed storage and the difficulty of modifying objects in object storage.
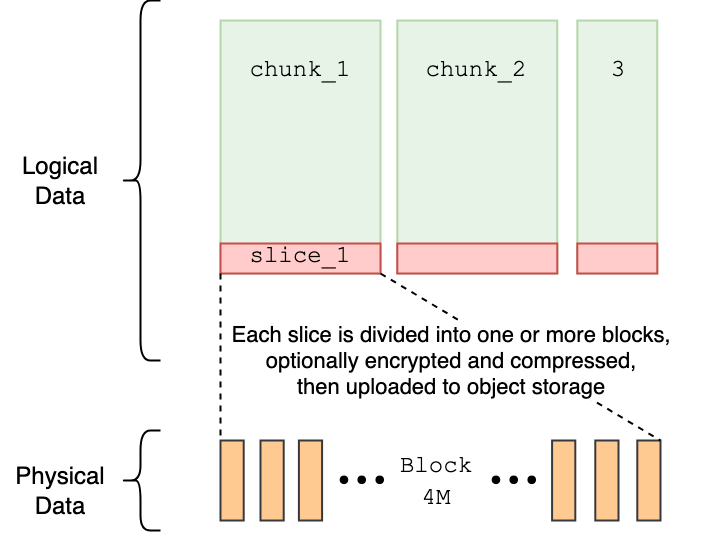
- Chunk: Each file is divided into chunks of 64 MB. Large files can be read or written in parallel based on the offset, which is highly efficient for handling massive-scale data.
- Slice: Each chunk consists of one or multiple slices. A new slice is created with each write, and they can overlap with other slices of the same chunk. When reading a chunk, the latest slice is prioritized. To prevent a performance decline due to an excessive number of slices, they are periodically merged into one. This flexibility in modifying files addresses the limitations of object storage in terms of data modification.
- Block: In the actual storage, slices are divided into blocks with a base size of 4 MB (up to a maximum of 16 MB) for storage. Chunks and slices are primarily logical concepts, while the visible data unit in actual storage is the block. By splitting into smaller blocks and processing them in parallel, JuiceFS compensates for the remote and slow nature of distributed object storage.
The metadata engine manages metadata such as file names and file sizes. Additionally, it includes mapping information between files and the actual stored data.
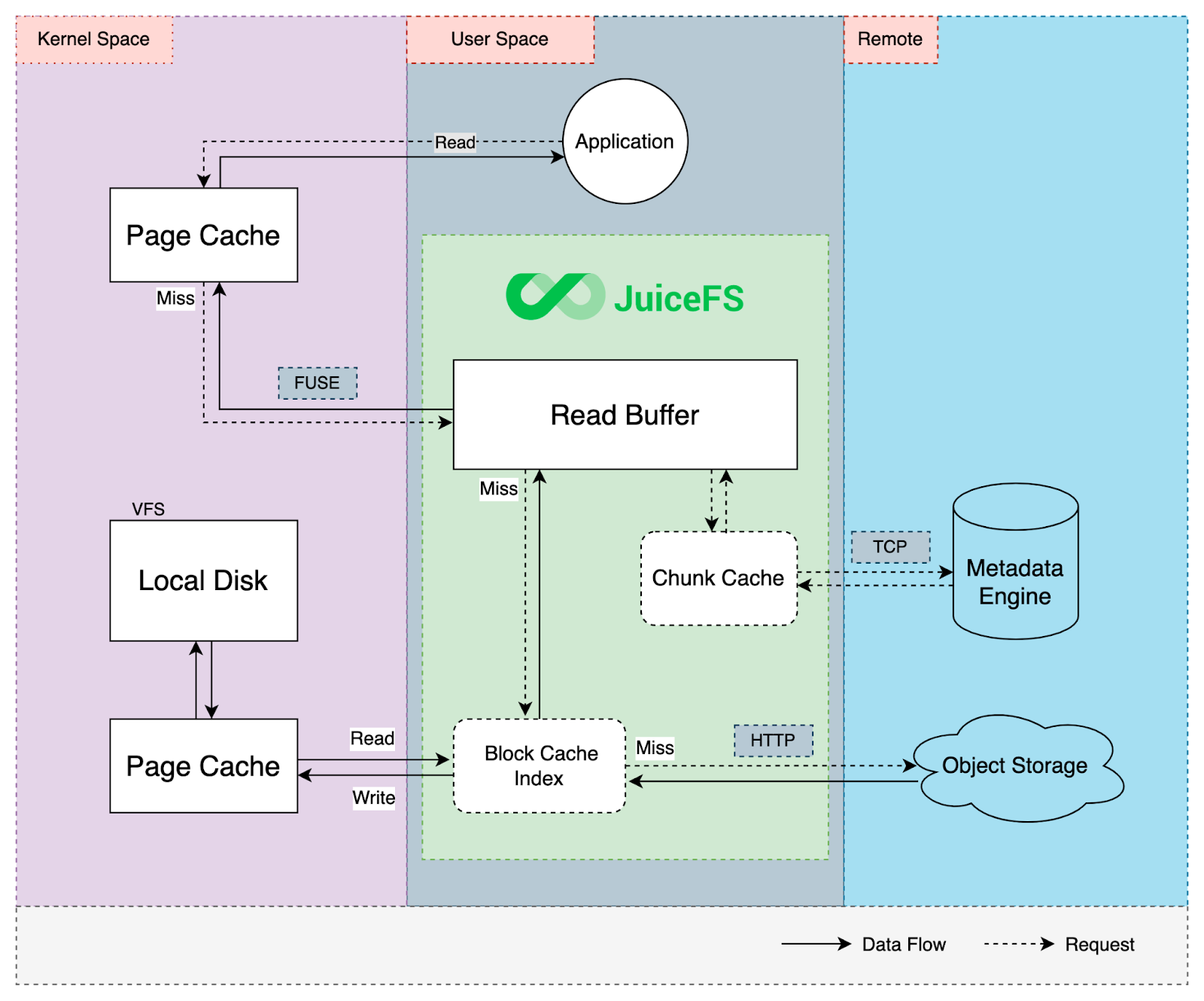
Cache
JuiceFS incorporates multi-level caching to improve performance. When reading requests, it first attempts to retrieve data from kernel page cache, client process cache, and local disk cache. If these caches miss, it fetches the required data from remote storage. The retrieved data is then asynchronously stored in various cache levels for faster future access.
Alluxio vs. JuiceFS
Because Alluxio did not meet our storage requirements, we began to explore JuiceFS. A comparison table between Alluxio and JuiceFS highlights JuiceFS' advantages, including support for multiple interfaces, caching for performance improvement, and specific features that address the shortcomings observed with Alluxio.
| Features | Alluxio | JuiceFS |
|---|---|---|
| Storage format | Object | Block |
| Cache granularity | 64 MiB | 4 MiB |
| Multi-tier cache | ✓ | ✓ |
| Hadoop-compatible | ✓ | ✓ |
| S3-compatible | ✓ | ✓ |
| Kubernetes CSI Driver | ✓ | ✓ |
| Hadoop data locality | ✓ | ✓ |
| Fully POSIX-compatible | ✕ | ✓ |
| Atomic metadata operation | ✕ | ✓ |
| Consistency | ✕ | ✓ |
| Data compression | ✕ | ✓ |
| Data encryption | ✕ | ✓ |
| Zero-effort operation | ✕ | ✓ |
| Language | Java | Go |
| Open source license | Apache License 2.0 | Apache License 2.0 |
| Open source date | 2014 | 2021.1 |
JuiceFS and Alluxio both support various interfaces and use caching to enhance performance. Compared to Alluxio, JuiceFS has several advantages, making it a preferred choice.
POSIX compatibility
While Alluxio offers limited support for certain POSIX APIs, JuiceFS provides full support for the POSIX standard, allowing it to be used like a local file system. This means that various AI open-source tools and libraries can be used without modifying the training data and code stored in JuiceFS.
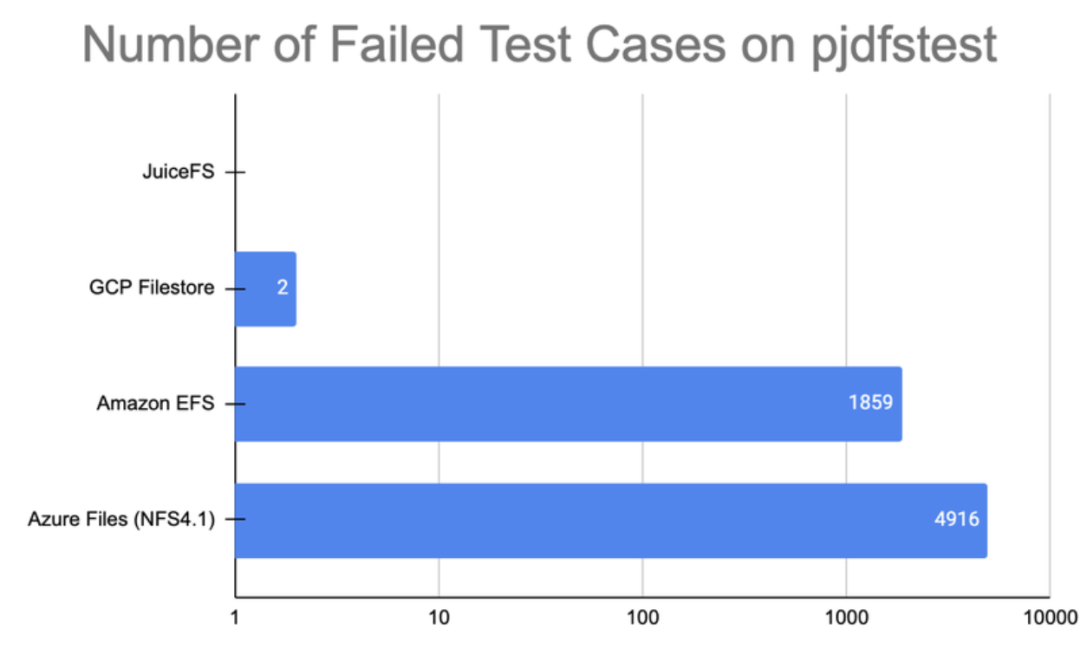
Below are the test results of POSIX compatibility using pjdfstest. Compared to AWS EFS and Google Filestore, JuiceFS performs better in supporting POSIX.
Strong consistency
Alluxio caches the original storage, while JuiceFS is an independent storage system. In JuiceFS, metadata is managed by the metadata engine and is not dependent on external systems. Data storage is only used for storing block data. Therefore, JuiceFS does not encounter synchronization issues with the original storage, as is the case with Alluxio.
Reduced operational burden
Alluxio requires running and maintaining master and worker servers, adding a certain operational burden. Moreover, since Alluxio is shared by all users, any faults may impact all users.
JuiceFS, on the other hand, can directly use existing familiar storage and databases as metadata engines and data storage, requiring only the JuiceFS client to run without deploying separate servers. Additionally, each user can independently configure their metadata engine and data storage, avoiding mutual interference.
Building a storage solution with JuiceFS
To use JuiceFS, you need to prepare a database serving as the metadata engine and an object storage for the actual data. As mentioned earlier, JuiceFS supports various databases and object storage solutions. To ease the operational burden, we use the existing platform in NAVER.
AiSuite employs JuiceFS in its in-house platform as follows:
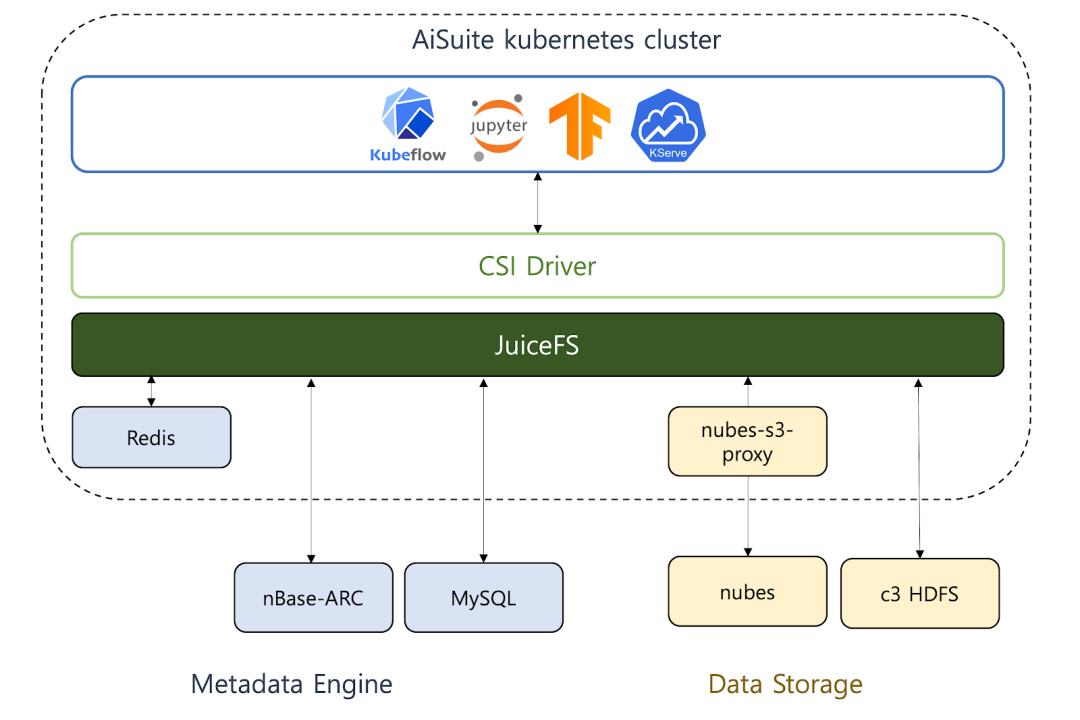
The metadata engine
At NAVER, we can create a metadata engine using the nBase-ARC Redis service or with MySQL support. For development and testing purposes, we can directly install Redis, PostgreSQL, and other options using Helm charts.
JuiceFS automatically backs up metadata to the data storage every hour, and the backup frequency is configurable. Therefore, even in the event of data loss in the metadata engine, recovery is possible. However, due to the set backup cycle, there is still a potential for partial data loss. For details, see Metadata Backup and Recovery.
Data storage
We can store large-scale data using NAVER's internal HDFS or nubes object storage. These resources provide large-capacity, stable data storage.
nubes
nubes is NAVER's object storage. While JuiceFS itself does not directly support nubes, access can be achieved by using nubes-s3-proxy with the MinIO interface.
HDFS
HDFS is the default storage system supported by JuiceFS. However, to apply Kerberos in a large-scale, multi-tenant HDFS, the following improvements are required:
In NAVER's HDFS, Kerberos authentication is applied. Therefore, when JuiceFS uses HDFS, Kerberos authentication is necessary. The original version of JuiceFS set the credential cache for HDFS authentication using the KRB5CCNAME environment variable. However, this approach expired after a certain period, rendering it invalid. To address this, we enhanced JuiceFS to allow setting the keytab files in the KRB5KEYTAB and KRB5PRINCIPAL environment variables instead of using the credential cache.
-
Support for base64-encoded keytab files AiSuite is a multi-tenant Kubernetes cluster shared by multiple users, aiming to enable each user to run JuiceFS with their preferred metadata engine and data storage. Users need to write their Kubernetes Secrets to set the paths and authentication information for accessing the metadata engine and data storage. However,
KRB5KEYTABis just a file path, and users couldn't pass their actual keytab files. To address this, we improved JuiceFS to allow setting the base64-encoded string of keytab files in theKRB5KEYTAB_BASE64environment variable. -
Support for user-specified HDFS paths NAVER's HDFS is shared by multiple users, with each having permissions only on their assigned HDFS paths. However, the original version of JuiceFS couldn't specify the HDFS path for data storage, and data had to be stored under the root directory, causing users to encounter permission issues. To solve this problem, we enhanced JuiceFS to allow users to set their HDFS paths for data storage.
-
Support for HDFS path hdfs://nameservice NAVER's HDFS adopts HDFS Federation for large-scale operations, consisting of multiple NameNodes and namespaces. The original JuiceFS required directly specifying the NameNode path, such as
nn1.example.com:8020, which was inconvenient for users to confirm and set. To address this issue, we improved JuiceFS to allow setting the namespace, such ashdfs://nameservice.
CSI Driver
AiSuite operates as a multi-tenant Kubernetes cluster, where each user is distinguished by a Kubernetes namespace. Sharing JuiceFS among users can lead to mutual interference, resulting in decreased stability and operational challenges. Therefore, the goal was to enable users to independently provision their metadata engines and data storage for individual JuiceFS usage. Additionally, to reduce operational burdens and provide convenience to users, it is essential to support dynamic volume provisioning, allowing users to define PersistentVolumeClaims (PVC) without administrative intervention.
To achieve this, we made the following enhancements:
Users need to write Secrets to set paths, authentication information, and other configurations for their respective metadata engines and data storage. These Secrets must be referenced in the StorageClass to be used in dynamic volume provisioning.
However, the existing JuiceFS CSI Driver allowed only one fixed Secret to be configured in the StorageClass. To address this limitation, we made improvements to allow users to reference Secrets created by PVCs using variables like ${pvc.name}, ${pvc.namespace}, and ${pvc.annotations['<annotation>']}.
User Secrets are used not only during PVC creation but also when deleting PVCs to remove JuiceFS data. If the associated Secret is removed before deleting the PVC, JuiceFS data may remain uncleared. To prevent this issue, we added a finalizer to ensure that the associated Secret is not removed until the PVC is deleted. By setting secretFinalizer to "true" in the StorageClass parameters, this finalizer is enabled.
- Support for setting
mountOptionsreferencing PVC metadata AiSuite encompasses various AI workloads such as AI training, serving, and data processing. To achieve optimal performance tailored to specific tasks, individual JuiceFS configurations are required. For example, when using read-only data for AI training, adding the--open-cachesetting can enhance read performance. For details, see Metadata cache in client memory.
The original version of JuiceFS applied only fixed configurations in StorageClass. To address this issue, we made improvements to enable users to reference PVCs they created, such as ${.PVC.namespace}, ${.PVC.name}, ${.PVC.labels.foo}, and ${.PVC.annotations.bar}.
Applying JuiceFS
To support JuiceFS in Kubernetes, administrators deploy JuiceFS CSI Driver, while users define their respective Secrets and PVCs. Below, we'll explain how this is deployed and provided in the multi-tenant Kubernetes environment of AiSuite, with detailed examples.
Deployment
After JuiceFS CSI Driver is installed, it becomes available for use through standard Kubernetes volume usage practices. It supports installation via Helm or kubectl. For details, see JuiceFS CSI Driver Installation guide. Deployment requires Kubernetes administrator privileges.
To enable each user to use their own metadata engine and data storage, we configured StorageClass as follows:
apiVersion: storage.k8s.io/v1
kind: StorageClass
metadata:
name: juicefs
provisioner: csi.juicefs.com
parameters:
# Configure to allow users to reference Secrets they individually created.
# Users need to set the Secret name in the 'csi.juicefs.com/secret-name' annotation of PVC.
csi.storage.k8s.io/provisioner-secret-name: ${pvc.annotations['csi.juicefs.com/secret-name']}
csi.storage.k8s.io/provisioner-secret-namespace: ${pvc.namespace}
csi.storage.k8s.io/node-publish-secret-name: ${pvc.annotations['csi.juicefs.com/secret-name']}
csi.storage.k8s.io/node-publish-secret-namespace: ${pvc.namespace}
csi.storage.k8s.io/controller-expand-secret-name: ${pvc.annotations['csi.juicefs.com/secret-name']}
csi.storage.k8s.io/controller-expand-secret-namespace: ${pvc.namespace}
juicefs/clean-cache: "true"
# Enbale secretFinalizer to prevent arbitrary deletion of user-defined Secrets.
secretFinalizer: "true"
# Set the pathPattern to specify the desired mount path.
# Users can set the desired path in the 'csi.juicefs.com/subdir' annotation of PVC.
pathPattern: "${.PVC.annotations.csi.juicefs.com/subdir}"
allowVolumeExpansion: true
reclaimPolicy: Delete
mountOptions:
# Allow users to set their own options as needed.
# Users can set the required JuiceFS options in 'csi.juicefs.com/additional-mount-options' annotation of PVC.
- ${.PVC.annotations.csi.juicefs.com/additional-mount-options}
Usage
Users need to create Secrets for their own metadata engine and data storage, including paths and authentication information.
apiVersion: v1
kind: Secret
metadata:
name: myjfs
type: Opaque
stringData:
# JuiceFS file system name
name: myjfs
# MINIO_ROOT_USER
access-key: user
# MINIO_ROOT_PASSWORD
secret-key: password
# The path for the metadata engine Redis
metaurl: redis://:@redis.user1.svc.cluster.local:6379/0
# minio
storage: minio
# bucket1
bucket: http://nubes-s3-proxy.user1.svc.cluster.local:10000/bucket1
# https://juicefs.com/docs/community/command_reference/#format
format-options: trash-days=0,block-size=16384
Define a PVC and set the following annotations:
csi.juicefs.com/secret-name: Specify the referenced Secret name.csi.juicefs.com/subdir: If it's a new volume, specify the PVC name. If you want to mount an existing JuiceFS path, you can specify the desired path.csi.juicefs.com/additional-mount-options: Add JuiceFS mount options tailored to the workload. For details, see the mount document.
apiVersion: v1
kind: PersistentVolumeClaim
metadata:
name: myjfs
annotations:
csi.juicefs.com/secret-name: myjfs # The Secret name created earlier
csi.juicefs.com/subdir: myjfs # Path in the JuiceFS file system
csi.juicefs.com/additional-mount-options: "writeback,upload-delay=1m" # Add JuiceFS settings if necessary.
spec:
accessModes:
- ReadWriteMany
resources:
requests:
storage: 100Gi
storageClassName: juicefs
After creating Secrets and PVCs, users can use them just like normal volumes. The example below demonstrates how to mount the myjfs PVC to /data in a Pod:
apiVersion: v1
kind: Pod
metadata:
name: example
spec:
containers:
- name: app
...
volumeMounts:
- mountPath: /data
name: juicefs-pv
volumes:
- name: juicefs-pv
persistentVolumeClaim:
claimName: myjfs
Performance tests
Based on JuiceFS performance benchmark tests, its performance was superior to Amazon EFS and s3fs:
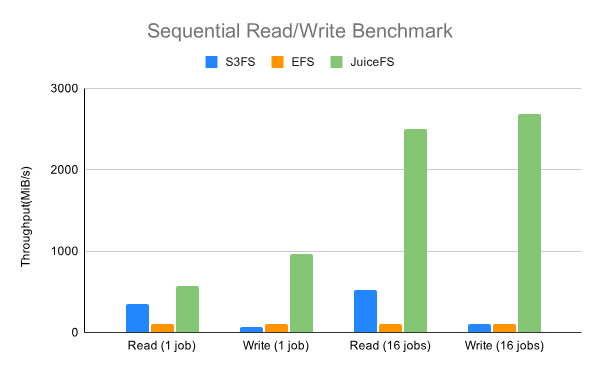
However, we needed to verify the performance when using nubes object storage and HDFS as data storage, instead of EFS or s3fs.
JuiceFS performance varies depending on the chosen data storage, and we must consider the performance impact caused by JuiceFS FUSE, which may lead to degradation as FUSE operates through userspace.
The purpose of the tests was to verify whether there was any performance degradation compared to direct data storage usage. If there was minimal difference, JuiceFS could provide various features such as POSIX compatibility and concurrent accesses without performance degradation.
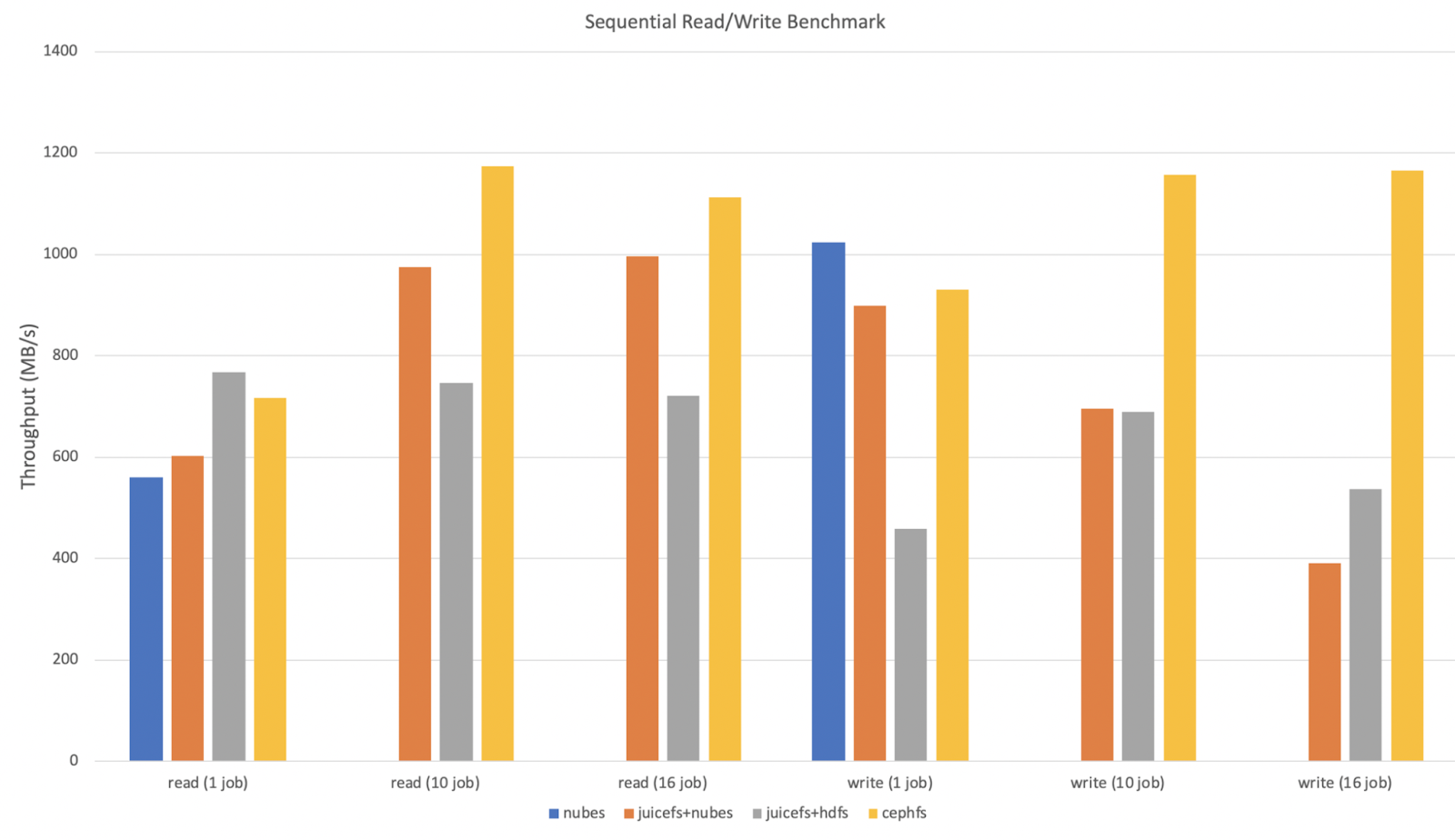
Sequential reads/writes
Referring to the Fio Standalone Performance Test, we conducted the following tests:
- Redis was used as the metadata engine.
- Tests were performed on a single node using fio by adjusting the
--numjobsoption. - The maximum network bandwidth of a single node was 1200 MB/s in this test.
- Since object storage fundamentally did not support POSIX, only read (1 job) and write (1 job) items optimized for nubes object storage performance were measured.
- The block size in JuiceFS settings was configured to 16 MB, and other options used default values.
- We did not use JuiceFS caching and only tested reading and writing new data.
- Alluxio was excluded from the test as it failed with errors like "fio: posix_fallocate fails: Not supported" during fio execution.
The results are as follows:
-
For sequential reads, the performance of JuiceFS+nubes and JuiceFS+HDFS was better than nubes alone, and increased proportionally with the number of concurrent executions. This advantage was probably due to the smaller block size that favored concurrent reads.
-
For sequential writes, the performance of JuiceFS+nubes and JuiceFS+HDFS was similar to or lower than nubes, and decreased as the number of concurrent executions increased. This degradation may be attributed to the burden of multiple slices.
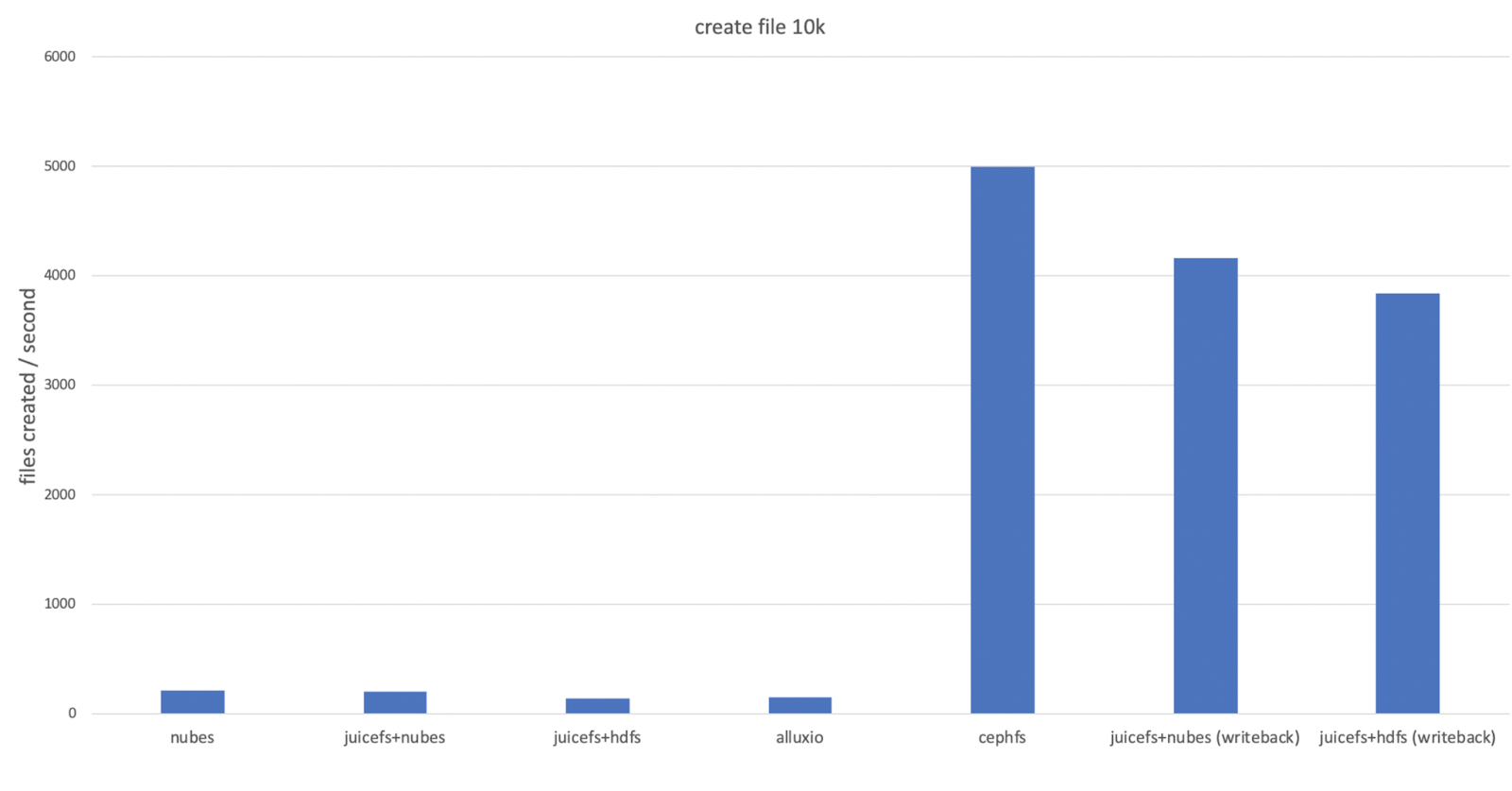
File creation
We compared the time taken to create 10,000 small files. The natural performance of nubes used as data storage in handling metadata was measured and compared with JuiceFS:
- Redis was used as the metadata engine.
- The creation rate of 100-byte files was measured using 10 processes with the
cpcommand. - As object storage did not inherently support POSIX, measurements for nubes were optimized for object storage performance.
- Tests were also conducted with JuiceFS'
writebackoption, which temporarily stores data locally and asynchronously saves it to data storage. For details, see Write Cache in Client.
The test results are as follows:
- There was little difference between nubes and JuiceFS+nubes, indicating that using JuiceFS with nubes as data storage did not result in performance degradation.
- JuiceFS+HDFS and Alluxio, which worked with HDFS, appeared to be converging on the performance of the NameNode that handled HDFS metadata.
- Using the
writebackoption could improve performance by several orders of magnitude. However, enabling thewritebackoption carried the risk of data loss, making it suitable for temporary data purposes.
Test conclusion
The performance of JuiceFS inherently aligns with the performance of the underlying data storage. It supports a variety of features such as POSIX compatibility and concurrent accesses without experiencing performance degradation. Moreover, depending on the workload or usage pattern, JuiceFS may exhibit performance superior to the native capabilities of the data storage. Although not tested here, reading cached data can improve performance as it is read from the local disk. Alternatively, applying the writeback option can enhance performance when dealing with temporary data.
JuiceFS offers various caching options that can be applied based on the workload. For details, see the cache document.
Summary
Internal storage + JuiceFS in AiSuite
In AiSuite, we’ve implemented JuiceFS utilizing the internal support for HDFS and nubes object storage, providing a storage solution tailored for AI workloads while minimizing operational burdens.
A recap of the evaluated internal storage considerations in AiSuite is as follows:
| Solution | POSIX | RWO | ROX | RWX | Scalability | Caching | Interface | Note |
|---|---|---|---|---|---|---|---|---|
| HDFS | ✕ | - | - | - | ◯ | ✕ | CLI, REST | No support for K8s CSI Driver |
| nubes | △ | - | - | - | ◯ | ✕ | CLI, REST, S3, POSIX | No support for K8s CSI Driver |
| Ceph RBD | ◯ | ◯ | ✕ | ✕ | △ | ✕ | POSIX | No support for multiple clients |
| NFS | ◯ | ◯ | ◯ | ◯ | ✕ | ✕ | POSIX | Has scaling and HA issues |
| Local Path | ◯ | ◯ | ✕ | ✕ | ✕ | ✕ | POSIX | No support for data durability, tricky scheduling |
| Alluxio | △ | ◯ | ◯ | ◯ | ◯ | ◯ | POSIX | Not fully support POSIX, data inconsistency |
| JuiceFS+nubes | ◯ | ◯ | ◯ | ◯ | ◯ | ◯ | POSIX | Nubes has high load |
| JuiceFS+HDFS | ◯ | ◯ | ◯ | ◯ | ◯ | ◯ | POSIX | HDFS has a file count limit. The maximum block size is 16 MB |
At AiSuite, we recommend using nubes object storage as the data storage rather than HDFS. HDFS can face metadata management challenges on the NameNode when dealing with a large number of files. JuiceFS, by dividing files into smaller blocks, alleviates the file count concern. Even with the maximum block size set to 16 MB, storing 1 TB of data could result in over 62,500 files. The consideration of increasing the maximum block size to 64 MB is discussed further here.
Advantages of using JuiceFS
JuiceFS, as part of the AI platform in AiSuite, presents various advantages:
- Support for large-scale shareable volumes (
ReadWriteMany,ReadOnlyMany). - High-performance capabilities, serving as an effective replacement for hostPath and Local Path. It facilitates the smooth transition of stateful applications to a cloud-native environment.
- Shared workspaces, checkpoints, and log storage for distributed AI training.
- Ability to handle numerous small files crucial for AI training (an alternative to HDFS/Alluxio).
- Utilization of HDFS and nubes object storage for internal storage, minimizing operational burdens.
- Independent operation of user-specific data storage and metadata engines, avoiding mutual interference.
- Support for diverse data storage and metadata engines, making it applicable to most Kubernetes environments.
- Cost-effective replacement for shared storage solutions such as AWS EFS, Google filestore, and DDN EXAScaler.
Conclusion
This article introduced JuiceFS and explained how it was implemented at NAVER. The adoption of JuiceFS allowed the transition from legacy storage to a high-performance storage solution suitable for AI workloads. While the examples focused on NAVER's on-premises environment, JuiceFS can also be applied in public cloud environments like AWS and Google Cloud.
If you are facing similar challenges, we hope this information proves helpful.
Check out the original post in Korean here.