















DMALL is Asia's leading omnichannel digital retail solution provider. It has partnered with 380 retail enterprises and nearly 1,000 brands, spanning 6 countries and regions. It digitally reconstructs the retail industry, offering end-to-end business SaaS services.
As our business developed and data grew, our storage-compute coupled architecture became unsatisfactory. We faced issues like redundant, wasteful compute resources, complex CDH distribution technology stack, challenging deployment and operations, and intense compute resource peaks and valleys. We needed to establish a big data foundation and platform toolchain that was more cost-effective and reusable in a multi-cloud environment.
During our architecture upgrade, JuiceFS, an open-source distributed file storage system, has played a vital role in storage design. It maintains compatibility with the HDFS protocol, reduces complexities in adapting various apps and engines, and seamlessly integrates with object storage services from various cloud providers, enhancing our architecture upgrade efficiency.
In this article, I’ll deep dive into our architectural evolution during the transformation and share our experience in this process. I hope this article is helpful if you’re facing similar challenges.
Pain points and challenges of our architecture
Native pain points of the storage-compute coupled architecture
The cost and operational challenges brought about by the storage-compute unified architecture are issues that most enterprises will inevitably face during their big data development journey.
In the traditional Hadoop ecosystem, the roles of data storage and computation are typically deployed on the same machines, with one responsible for storage and the other utilizing CPU and memory for computation. Consequently, both MapReduce and Spark have adaptively designed multi-tiered data localization strategies, allocating tasks to nodes that store the required data, to reduce the network overhead and additional storage pressure resulting from intermediate data interactions. This approach enhances the overall efficiency of big data applications.
However, as enterprises grow, it becomes increasingly challenging to maintain a consistent growth rate between the volume of data stored and the number of nodes required for computation. Especially with the notion that "data is the core asset of the enterprise," the accumulation of a large amount of historical and cold data leads to a much higher demand for data storage than for compute resources. Ultimately, enterprises are forced to continually add machines to store more data, but a significant portion of compute resources remains underutilized, leading to idle and wasteful resources.
Furthermore, the continuous growth of data volume also brings about challenges such as pressure on the HDFS NameNode metadata and limitations on the cluster node scaling. These issues consistently stress out different big data teams.
Our challenges
The DMALL big data ecosystem, when initially built, adopted the traditional Hadoop storage-compute integrated technology stack. Apart from the inherent challenges brought about by this architecture's native design, the Big Data team at DMALL faced additional scenario-specific challenges due to the diversified B2B business landscape:
-
Diverse components and complex technologies: Previously, the team heavily relied on the CDH distribution, which featured many architectural components and roles, encompassing 11 service categories (like storage, computation, operations, monitoring, and security) and 22 role types. Over time, integrating new technologies became exceptionally troublesome, requiring consideration of numerous compatibility issues.
-
Complex deployment and challenging operations: Both on-premises and SaaS deployment models imposed substantial workloads on the Big Data team, resulting in low delivery efficiency. Challenges included network planning, capacity planning, public cloud instance selection, bug fixes, and daily maintenance across multiple environments.
-
Intense compute resource peaks and valleys: In the storage-compute coupled architecture, the big data cluster and application cluster operated independently, exhibiting different resource usage patterns. Peak resource demand in the big data cluster occurred during the early morning, with minimal ad-hoc query activities during the day. Conversely, application clusters experienced peak utilization during daytime hours, with minimal traffic at night. Consequently, the challenge of resource wastage and idleness persisted without a comprehensive resolution.
Storage-compute decoupled architectural design
As DMALL embarked on a comprehensive B2B transformation, aiming to provide retail omnichannel solutions to a growing number of B2B customers, we needed to establish a cost-effective, reusable foundation and platform toolchain for big data in multi-cloud environments. The Big Data team at DMALL designed and built a storage-compute decoupled, lightweight, scalable, and cloud-neutral big data cluster architecture.
The first step in storage-compute decoupling was to address how data could be swiftly transitioned from HDFS clusters to cloud provider storage services.
Initial attempt: Direct integration with object storage
During the exploratory phase of architecture upgrade, the most straightforward approach was considered—directly integrating with cloud service provider object storage through APIs.
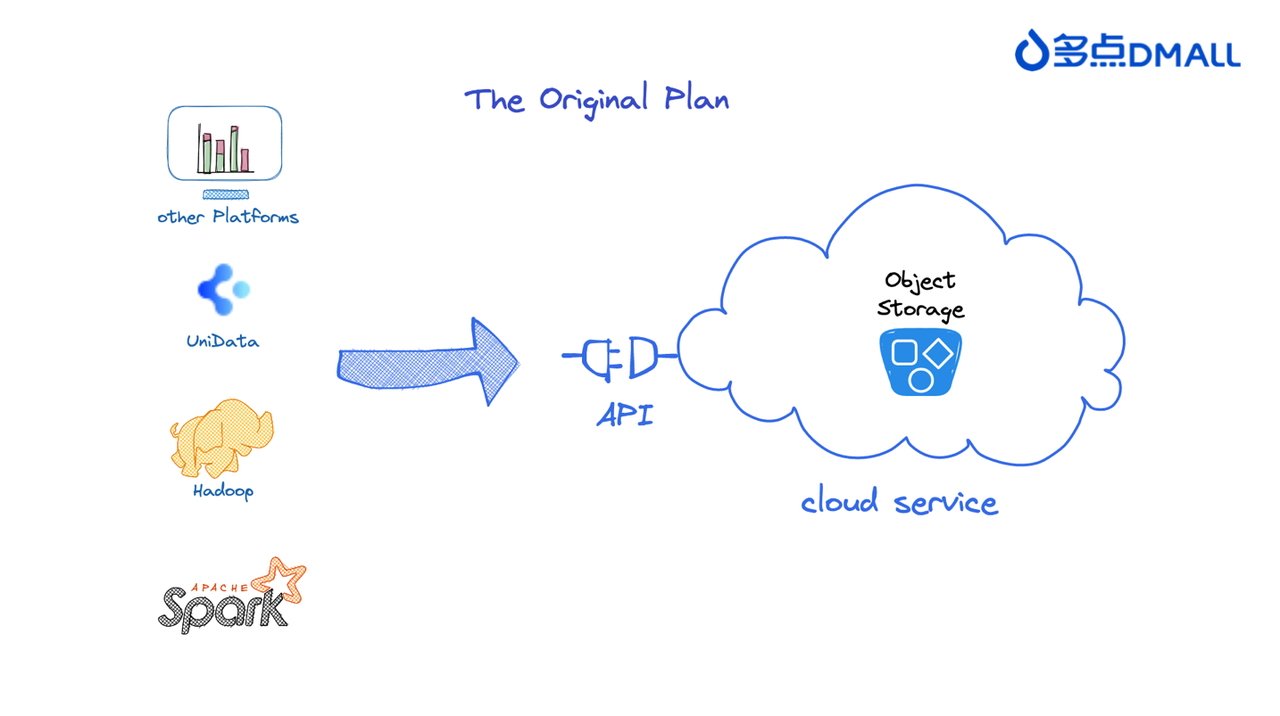
The logic behind this design was concise and clear. Since major cloud service providers offered stable object storage services and comprehensive APIs, direct integration seemed like a way to reduce the complexity of architecture upgrade. To quickly verify the feasibility of this approach, we initially switched some of the functionalities in the big data platform that interacted with HDFS to interact with object storage instead.
However, the rapid verification results showed that this design not only failed to meet expectations but also significantly increased the complexity of big data platform development.
The core issues included: - Some B2B customers might choose their trusted or preferred cloud service provider, making the choice uncontrollable. - Despite underlying S3 protocol similarities, there were still significant differences in object storage APIs among major cloud service providers. - To cater to different cloud service provider requirements, the big data platform toolchain would have to develop multiple sets of code to accommodate these requirements. This resulted in substantial development effort.
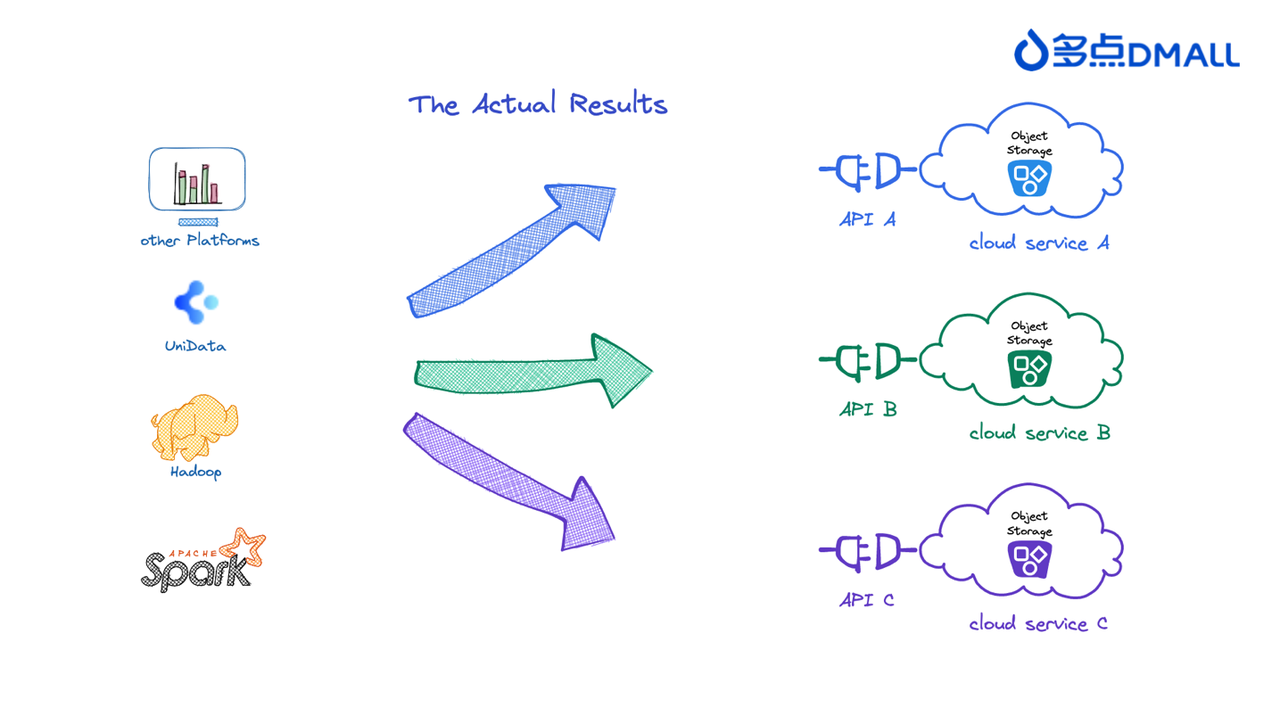
Upon validation, the above solution was only suitable for small-scale pilots and couldn't support the large-scale adjustments required for the entire big data architecture. Therefore, a new solution needed to be explored. This is when JuiceFS came into our view.
JuiceFS helped a smooth transition
The DMALL Big Data team had been keeping an eye on JuiceFS for a while. After the direct use of object storage as a solution proved unfeasible, we had been searching for a way to smoothly transition big data applications and engines to object storage. After continuous exploration and validation, we realized that JuiceFS was the solution we had been searching for all along.
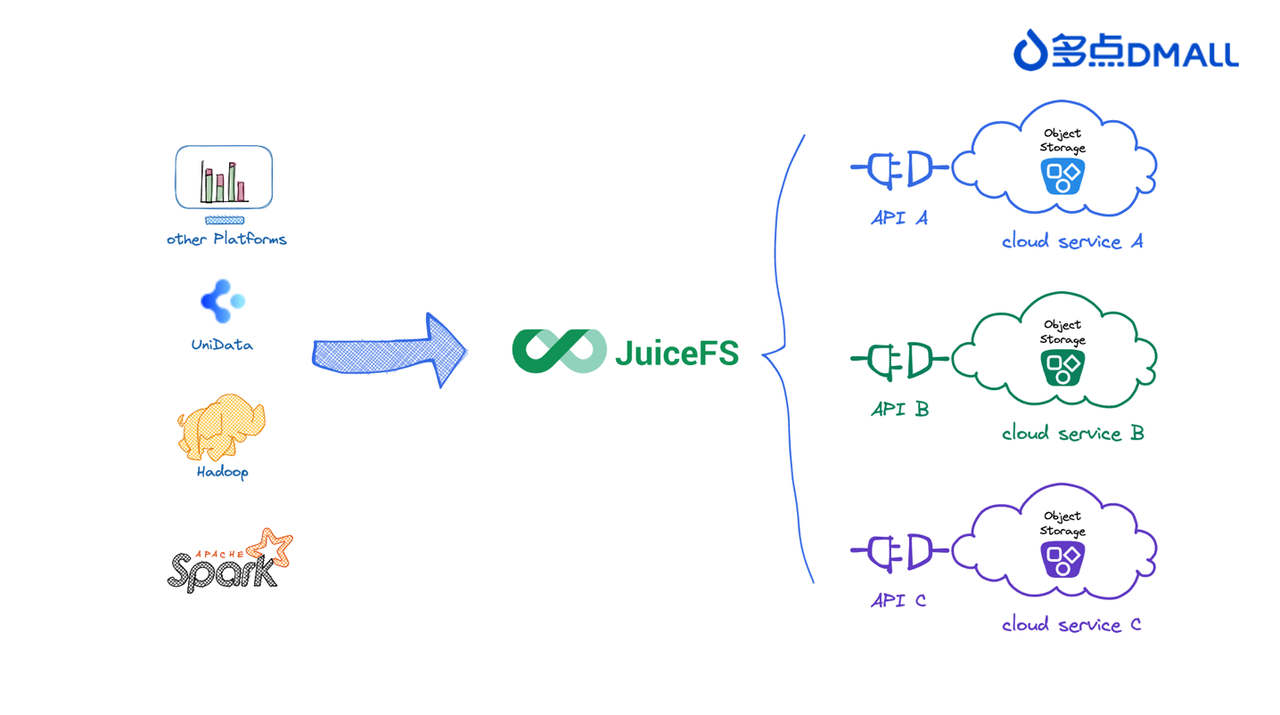
JuiceFS has the following advantages:
- Integration with mainstream public cloud object storage providers: To achieve storage-compute separation effectively, object storage is the optimal choice since it is a fundamental service in the public cloud. JuiceFS' underlying storage integrates with object storage services from most market-leading cloud service providers. This enables us to completely separate storage and compute resources, thus achieving the desired separation.
- Perfect compatibility with HDFS protocol for seamless transition: JuiceFS provides a Hadoop Java SDK, helping all computing engines and applications that use traditional HDFS APIs switch seamlessly. This allows for minimal changes in configurations, greatly reducing the complexity of debugging and adapting engines under the new architecture.
- Independent metadata engine to resolve NameNode bottlenecks: JuiceFS' metadata is stored in a separate storage engine, completely resolving NameNode memory constraints and single-point issues. Deploying the metadata engine independently allows for easier tuning and maintenance. Without metadata scaling pressure, cluster scaling limitations no longer exist.
- CSI support for cloud-native design: In the journey to build a cloud-native architecture, JuiceFS' Kubernetes CSI Driver completes the architectural design, making JuiceFS even more convenient to use in a Kubernetes environment.
Final architecture design
Below is the final architecture design, which decouples storage and compute:
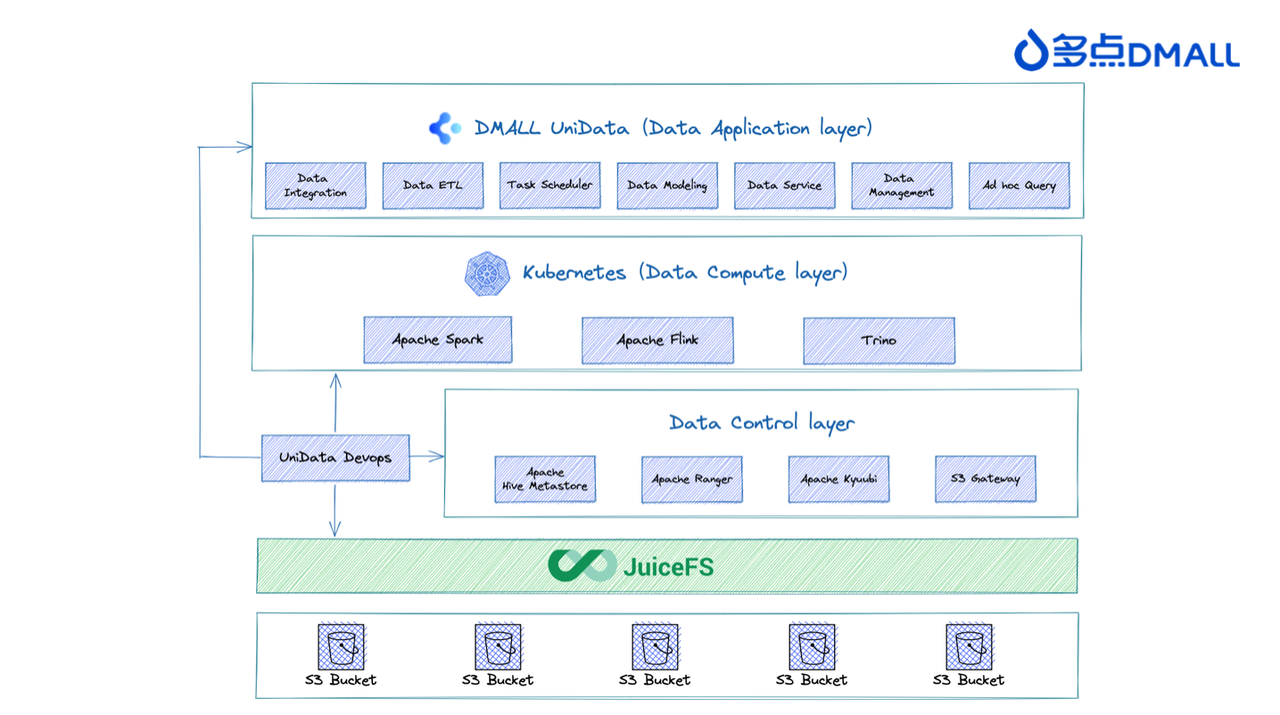
The overall architecture can be divided into several layers: - The data application layer: The top layer comprises the DMALL Big Data team's in-house UniData big data platform toolchain. It provides comprehensive capabilities for big data development governance, including data integration, data development, task scheduling, and data assets. - The data compute layer: The data compute layer is managed by Kubernetes, offering components like Spark and Flink. - The data control layer: This layer offers metadata storage, access control, query proxies, and other functionalities. - The data storage layer: This is object storage provided by JuiceFS and various cloud service providers. It provides protocol adaptation and acceleration capabilities. JuiceFS acts as an intermediary storage layer, abstracting the underlying storage media and isolating different cloud environments. It provides a unified HDFS API to ensure consistency and stability in engine execution and application functionality. Thus, it safeguards the overall quality of external services provided by the cluster.
Final test results
We conducted performance tests comparing Spark on YARN and Spark on Kubernetes multiple times during the architecture upgrade process, executing multiple TPC-DS SQL queries. The following are the comparison results:
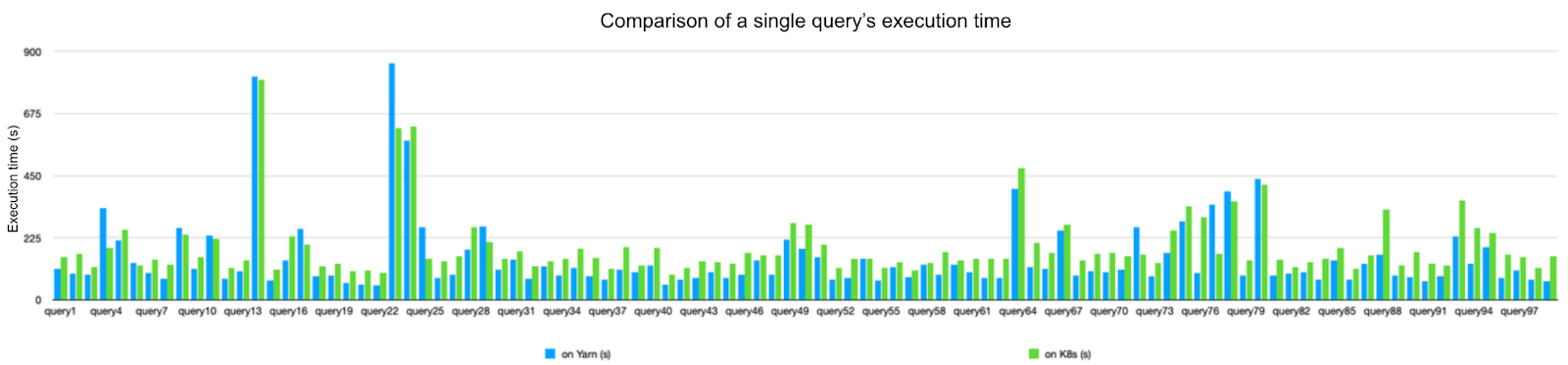
These tests were conducted using the UniData big data platform to configure tasks for data computation comparison. Variables included adjustments in platform scheduling strategies and Spark version upgrades. Excluding other variables, we drew the following conclusions:
- The execution duration of Spark tasks based on HDFS running on YARN was nearly on par with those based on JuiceFS running on Kubernetes, with only minor performance differences observed.
- JuiceFS' data caching design significantly accelerated data queries. The execution speed noticeably improved after multiple runs of the same SQL query.
- JuiceFS consumed some additional memory compared to tasks based on HDFS, but overall, it met the requirements for our new architecture to be deployed in production.
Based on the test results, this new architecture has been smoothly operating in multiple public cloud environments.
How we benefit from the storage-compute decoupled architecture
In summary, during our transition from traditional Hadoop storage-compute coupled architecture to storage-compute decoupled architecture, JuiceFS has played a crucial role in storage design, facilitating the upgrade process. It maintains compatibility with the HDFS protocol, reducing complexities in adapting various applications and engines. Furthermore, it seamlessly integrates with object storage services from various cloud providers, enhancing overall architecture upgrade efficiency. The switch to a cloud-native storage-compute decoupled architecture has yielded several benefits:
- Cost savings: Separating storage and compute saves our enterprise users significant hardware or cloud service costs, leading to increased customer satisfaction and improved service contract renewal rates.
- Enhanced technical scalability: Previously, we managed components using the CDH distribution, which imposed limitations due to version constraints between engines and the risks associated with important component upgrades. With storage-compute separation, we have overcome these restrictions. We can now selectively upgrade and debug individual components, and even conduct A/B testing within the same cluster. This significantly reduced our upgrade risks.
- Improved deployment and operational efficiency: Before the upgrade, our fastest delivery time was measured in days, not including the prior cluster design and preparation work. Now, we can achieve deliveries within hours, with resources being used on-demand. This eliminates the need for complex upfront investments, and the big data platform can be launched with a single click, resulting in substantial cost savings in terms of manpower.
We were fortunate to encounter the JuiceFS project during the overall architecture upgrade. We hope that this article will assist more enterprises in utilizing JuiceFS effectively. In the future, we’ll continue to support the JuiceFS community and contribute more to its development.
If you have any questions or would like to learn more details about our story, feel free to join discussions about JuiceFS on GitHub and the JuiceFS community on Slack.