















As large language models (LLMs) gain popularity, GPU computing resources are becoming increasingly scarce. The traditional strategy of scaling compute power based on storage demand now needs to shift to a model where storage adapts to compute availability. To ensure data consistency and simplify management, enterprises often rely on a centralized object storage point in a public cloud of a specific region to store all model data. However, when it comes to scheduling compute tasks across regions, manual data copying and migration are not only costly but also bring about significant complexity, especially regarding permissions and maintenance.
The mirror file system feature in JuiceFS Enterprise Edition allows users to automatically replicate metadata from one region to multiple other regions, creating a one-to-many replication model. In multi-cloud architectures, this feature ensures data consistency while significantly reducing the need for manual operations.
In JuiceFS Enterprise Edition 5.1, this feature has been expanded beyond read-only support to now include write capabilities. This article explores the implementation of read-write operations in the mirror file system.
Why we built the mirror file system feature
Consider the following scenario: a user has deployed a file system in City A, but the available GPU resources there are insufficient. Meanwhile, the user has spare GPU capacity in City B. There are two straightforward approaches for running model training tasks in City B:
-
Mounting the file system in City B from City A. In theory, as long as the network between the two cities is stable, the client in City B can access the data for training. However, file system access often involves frequent metadata operations. Due to the large network latency between the two locations, performance is usually far below expectations.
-
Creating a new file system in City B and copying the necessary dataset there before training. While this ensures optimal performance for training tasks in City B, it also has clear drawbacks:
- Creating a new file system requires significant hardware investment.
- Synchronizing data before each training session increases operational complexity.
Given the limitations of both approaches, neither is ideal. This is where the JuiceFS Enterprise Edition's mirroring file system comes into play. It allows users to create one or more complete mirrors of an existing file system, automatically synchronizing metadata from the source. This enables clients in the mirrored region to access the file system locally, offering a high-performance experience. Since only metadata can be mirrored, and the synchronization process is automatic, the mirror file system significantly reduces both cost and operational complexity compared to manually copying data.
How the mirror file system works
The architecture of JuiceFS Enterprise Edition is similar to that of the Community Edition, comprising a client, object storage, and a metadata engine.
The key difference is that while the Community Edition typically uses third-party databases like Redis, TiKV, or PostgreSQL as its metadata engine, the Enterprise Edition features a proprietary, high-performance metadata service. The metadata engine consists of one or more Raft groups, as shown below:
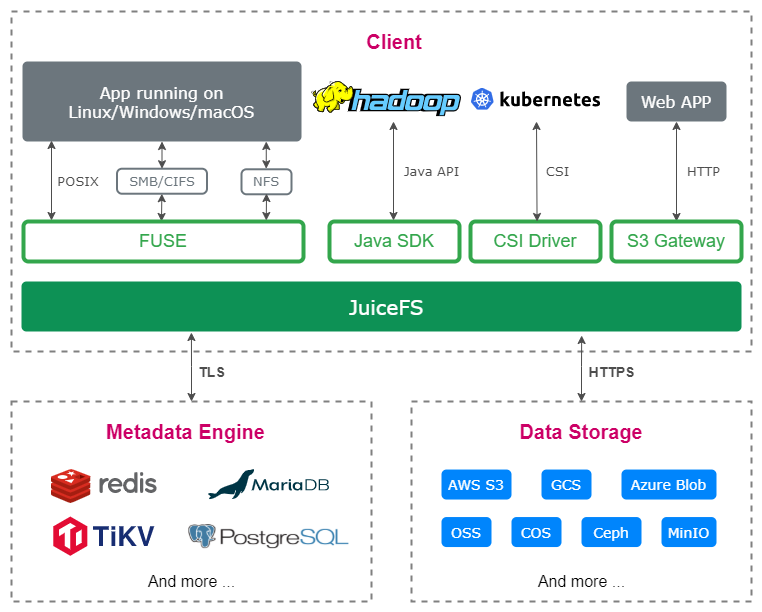
Thanks to the separation of metadata and data in JuiceFS’ architecture, users can choose whether to mirror just the metadata, the data, or both. When mirroring both, the architecture looks as follows:
At this point, the metadata service of the mirror is part of the same Raft group as the source metadata service, but its role is a learner. When metadata updates at the source, the service automatically pushes change logs to the mirror, where they are replayed. This means the existence of the mirror file system does not impact the performance of the source file system. However, the metadata version on the mirror will lag slightly behind.
Data mirroring is also done asynchronously, with designated nodes automatically synchronizing the data. The difference is that, for clients in the mirrored region, only the local metadata is accessed, but both regions' object storage can be accessed. When reading data, the client prioritizes reading from the local region. If the required object cannot be found, it will try to retrieve it from the source region.
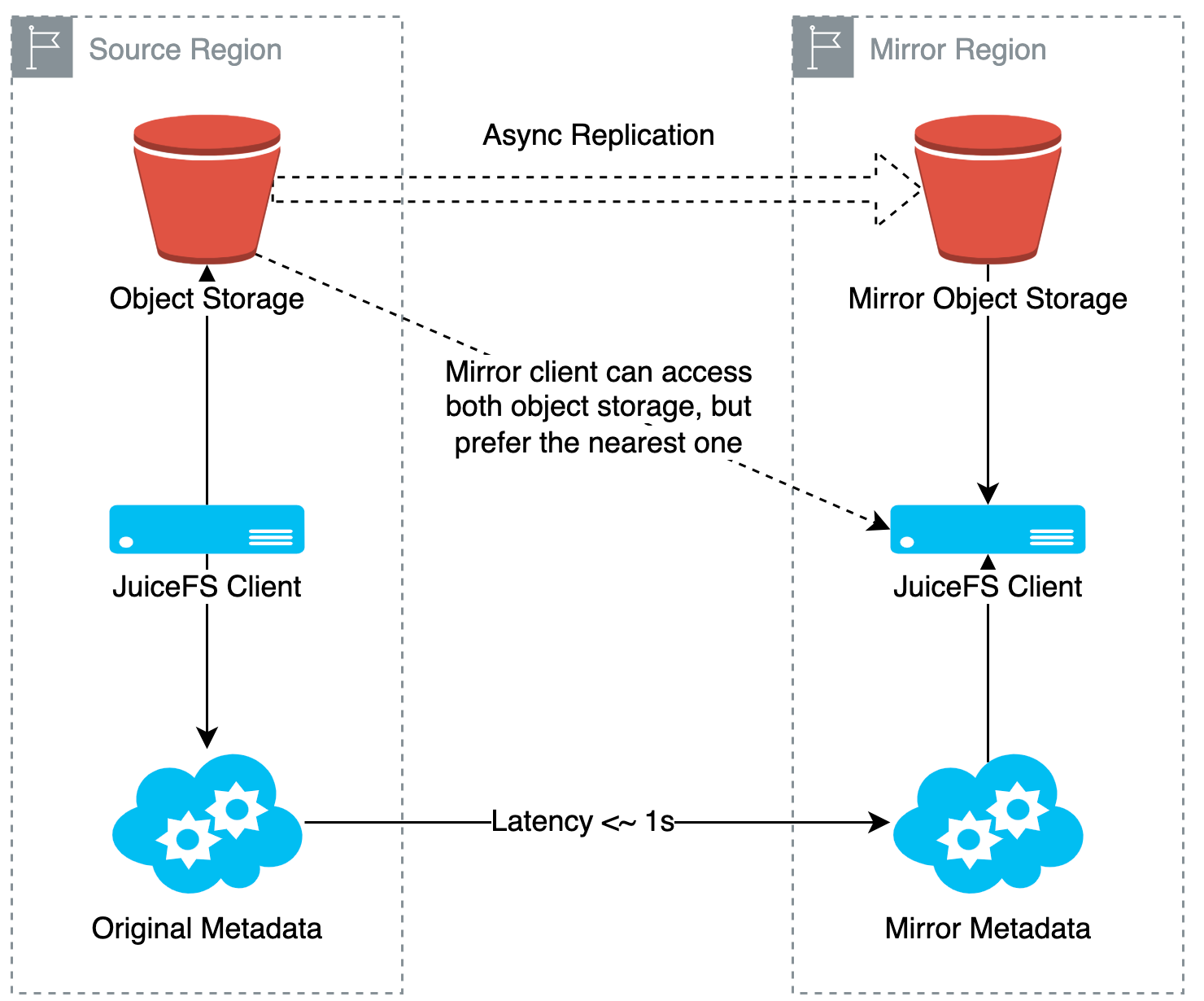
Generally, since data tends to be large and costly to duplicate, a recommended approach is to only mirror the metadata while setting up a distributed caching system in the mirrored region to speed up data access. Here's a diagram showing the setup:
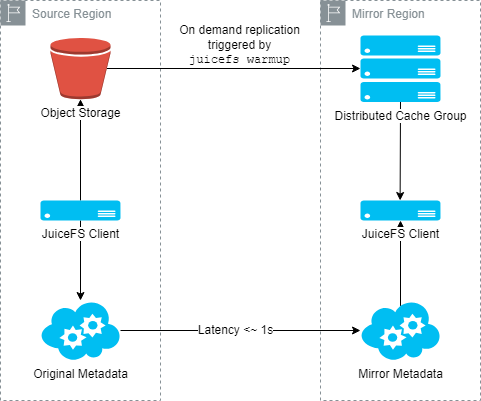
Recommended usage of JuiceFS mirroring: Two regions share the same object storage, and the mirrored region deploys a distributed cache group to improve performance.
This approach is especially suitable for scenarios like model training, where datasets can be prepared in advance. Before running the training tasks, users can run the juicefs warmup command to fetch the required data objects into the cache group in the mirrored region. Then, the training can be executed locally within the mirrored region, with performance comparable to the source region (assuming it also has a distributed cache).
Write capabilities of mirror file systems (experimental)
In previous versions, the mirror client operated in read-only mode by default. Because mirrored metadata could only be read, all modifications had to be performed on the source. However, with growing user needs, we noticed new use cases, such as temporary data generated during model training. Users wanted to avoid maintaining two separate file systems and desired the ability to perform some write operations on the mirror as well.
To meet this need, we support write capabilities for mirror file systems in version 5.1. When designing this feature, we focused on three key aspects:
- Ensuring system stability
- Maintaining consistency between source and mirror
- Preserving write performance
Initially, we considered allowing mirrored metadata to handle write operations, but during development, we realized that merging metadata updates between source and mirror would involve handling complex details and consistency issues. Therefore, we maintained the design where only the source metadata can be written. To handle write requests on the mirror client, two possible approaches emerged:
- Option 1: The client sends the write request to the mirrored metadata service, which then forwards it to the source. Once the source processes the request, it syncs the metadata back to the mirror before responding. This method simplifies the client-side operations but complicates the metadata service since it has to manage request forwarding and metadata synchronization. Since the workflow is long, any error in the process could lead to failure.
- Option 2: The client connects to both the mirrored metadata service and the source metadata service directly. It handles read and write requests separately: reads go to the mirror, and writes go to the source. Although this makes the client logic more complex, it simplifies the metadata services, requiring minimal adjustments. Overall, this option is more stable.
For simplicity and reliability, we chose Option 2, as shown in the diagram below. Compared to the original architecture, the only major addition is that the mirror client now sends write requests to the source metadata service.
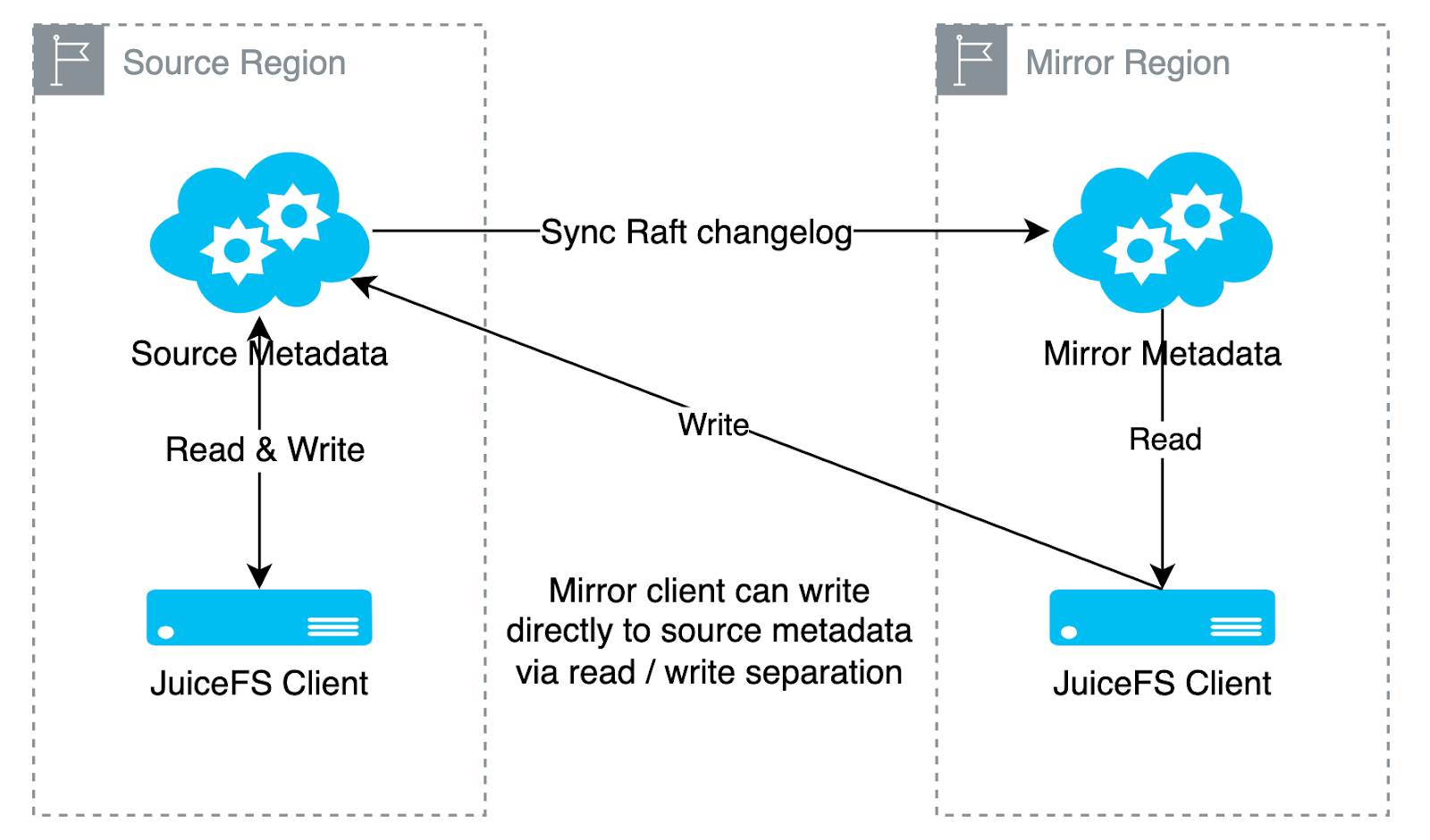
Here’s an example of creating a new file (a create request) to explain the workflow in more detail.
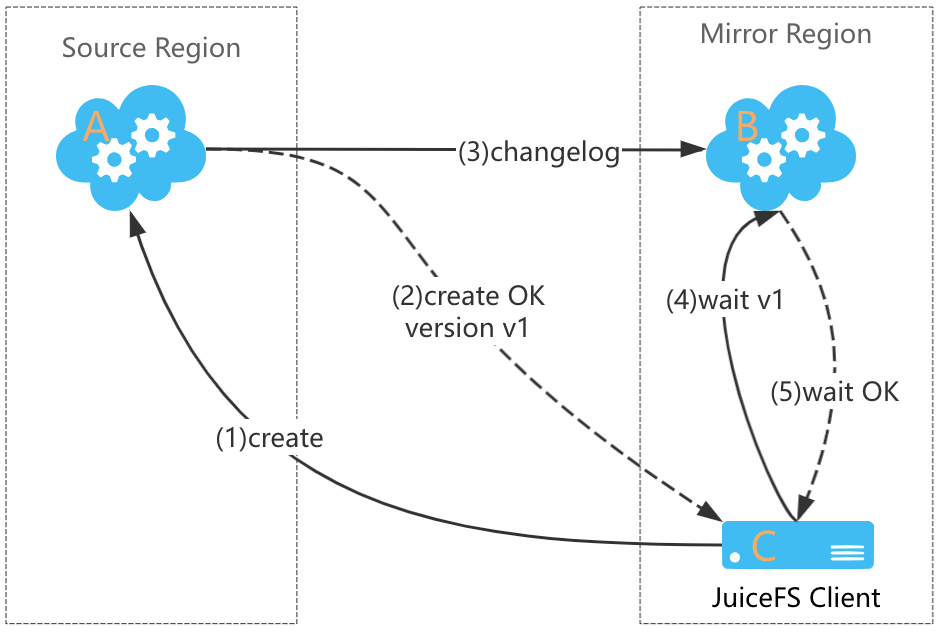
Suppose the source and mirrored metadata services are A and B, respectively, and the mirror client is C. The process involves five steps:
- The client sends a write request: C sends the
createrequest to A. - The source responds: A processes the request and replies with
create OK, informing C that the file has been successfully created, and includes the metadata version number (let's say v1). - Change log pushed: At the same time, A generates a change log and pushes it to B.
- The client sends a wait request: After receiving the success response, C checks its cached metadata from the mirror. If the version hasn’t reached v1, it sends a
waitmessage to B with the version number v1. - The mirror responds: B checks its metadata version. If it has reached v1, it immediately responds with
wait OK. If not, the request is queued, and B will respond once its version is updated to v1.
C confirms that the mirror has reached v1 in Step 4 or receives wait OK in Step 5 before returning to the application. In either case, it indicates that B has incorporated the changes from the create operation, and subsequent reads will reflect the latest metadata. Since Steps 2 and 3 occur almost simultaneously, the wait request is typically processed quickly.
The mirror client's read operations follow a similar version-checking mechanism. Specifically, before sending a read request, C compares the source and mirror metadata versions. If the source version is newer, it sends a wait message to B, waiting for it to update before proceeding with the read. However, the cached version in C may not always be up-to-date (for example, if no write requests have been sent for a while). This mechanism improves the possibility of reading fresh data, but doesn’t guarantee the absolute latest data (there may be a delay of less than one second, similar to the original read-only mirror).
How JuiceFS mirror file systems benefit users
Let’s look at an example involving both read and write operations to show how JuiceFS mirror file systems benefit users.
Suppose Client C wants to create a new file newf under the path /d1/d2/d3/d4. According to the file system design, C needs to look up each directory in the path before confirming the file doesn’t exist and then sending a create request. Let’s assume the network latency from C to A and B is 30 ms and 1 ms, respectively, C has no metadata cached, and we ignore the processing time on A and B.
With the mirror file system: All of C’s read requests are handled by B, and only the final create request is sent to A. The total time is roughly:
1 * 2 * 6 (mirror lookup) + 30 * 2 (source create) + 1 * 2 (mirror wait) = 74 ms
Without the mirror file system: If C mounted the source file system directly in the mirror region, every request would go through A, resulting in:
30 * 2 * 6 (source lookup) + 30 * 2 (source create) = 420 ms, which is more than five times longer.
Conclusion
In AI research, where GPU resources are extremely expensive, multi-cloud architectures have become a standard for many companies. By using JuiceFS mirror file systems, users can create one or more complete mirrors that automatically sync metadata from the source. This enables clients in the mirrored region to access files locally with high performance and reduced operational overhead.
In JuiceFS 5.1, we've made significant optimizations to the mirror file system, including introducing write capabilities. This allows enterprises to access data through a unified namespace in any data center, while benefiting from the performance boost of local caching without compromising consistency. We hope the ideas and approaches shared in this article will offer some insights and inspiration for your system design.
If you have any questions for this article, feel free to join JuiceFS discussions on GitHub and community on Slack.