















JuiceFS Enterprise Edition is a distributed file system for high-performance computing scenarios of massive files. It’s applicable to scenarios including AI and machine learning model training, high-performance computing, and more.
JuiceFS Enterprise Edition 5.0 has recently been released, with key features:
- Support for shared block devices
- The convert feature that merges and restores split files into complete files for storage
- Support for importing existing data caches from object storage
Additionally, we’ve significantly improved the usability and observability of distributed cache. This will enhance JuiceFS’ suitability for high-performance computing scenarios.
In this post, we’ll walk you through the new features and optimizations in JuiceFS Enterprise Edition 5.0.
Significant enhancements in cache management
JuiceFS Enterprise Edition 5.0 introduces numerous optimizations in cache management, particularly in distributed caching:
- Improved cache observability: Users can now check the cache status of specific files or directories, enhancing monitoring of cache usage.
- Manual cache eviction: Users can manually clear the cache for specific files or directories. This provides users with flexible control over cache resources. Moreover, when a client deletes a file, the associated cache group will automatically clear relevant data and free up space.
- Support for heterogeneous cache clusters: The system now supports setting different weights for each node. This also allows users to migrate cache data of specific nodes by setting the node weight to 0, enabling more refined resource allocation.
- Automatic fault awareness: The system can automatically identify and remove faulty (such as freezes or EIO errors) cache disks, enhancing overall system reliability.
- Improved balance: Enhancements in balance between cache nodes improve overall hit rates.
- Multiple cache eviction strategies: Users can choose cache eviction strategies during mounting, currently supporting
2-randomandnoeviction. - Data integrity verification: All cache data undergoes default integrity checks, preventing silent errors caused by disk damage or data tampering.
Support for shared block devices for persistent data storage
When users need to perform intensive small file writes or a large number of random write operations, such as exploratory data analysis (EDA), computer vision (CV) training, and performing tasks in Elasticsearch and ClickHouse, they usually involve frequent small I/O operations. When these small requests are uploaded to the object store, the overall performance is often poor due to the higher latency of the object store.
To solve this problem, previous versions of JuiceFS provided a client-side write cache feature, which allowed users to temporarily store data in a local cache and then upload it to object storage asynchronously. However, writing cached data to be uploaded faced greater data security risks. When persistence was not completed, other clients could not read the data. Therefore, the actual usage scenarios were limited.
To solve the issue, JuiceFS 5.0 introduces support for using shared block devices as write caches or direct data storage engines. Multiple clients can mount the same block device simultaneously. As the figure below shows, small I/O operations are written directly to the shared block device, while large I/O operations follow the original process and are sent to object storage. This approach utilizes the low-latency write capabilities of block devices and the high throughput of object storage.
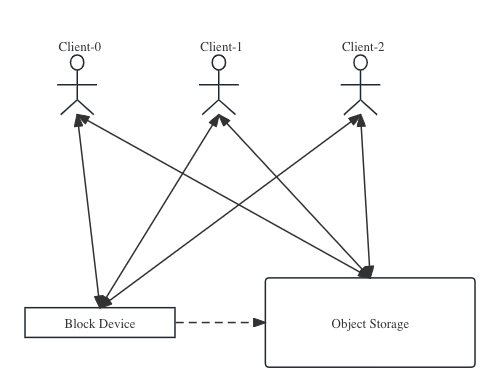
Shared block devices also support various use cases, such as temporarily storing data on block devices before converting it to object storage after a period or permanently storing write requests smaller than a set threshold on block devices. For details, see Shared Block Device.
Accelerated access to existing data in object storage
Many users have accumulated a large amount of data in object storage and hope to use JuiceFS to access these stored data, for example, through the POSIX interface, or to achieve seamless integration with the Hadoop ecosystem.
JuiceFS Enterprise Edition 5.0 supports the direct import of existing files from object storage. This feature scans all objects in a specified object storage bucket, generates corresponding metadata in JuiceFS, and enables read-only access to these imported files in the JuiceFS file system.
As the figure below shows, files written directly to JuiceFS are split and stored in blocks, while imported files are preserved as is in object storage. Client access to imported files is read-only, supporting both JuiceFS local cache and distributed cache.
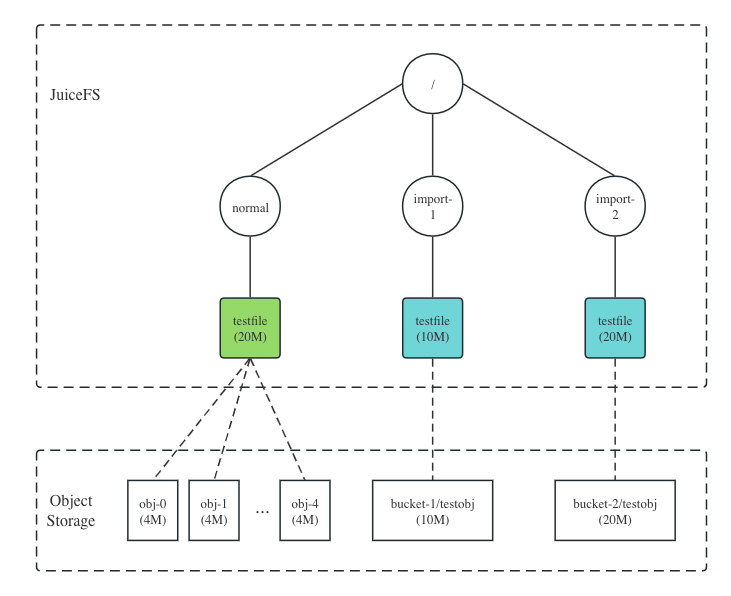
The support for converting split files into objects
By default, JuiceFS spits files and stores them in blocks; it separates metadata from data. This storage format and decoupled architecture enable JuiceFS to be a high-performance and strongly consistent file system.
However, this design may cause inconvenience in scenarios where files need to be read directly from object storage. For example, in a data archiving scenario, the JuiceFS file splitting strategy makes it complicated to set conditions for filtering hot and cold data. Additionally, certain compliance regulations require files to be stored in its original format.
JuiceFS 5.0 introduces a new feature: files are automatically converted into objects. This feature allows files to be automatically merged into a single object after they have not been modified for a period of time. Because object storage does not support efficient renaming and modification operations, the converted files are not allowed to be renamed or modified. The converted objects also support cache.
For details, see File Import and Conversion.