















Hello everyone, JuiceFS v0.17 was released as scheduled. This is the second version we launched in the fall of 2021. Let's go straight to see what new changes are there.
There are 9 users from JuiceFS community contributed 80+ commits for this update on GitHub. Here, we sincerely thank them for their contributions. At the same time, welcome you to join our open source community to contribute code, documents or discuss ideas.
Passed LTP 1270 tests, the compatibility under Linux system is more perfect
The new version of JuiceFS has been further optimized for the Linux system, supporting more flags of rename and setxattr syscalls, and successfully passed 1270 tests of LTP.
LTP (Linux Test Project) is a joint project started by SGI, OSDL and Bull developed and maintained by IBM, Cisco, Fujitsu, SUSE, Red Hat, Oracle and others. The project goal is to deliver tests to the open source community that validate the reliability, robustness, and stability of Linux. The LTP testsuite contains a collection of tools for testing the Linux kernel and related features.
The results:
Testcase Result Exit Value
-------- ------ ----------
fcntl17 FAIL 7
fcntl17_64 FAIL 7
getxattr05 CONF 32
ioctl_loop05 FAIL 4
ioctl_ns07 FAIL 1
lseek11 CONF 32
open14 CONF 32
openat03 CONF 32
setxattr03 FAIL 6
-----------------------------------------------
Total Tests: 1270
Total Skipped Tests: 4
Total Failures: 5
Kernel Version: 5.4.0-1029-aws
Machine Architecture: x86_64The skiped and failed test cases are mainly due to several unsupported functions. For details, see the document.
Optimize the performance of storing temporary data
In response to Spark’s shuffle file and other temporary data storage needs, community contributors William Zhu (@allwefantasy) contributed to JuiceFS with a delayed data upload function, which allows JuiceFS to write data to the local cache disk first. If the data is deleted in a short time, there is no need to write to the object storage, which can provide read and write performance close to the local disk. And when a lot of data is written, it will automatically be written to the object storage to release the local disk space, and there is no need to worry about shuffle data filling up the disk.
This new feature allows JuiceFS to be used as a flexible local disk, providing unlimited storage space and low-latency access for temporary data.
To further improve performance, a metadata engine (MemKV) running in the client's memory has also been added. Like other metadata engines, MemKV is also used to store metadata related to data, but it is not persistent. After the client umount, the metadata of MemKV will be released. MemKV runs entirely in memory, has absolute performance advantages, and is very suitable for temporary file storage scenarios.
TiKV metadata engine improves performance by 5 times in Hadoop scenarios
JuiceFS Java client needs to resolve the path frequently. The Redis engine implements server-side multi-level path resolution through Lua, while the SQL and TiKV engines still require multiple metadata requests to resolve a path, especially when the path is deep, the performance will have an impact.
To solve this problem, this update introduces a metadata caching mechanism similar to the Linux kernel in the JuiceFS Hadoop SDK client, which can control the expiration time of directories, files, and attributes through parameters. It can be enabled in the following ways:
<property>
<name>juicefs.attr-cache</name>
<value>3</value>
</property>
<property>
<name>juicefs.entry-cache</name>
<value>3</value>
</property>
<property>
<name>juicefs.dir-entry-cache</name>
<value>3</value>
</property>The following is a metadata performance test on a 9-level directory. The results show that enabling metadata caching can greatly improve the performance of metadata operations. (The value is the delay of the operation, the smaller the better.)
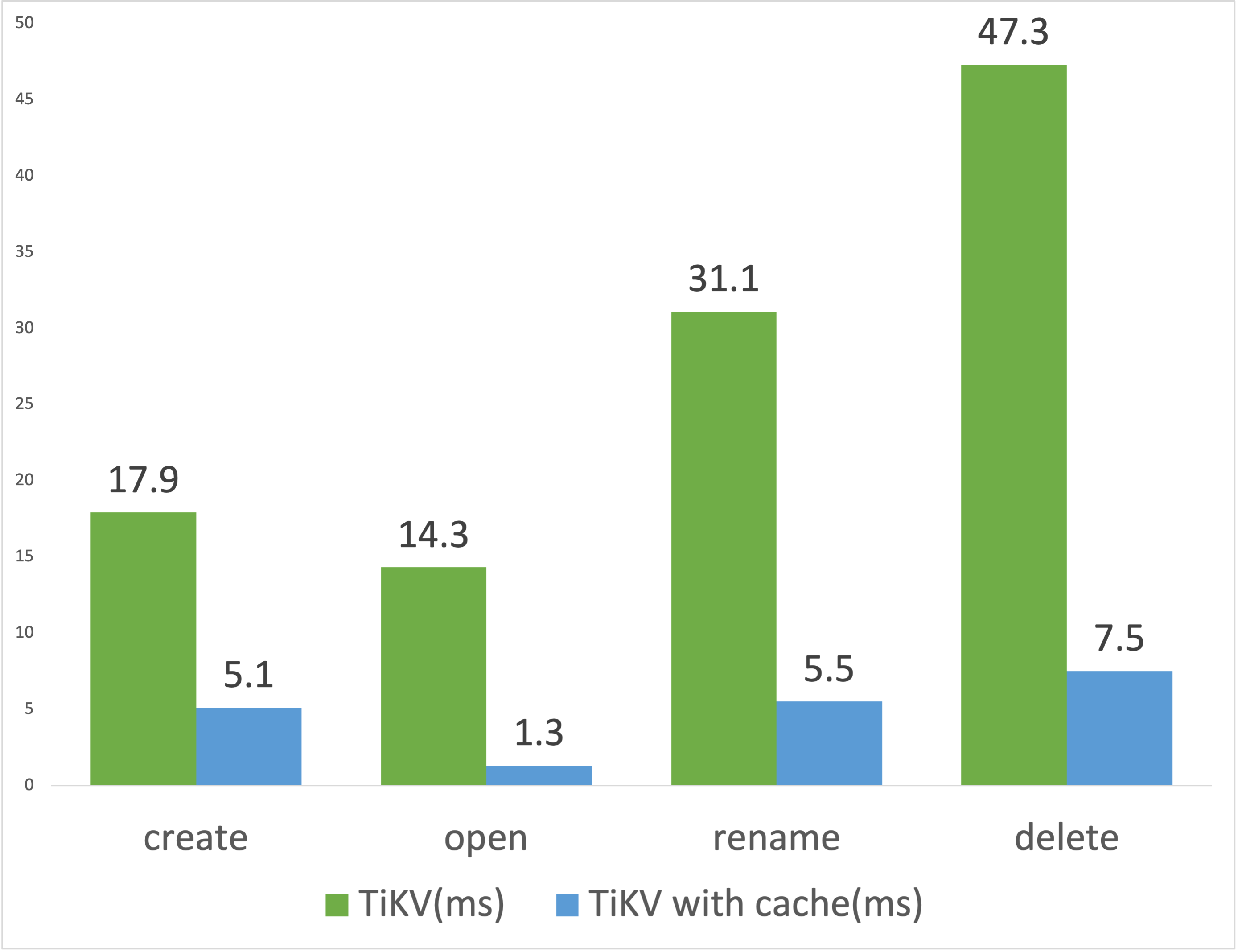
However, it should be noted that turning on the metadata cache will affect the consistency between multiple clients (eventual consistency in a limited time window). For example, after a client deletes a file, other nodes may not have the cache expired and file still exists. Therefore, it is generally recommended to use this function in query scenarios. If it is a mixed read-write scenario, it is recommended to turn on the caching of directories and attributes, and turn off the caching of file items.
1 minute hands-on performance test, the results are clear at a glance
We further optimized the results of the built-in performance testing tool bench in JuiceFS. On the basis of simplicity and intuitiveness, we further made key data highlighted. If a certain performance data deviates from the normal range, it will be displayed in yellow or even red, and you should pay attention at this time.
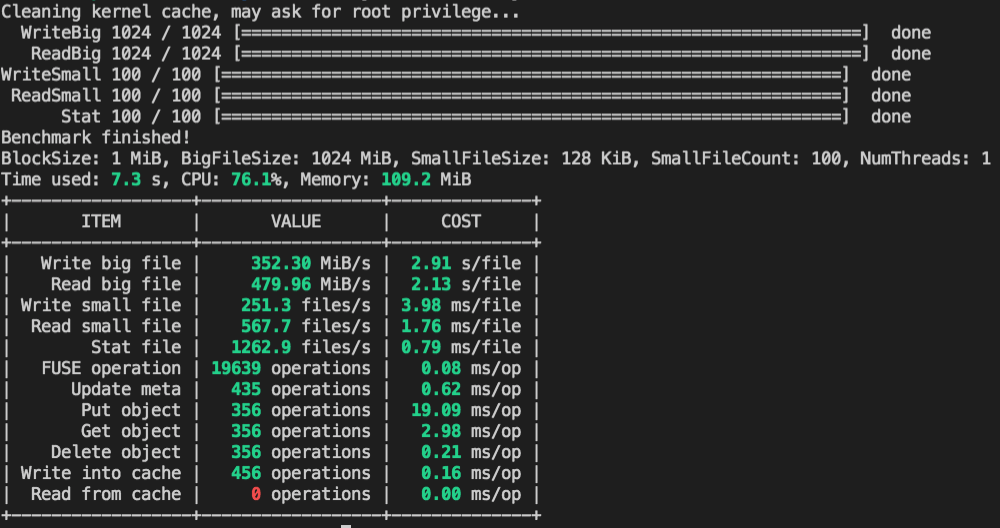
For more information about the new version of JuiceFS, please visit the GitHub project: https://github.com/juicedata/juicefs