















About the Author
Miaocheng, cloud native R&D engineer at Trip.com, is mainly engaged in the R&D and O&M of Elasticsearch and JuiceFS, focusing on distributed databases and NoSQL.
Xiaofeng, cloud native R&D engineer at Trip.com, mainly focuses on database containerization with a strong interest in distributed storage.
1 Background
Trip.com is a Chinese multinational online travel company that provides services including accommodation reservation, transportation ticketing, packaged tours and corporate travel management. Founded in 1999, it is currently the largest online travel agency (OTA) in China and one of the largest travel service providers in the world.
There are about 10 PB cold data in Trip.com coming from backup, image and voice training, logging, etc. Their current storage solutions mainly rely on local disks and GlusterFS, which, however, turn out unsatisfactory regarding the following aspects.
- The `ls` command is very slow when there are many files in a single GlusterFS directory.
- The capacity cannot be flexibly expanded and shrunk based on actual needs due to the restrictions of the machine procurement cycle during the epidemic, thereby difficult to control storage costs.
- The operation and maintenance (O&M) costs remain high because of the machine replacement (caused by the failures such as disk damage) and expansion and shrinkage of capacity.
Fortunately, public cloud vendors provide hybrid cloud customers with cheap storage solutions for massive amounts of cold data. Particularly, using public cloud object storage can significantly reduce storage and O&M costs. In order to reduce the migration costs, we were looking for back-end storage that can support various types of object storage and high-performance file system. After investigating, JuiceFS has been standing out among all services with the following advantages:
- POSIX compatible: non-invasive to applications
- Strong consistency: file modifications are visible immediately, and the close-to-open guarantee is provided for scenarios where a volume is mounted by multiple machines.
- Supporting mainstream public cloud object storage and open-source software as the metadata engine (e.g., Redis and TiKV)
- Supporting cloud native: allowing to mount volumes to Pods through CSI
- Active community: fast code updates and feedback
With a half year of test and use, Trip.comhas successfully interfaced database backup and ElasticSearch cold data storage and migrated 2PB+ data to JuiceFS, and it is expected that 10 PB more data will be accessed in Trip.com in the future. So far, JuiceFS has achieved good results in terms of reducing O&M and storage costs with high stability. This article will briefly introduce how JuiceFS works in cold data migration for Trip.com with discussions on the problems and optimizations along their use and tests.
2 The JuiceFS architecture and POC test
2.1 The JuiceFS architecture
JuiceFS manages metadata and data separately, and implements a POSIX API through FUSE, allowing users to use it like a local file system. When a file is written to JuiceFS, data will be stored in the object storage, and metadata (file name, file size, permission group, creation and modification time, directory structure, etc.) will be stored in the metadata engine (Scheme 1.). With this architecture, the operations such as `ls` and data deletion will only work on the metadata engine and are not limited by the speed of object storage, thus the performance will be better guaranteed.
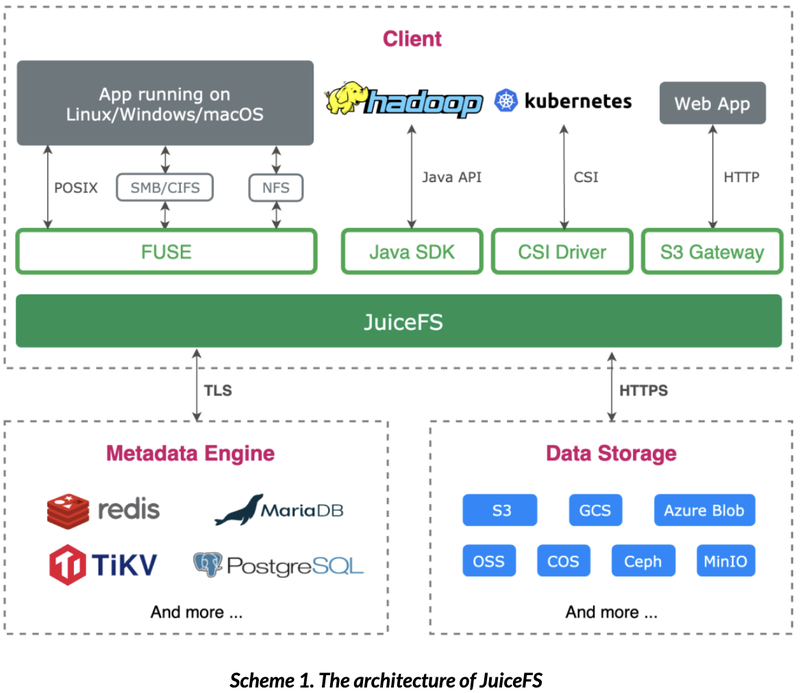
2.2 Metadata engine selection and testing
There are many metadata engine options for JuiceFS, including open-source Redis, TiKV, and JuiceFS Cloud Services. Considering that the data scale in Trip.com is quite large with more data coming in the future, the metadata engine needs to be able to support the storage of metadata on the TB scale and expand horizontally. Thus, TiKV and JuiceFS Cloud Service metadata engine became our alternatives.
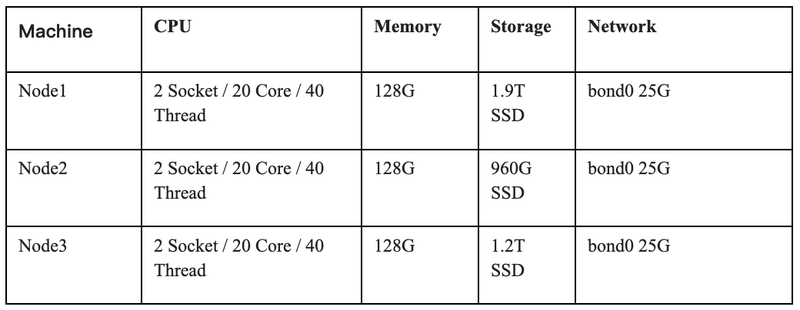
To verify the performance of TiKV, tests were carried out through go-ycsb with the setups listed in the table below.
Test results
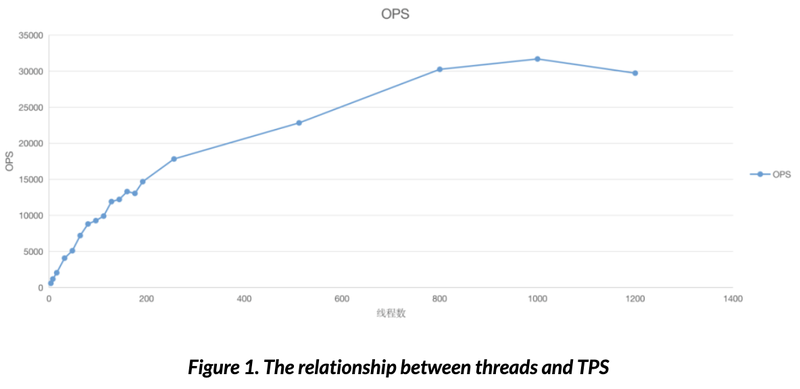
1) For the Write transactions, TPS increases with the increasing number of client threads, and the peak value exceeds 30,000 at approx. 1000 threads (Fig. 1.).
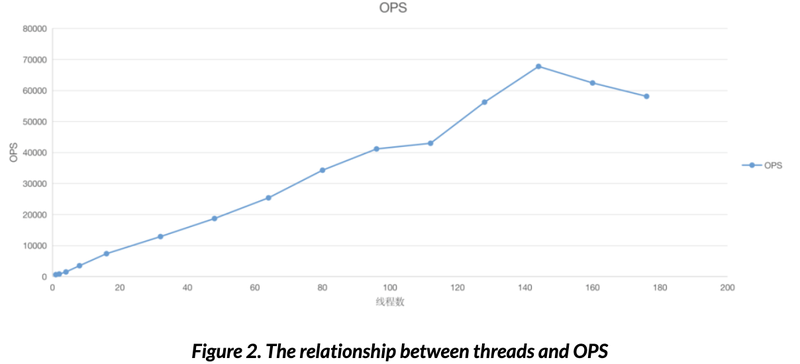
2) For the Get transactions, QPS increases with the increasing number of client threads, and the single node peaks at nearly 70,000 at 140 threads (Fig. 2.).
Results show that TiKV has high read/write throughput, and the response time of a single operation P99 < 10 ms. This performance meets the need in the cold data scenario.
TiKV was eventually chosen by Trip.com as the metadata engine, although the JuiceFS Cloud Services performs better. The selection was mainly based on two aspects: 1. cold data storage does not have a high demand on performance; 2. the response speed of the entire system is not significantly reduced by the metadata engine compared to the 20~200ms access speed of object storage. For transparency, TiKV was chosen as the metadata engine.
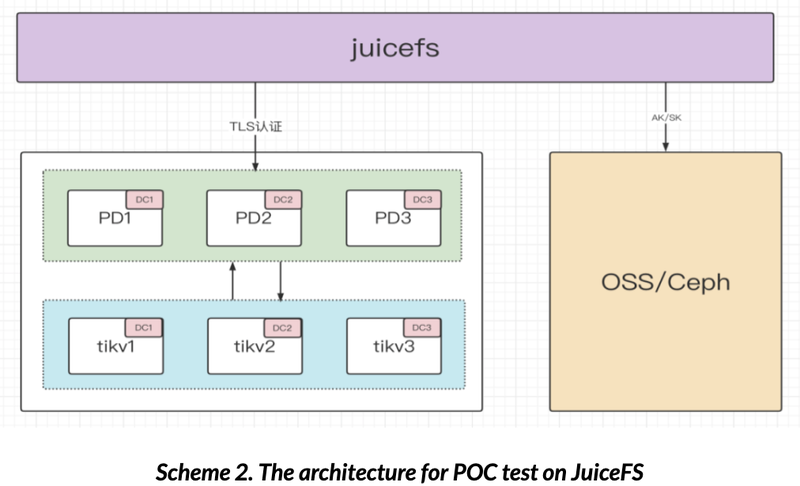
2.3 POC test on JuiceFS
Before shipping to production, in order to specify the SLA indicators and the best usage scenarios, an overall POC test was performed on JuiceFS using mdtest with TiKV as the metadata engine. The deployment uses the architecture shown in Scheme 2.
Test results
1) the relationship between file size and throughput in the single-threaded write
Test results show that throughput increases as file size increases. When a single file ranges between 128MB~256MB, the growth curve slows down significantly. It can be explained that when files are small, the interaction cost between JuiceFS client and the metadata engine and object storage is high compared to the cost of effective data transfer, which limits the throughput. When the files are larger, the interaction cost share decreases and the throughput increases. In order to exploit the full throughput capability of JuiceFS, it is recommended to store files of 128MB or more.
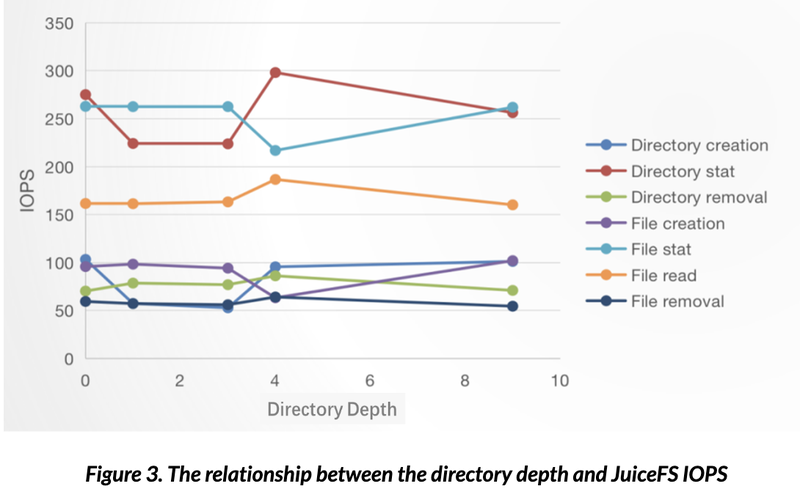
2) the relationship between the directory depth and JuiceFS IOPS
Test results show that there is no significant relationship between directory depth and JuiceFS IOPS (Fig. 3.). We know that, in general, the deeper the depth, the longer the file path is. However, it is not the case in TiKV since the key in TiKV is the inode of the parent directory plus the name of the new entry when creating files/directories in JuiceFS. Accordingly, the directory depth does not affect the size of the key-value pair in TiKV, and in turn the query performance.
3) the relationship between directory size and the speed of the `ls` command
The test result shown in the table below indicates that the number of files in a single directory does not impact the performance of the `ls` command.

2.4 Failure test of the metadata engine
Theoretically, the consistency of the region in the TiKV node is guaranteed by Raft. That is, the failure of the non-leader region does not affect the upper-layer application. If the leader region fails, a new leader region will be elected among the corresponding region copies. However, the election takes time, and the PD node needs to be reported before being processed, so the failure of the leader region will affect some requests for upper-layer applications.
The PD cluster is used to manage the TiKV cluster. Similarly, the failure of the non-leader node of the PD does not affect the upper-layer application. If the leader node fails, a new PD leader needs to be re-elected. During the election process, the request of the JuiceFS client cannot get responded to. Also, it takes some time for JuiceFS to re-establish connection with the new Leader, during which the request of the upper-layer application can be affected.
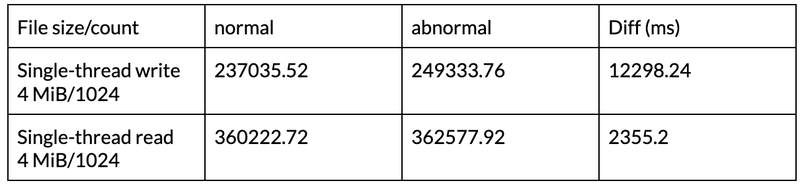
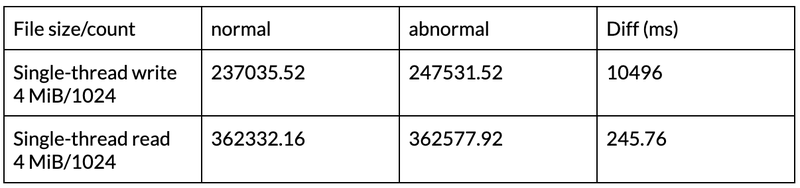
Based on this, Trip.com has simulated node failures in the scenarios of TiKV and PD, tested the time required for recovery after the metadata engine fails in the actual application process, and calculated the difference in elapsed time between reading and writing a certain number of files in a normal scenario and in an abnormal situation. The results (seen in the tables below) show that the fault impact time can be controlled within seconds.
1.TiKV failures
2.PD failures
3. Mechanism of JuiceFS Writing/Reading
3.1 Writing files
When JuiceFS receives a write request, it will first write the data into Buffer, and manage the data blocks following the order of Chunk, Slice, and Block, and finally flush them to the object storage in the Slice dimension (Scheme 3.). A Flush is essentially a PUT operation on each Block in the Slice, writing the data to the object storage and completing the metadata modification. As shown in Scheme 3.,
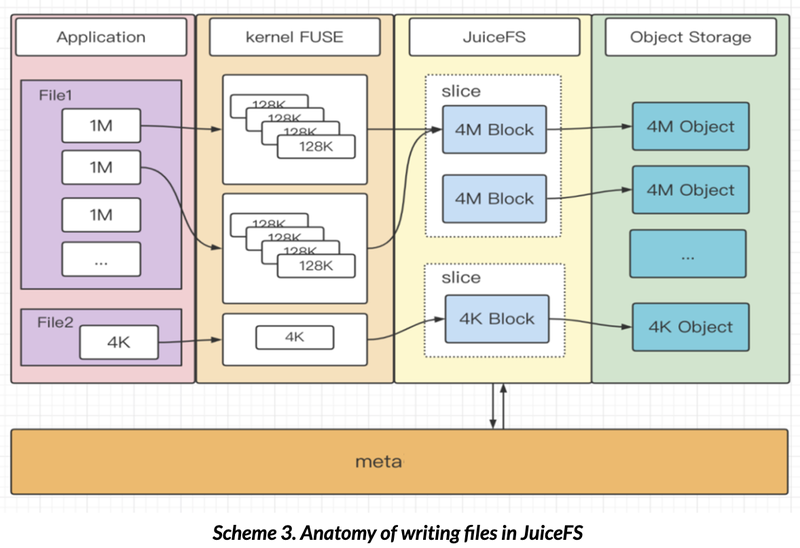
1) Large files are first processed into 128K Blocks by FUSE and then assembled into 4M Blocks in JuiceFS. The Blocks managed by Slice gradually increase until the Slice reaches 64M (that is, the size of a Chunk), at which flush is triggered. The Chunk, Slice, and Block are assembled via a memory buffer, and the buffer size is limited by the JuiceFS startup parameter `buffer-size`.
2) Small files are managed separately by the new Slice and are uploaded to the object storage when file writing is complete.
3) If the client sets the writeback mode, JuiceFS will not directly write data to the object storage but to the local disk where JuiceFS is located, and then asynchronously write the data to object storage. This method can improve the data writing speed despite the risk of data loss.
3.2 Reading files
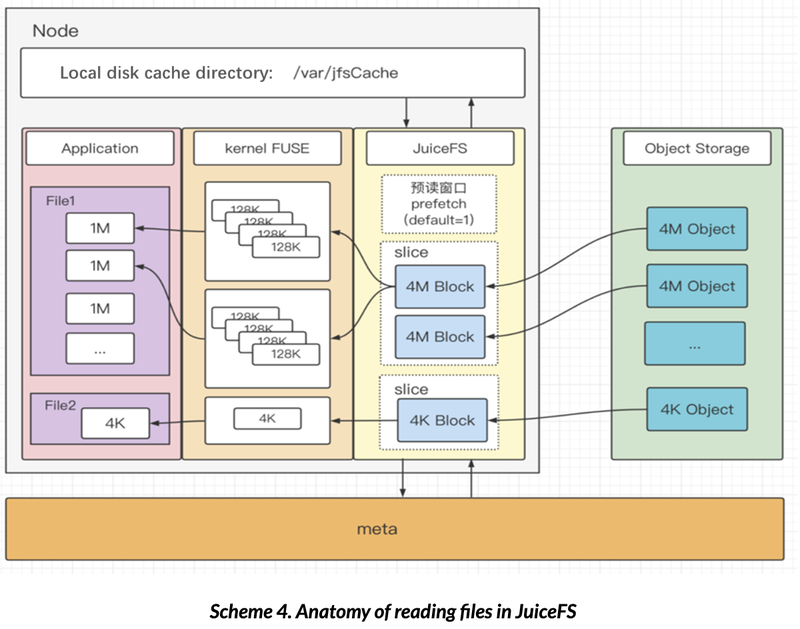
The data processing approach for the read process is similar to that of the write process. After the read request is received by the JuiceFS process, it will first access the metadata engine, find the block to be read, and send concurrent GET requests to the object storage. Due to the immutability of the Block data, the 4M Blocks that have been read will be written to the local cache directory. JuiceFS implements prefetch by reading sequential 4M data blocks ahead. The prefetch window can be set to even larger by adjusting the `prefetch` parameter. (`prefetch` defaults to 1). As shown in Scheme 4.,
1) In the scenario of large file sequential reads, the 4M objects in the object storage will be read, processed by FUSE into 128K Blocks and returned to the user. In this case, the cache hit rate is high with a better throughput performance due to prefetch and Block caching locally.
2) The processes of large file random reads are consistent with those of sequential reads. In this scenario, the probability of prefetch and cache hits is very low, which may affect the read performance since the read data needs to be written to the local cache directory. However, caching can be turned off by setting cache-size = 0.
3) When reading small files (such as files at the size of 4K), the Block of the present file will be read and respond to the user program after being processed by FUSE. The obtained data is also written to the local cache directory.
4. Troubleshooting and performance optimization
4.1 Service denial due to high TiKV CPU usage
Observations: The number of TiKV kv_scan requests suddenly increases, and the CPU usage of the unified_read_po thread pool reaches full.
Analyses: It is because the TiKV client is running the cleanTrash task. The TiKV Beta1 will perform this task at the same time on all JuiceFS clients. When there are many clients mounted on the same volume and the amount of data in the trash is too large, this task will cause sudden pressure on the metadata engine.
Solutions:
1) Increase the monitoring of the client's calls to each interface of the metadata engine, which is convenient for quickly diagnosing which clients cause the problem;
2) Separate background tasks from the client so that the client only needs to execute the user's request and background tasks such as clean trash can be handed over to a separate component for execution, facilitating controls by JuiceFS administrator;
3) Upgrade the TiKV client, the client has added distributed locks and the `no-bgjob` startup parameter since Beta3.
4.2 Data leak on TiKV
Observations: The number of regions and the store size continuously increase although the number of files and the amount of data in OSS do not grow.
Analyses: It is found that the modification and the deletion records of MVCC have not been cleared after checking the data in TiKV through `tikv-ctl`. A complete TiDB deployment will trigger a data GC every 10 minutes, while the data GC needs to be triggered by other applications if deploying TiKV alone. Moreover, there is a small bug in the TiKV 5.0.1 that GC data does not empty deletion logs.
Solutions:
1) Implement a separate component and periodically call the GC function by referring to https://github.com/tikv/client-go/blob/v2.0.0/examples/gcworker/gcworker.go
2) Upgrade TiKV version to 5.0.6
4.3 Unable to recover data in the OSS after PV clean-up in the JuiceFS CSI mounting scenario
Observations: The OSS data is still not cleaned up even one day after all Pods, PVCs, and PVs of ElasticSearch in k8s turn offline.
Analyses: When the PV is cleaned up, the CSI executes the JuiceFS `rmr` command to put all the volume data into the trash. According to the default configuration trash-day=1, the data will be recycled after one day. Since all JuiceFS mount Pods in the environment have been deleted, that is, no JuiceFS process has mounted the CSI volume, and thus the trash remains uncleaned.
Solutions: PV created by JuiceFS CSI is essentially a subdir in JuiceFS, this means all Pods mount the same JuiceFS volume. Data isolation is achieved by writing the data to the subdirectory. Therefore, the issue can be solved by stopping all background tasks of the mount Pods and using another machine to mount the volume to complete background tasks such as automatically cleaning the trash data. This method also eliminates the client performance jitter caused by background tasks.
4.4 The high memory usage
Observations: Some machines that use JuiceFS take up too much memory, up to 20GB+.
Analyses:
1) The output from `cat /proc/$pid/smaps ` shows that it is `Private_Dirty` has occupied the memory, which means that the occupied memory has been held by the JuiceFS for a long term rather than taken up by Page Cache.
2) By analyzing heap usage with the `pprof` tools, dump meta (backup) can be inferred as the cause of the exception.
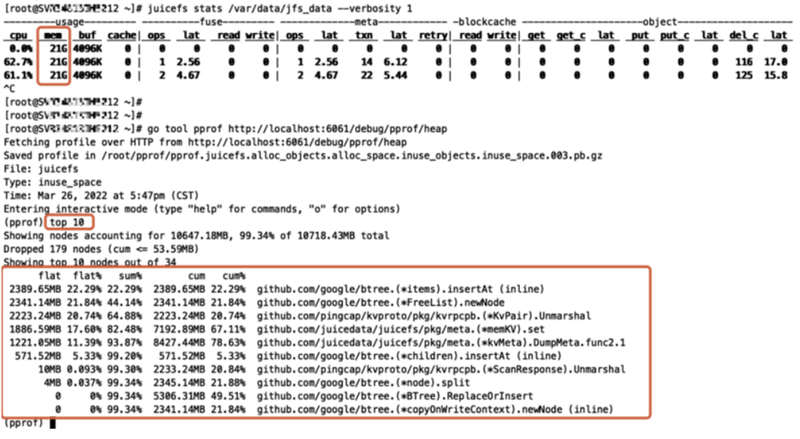
Solutions: Change the default value of the client's startup parameter `backup-meta` to 0. For the implementation of metadata backup, as the client does not perform the metadata backup task, please refer to the official implementation idea and implement it through another component.
4.5 The optimized architecture
Petabytes of data can be involved in various production scenarios. After planning and tuning, the architecture has been optimized as following :
1) For small-scale services, the data from sessions and trash will be managed by the user-mounted JuiceFS client.
2) For large-scale services involving Petabytes of data or/and hundreds of clients, the mounted client does not do the cleaning job for the data from session and trash (with the `no-bgjob` parameter enabled). Instead, the clean-up will be processed by a separate client provided by admin with an acceleration capability.
3) A client that uniformly performs backup-meta operations on all volumes in the same TiKV cluster is provided.
4) The capability to limit OSS and TiKV access is provided, which enables modifying the client access limitations by using commands, protecting private line bandwidth and metadata and achieving service degradation when necessary.
5) Multiple sets of metadata clusters are deployed to isolate services that require different production needs.
6) The TiKV GC can be triggered by services.
5 Summary and Outlook
By uploading cold data to the public cloud through JuiceFS, Elasticsearch achieves a certain degree of separation of storage and computing, eliminates the memory requirement caused by replicas, and improves the overall cluster data storage capacity. Migration of the DBA backup data from GlusterFS to JuiceFS effectively improves the overall performance including `ls`. Consequently, the dedicated O&M staff are no longer needed for disk expansion and maintenance, which greatly reduces the O&M costs, and users can easily control storage costs based on retention time.
At present, 2 PB data from ElasticSearch and the DBA backup have been stored on JuiceFS with more data coming in the future. Meanwhile, further investigation and optimization are needed continuously such as:
1) Further optimization of the performance of metadata engine TiKV and the stability of JuiceFS in order to cope with 10 PB+ data
2) Exploration of the use of JuiceFS on ClickHouse cold data storage
3) How to reduce the storage costs on the cloud in the public cloud scenario where replacing HDFS with JuiceFS.