















About Author:
Haifeng Chen, developer of Apache HBase for cloud database at Mobile Cloud-China Mobile. He has a keen interest in Apache HBase, RBF, and Apache Spark.
About “Mobile Cloud”
"Mobile Cloud" (https://ecloud.10086.cn/), which belongs to China Mobile, the largest wireless carrier in China, provides basic resources, platform capabilities, software applications and other services to governments, institutions, developers and other customers based on cloud computing technology.
HBase on Object Storage
Apache HBase (hereinafter referred to as HBase) is a large-scale, scalable, distributed data storage service in the Apache Hadoop ecosystem. It is also a NoSQL database. It was originally designed to provide random, strongly consistent, real-time queries for billions of rows of records containing millions of columns. By default, HBase data is stored on HDFS, and HBase has made many optimizations for HDFS to ensure stability and performance. However, maintaining HDFS itself is not easy at all. It requires constant monitoring, maintenance, tuning, scaling, disaster recovery and a series of other things, and the cost of building HDFS on the public cloud is also quite high. In order to save money and reduce maintenance costs, some users use S3 (or other object storage) to store HBase data. The use of S3 saves the trouble of monitoring operations and maintenance, and also achieves the separation of storage and computation, making it easier to scale up and down HBase.
However, accessing HBase data to object storage is not an easy task. On the one hand, object storage has limited functionality and performance, and once data is written to object storage, the data object is immutable; And on the other hand, there are natural limitations in using file system semantics to access object storage. When using Hadoop's native AWS client to access the object storage, renaming performance is bad because it’ll traverse the entire directory of files for copying and deleting. In addition, renaming operations can also lead to atomicity problems, where the original renaming operation is broken down into two operations: copy and delete, which can lead to inconsistent user data views. A similar case is to query the total size of all files in a directory. The principle is to get all files of a directory sequentially by traversing iterations. If the number of subdirectories and files in a directory is large, querying the total size of all files in the directory is more complex and has worse performance.
Solution Selection
After a lot of research and community issue tracking, there are currently three options for us to access HBase data to object storage.
The first is that HBase uses the Hadoop native AWS client to access the object store, S3AFileSystem. And the HBase kernel code needs only minor changes to use S3AFileSystem. The community has optimized StoreFIle to address some of the rename performance issues. Completely solving the directory performance problem required a major change to the HBase kernel source code.
The second solution is to introduce Alluxio as cache, which not only greatly improves read and write performance, but also introduces file metadata management, which completely solves the problem of low performance of directory operations. The seemingly happy ending has many constraints behind it. When Alluxio is configured to use only memory, directory operations take ms-level time. If Alluxio's UFS is configured, metadata operations in Alluxio have two steps: the first step is to modify the state of the Alluxio master, and the second step is to send a request to the UFS. As you can see, metadata operations are still not atomic, and their state is unpredictable when the operation is being executed or any failure occurs. Alluxio relies on UFS to implement metadata operations, such as renaming files that become copy and delete operations. File operations in HBase will penetrate to object storage , and Alluxio cannot solve the directory operation performance problem.
The third option is to introduce JuiceFS, a shared file system between HBase and object storage. file data will be persisted in the object store (e.g., Mobile Cloud EOS), and the corresponding metadata can be persisted in various databases such as Redis, MySQL, etc. on demand. In this solution, directory operation is done in Metadata Engine, and there is no interaction with the object storage, and the operation time is at ms level. However, since the JuiceFS kernel is written in Go language, it poses some challenges for post-performance tuning and daily maintenance.
Weighing the pros and cons of the above three solutions, we finally adopt JuiceFS as the solution for HBase. The following discussion focuses on the practice and performance tuning of JuiceFS.
Solution Introduction
JuiceFS consists of two main components: the Metadata Service and the Object Storage. The JuiceFS Java SDK is fully compatible with the HDFS API and also provides FUSE client mounts that are fully POSIX-compatible.
As a file system, JuiceFS handles data and its corresponding metadata separately, with the data stored in the object store and the metadata stored in the metadata engine. In terms of data storage, JuiceFS supports almost all public cloud object storage, and also supports OpenStack Swift, Ceph, MinIO and other open source object storage that support private deployments. In terms of metadata storage, JuiceFS adopts multi-engine design and currently supports Redis, TiKV, MySQL/MariaDB, PostgreSQL, SQLite, etc. as metadata engines.
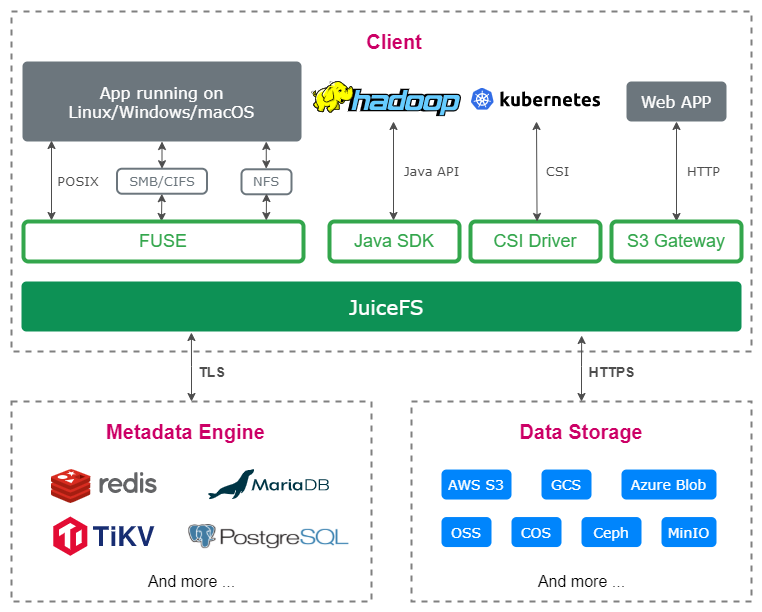
Each file stored in JuiceFS is split into one or more "Chunk"(s) with the size limit of 64 MiB. Each Chunk is composed of one or more "Slice"(s). The purpose of Chunk is to divide large files and improve performance, while Slice exists to further optimize different kinds of write operations, they are both internal logical concept within JuiceFS. The length of the slice varies depending on how the file is written. Each slice is then divided into "Block"(s) (size limit to 4 MiB by default).
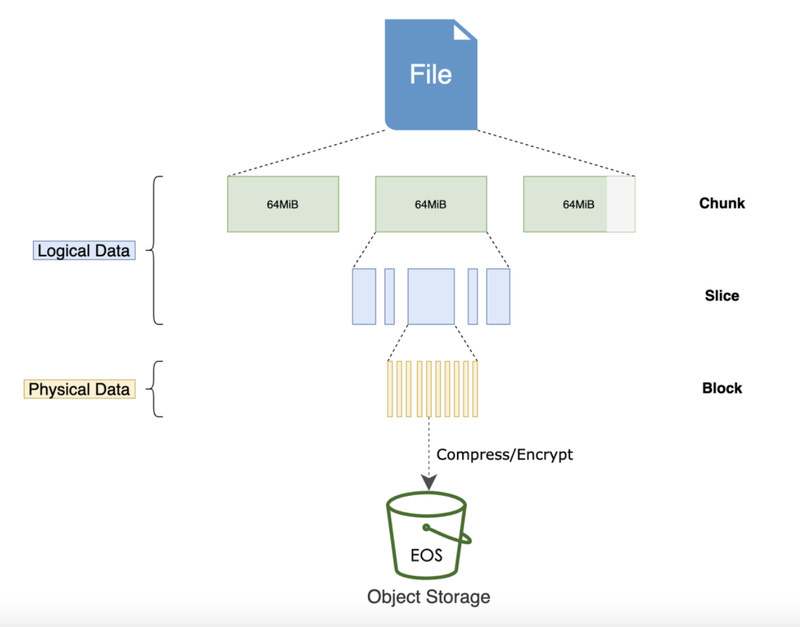
Blocks will be eventually stored in object storage as the basic storage unit, that's why you cannot find the original files directly in the object storage, instead there's only a chunks directory and a bunch of numbered directories and files in the bucket, don't panic, this is exactly how JuiceFS formats and stores data. At the same time, file and its relationship with Chunks, Slices, and Blocks will be stored in metadata engines. This decoupled design is what makes JuiceFS a high-performance file system.
The following configuration is required for the HBase component to use JuiceFS. First, place the compiled client SDK in the HBase classpath. Second, write the JuiceFS-related configuration to the configuration file core-site.xml, as shown in the following table. Finally, use the JuiceFS client to format the file system.
| Configuration items | Default Value | Description |
| fs.jfs.impl | io.juicefs.JuiceFileSystem | Specify the storage implementation to use, the default is jfs:// |
| fs.AbstractFileSystem.jfs.impl | io.juicefs.JuiceFS | |
| juicefs.meta | Specify the metadata engine address of the pre-created JuiceFS file system. |
--storage: sets the storage type, such as mobile cloud EOS.
--bucket: sets the Endpoint address of the object storage.
--access-key: sets the object storage API access key Access Key ID.
--secret-key: set the Object Storage API access key Access Key Secret.
juicefs format --storage eos \ --bucket https://myjfs.eos-wuxi-1.cmecloud.cn \ --access-key ABCDEFGHIJKLMNopqXYZ \ --secret-key ZYXwvutsrqpoNMLkJiHgfeDCBA \ mysql://username:password@(ip:port)/database NAMFor metadata storage, MySQL is used as the metadata engine. The format file system command is as follows. As you can see, formatting the file system requires the following information.
Solution Validation & Optimization
After the introduction of JuiceFS usage, we started the test work. In the test environment, a 48-core server with 187G memory is used. In the HBase cluster, there are one HMaster, one RegionServer and three zookeepers respectively. three nodes of MySQL with master-slave replication are used for the Metadata engine. mobile cloud object storage EOS is used for object storage, and the network policy is public network. chunk size of JuiceFS is 64M, physical storage block size is 4M, no cache, and MEM is 300M.
We built two HBase clusters, one is HBase directly onto the object storage, and the other is JuiceFS introduced between HBase and object storage. Sequential write and random read are two key performance indicators of HBase clusters, and these two performance indicators are tested using PE testing tools. The test read and write performance is shown in the following table.
| Cluster environment HBase-JuiceFS-EOS (row/s) | Cluster environment HBase-EOS (row/s) | |
|---|---|---|
| Sequential write | 79465 | 33343 |
| random read | 6698 | 6476 |
According to the test results, the cluster sequential write performance improves significantly with JuiceFS, but the random read performance does not. The reason is that write requests are written to the Client memory buffer and returned, so generally speaking, the Write latency of JuiceFS is very low (tens of microseconds level). In sequential reads, the data fetched in advance will be accessed by subsequent requests, and the Cache hit rate is very high, so the read performance of the object storage can be fully exploited. However, in random reads, JuiceFS pre-fetch is not as efficient, and the actual utilization of system resources decreases due to read amplification and frequent writes and evictions from the local Cache.
In order to improve random read performance, two directions can be considered. One is to increase the overall capacity of the cache as much as possible in order to achieve the effect of being able to cache the required data almost completely, which is not a very feasible optimization direction in a massive data usage scenario.
The other direction is to deepen the JuiceFS kernel and optimize the read data logic. The optimizations we have done so far include.
1) disabling the pre-reading mechanism and caching function to simplify the read data logic.
2) Avoiding caching entire blocks of data as much as possible and using Range HTTP requests more often.
3) setting a smaller block size.
4)Improve the read performance of object storage as much as possible. After testing in R&D environment, the random read performance is improved by about 70% after optimization.
Combined with the previous test work, after using JuiceFS combined with the object storage solution, HBase can obtain the same read and write performance as data stored in HDFS, but the user cost is only less than half of the data stored in HDFS.