















01 The increasing cost brought by the widespread use of Elasticsearch
Elasticsearch (hereinafter referred to as "ES") is a distributed search engine, and can also be used as a distributed database, often used in log processing, analysis and search scenarios; ELK solution composed of Elasticsearch、 Logstash and Kibana is easy to use, fast, and provides rich visualization; ES can also be easily scaled horizontally ; And supports sharding and replication.
With its ease of use and ecosystem, ES is widely adopted by enterprises . But ES can consume many physical resources and add to costs , thus reducing the cost of ES has become a common concern.
How to reduce ES cost
The main cost of ES is the hardware cost, which is divided into two parts:Computating and storage resources.Computing resources can be simply deemed as CPU and memory, if the number of CPUs and hosts is reduced,the computing capacity will be reduced; Thus, ES typically use high-spec machines for hot nodes and use low-spec machines for cold nodes; But don’t make too much memory reduction, as it decreases ES performance. For code nodes, we prefer using lower frequency CPUs, or older hardwares.
The storage cost is much higher than the cost of computation. Now the storage medium is usually SSD and HDD, cloud vendors’ SSD cost is 0.8 yuan / G, HDD cost is 0.35 yuan / G, the price of object storage is 0.12 yuan / G. But SSD/HDD are block devices, not compatible with the S3 protocol.
We’ve studied two possible options on combining object storage and ES.
The first option is to modify the ES storage engine and directly use object storage. This approach requires modifying the source code of ES, and the team has to invest a lot of manpower to do development, design, research and final validation. The ROI is quite low.
The second option is to use the object store as a disk and mount it to the OS. The ES is divided into hot and warm nodes. Hot nodes store hot data and are mounted on block devices. While warm nodes use object storage.
02 Selection of File System on Object Storage
There are three main considerations when selecting a file system. The first is functionality, which needs to meet the most basic functional requirements; The second is performance, and the third is reliability. We investigated s3fs, goofys and JuiceFS.
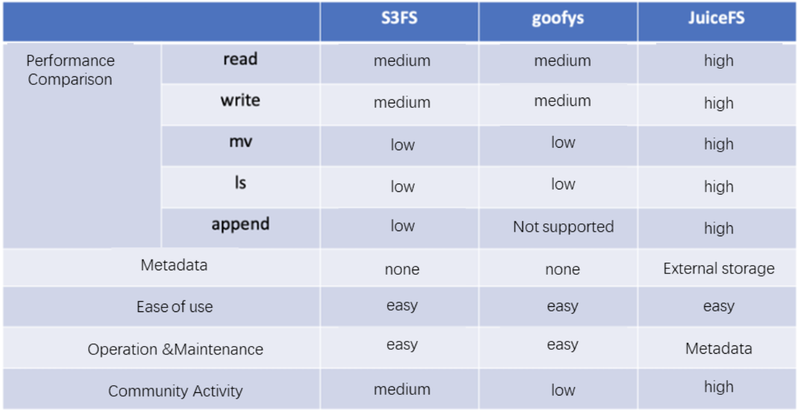
In terms of performance, s3fs and goofys have no local cache for read and write, and their performance is supported by the performance of s3, which is lower than JuiceFS.
Take mv for example, object storage does not support rename operation. Renaming object storage is essentially a copy + delete, which comes with high performance cost.
In terms of ls, due to the Key-Value nature of object storage, directory semantics is not supported, so listing a directory is actually a traversal of the entire metadata for s3, which is very costly . Performance will be poor In big data scenarios.
In terms of metadata, s3fs and goofys do not have their own dedicated metadata engine, all metadata is stored on s3, unlike JuiceFS which has its own dedicated metadata storage.
In terms of ease of use, these products are all very simple and easy to use, they all allow us to mount a cloud storage using a simple command; in terms of maintainability, we need to operate and maintain the metadata service; From the perspective of the community, JuiceFS has the most active open-source community. Based on the above considerations, Kingsoft Cloud chose JuiceFS.
Metadata Engine Test
JuiceFS allows us to use object storage like a local disk, which is exactly what we need when building an ES cluster. JuiceFS has already integrated many kinds of object storage, Kingsoft Cloud's KS3 is also fully compatible, we just need to choose another metadata engine.
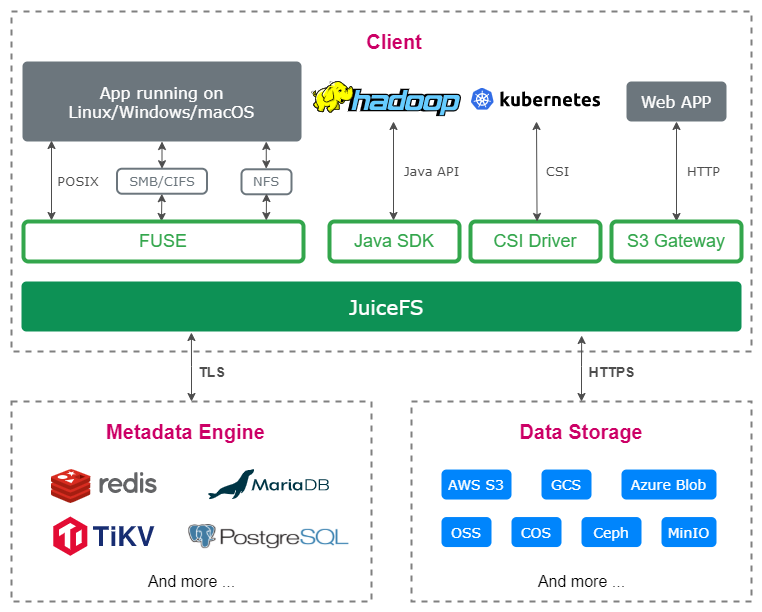
The second thing is to verify functionality. Commonly used metadata engines are Redis, relational database, KV database and so on. We make decisions based on data volume, response speed and maintainability.

In terms of data volume, TiKV is undoubtedly the highest, but our original design intention is to use a single metadata engine for each ES cluster, so metadata is isolated between different clusters for overall high availability.
Secondly, in terms of performance, ES uses JuiceFS as cold node storage, in this case, data IO is the bottleneck, metadata engine performance is not crucial to system design.
From the perspective of management, we are familiar with relational databases, so we eventually choose MySQL.
JuiceFS Reliability Test
After selecting metadata, we tested the reliability of JuiceFS, with below mount steps.
Step 1, create the file system, specify the bucket and the metadata engine.
Step 2, mount the file system to disk.
Step 3, softlink the ES data directory to the JuiceFS mountpoint.
Although the original design was to use JuiceFS as a cold node, during testing, we wanted to test JuiceFS in an extreme way. We designed two extreme tests.
The first one is to mount JuiceFS + KS3 to the hot node and write the data to JuiceFS in real time.
The write process of ES is to write to a buffer,when the buffer is full or reaches the time threshold set by the index, it will be flushed to disk, and the ES segment will be generated.It is composed of a bunch of data and metadata files, and each flush will generate a series of segments, which will generate frequent IO calls.
We test the overall reliability of JuiceFS through this kind of pressure test, and ES itself will have some segment merge. This won’t happen in the warm nodes, we’re simply using it to construct harder tests.
The second strategy is to do the migration from hot data to cold data through lifecycle management.
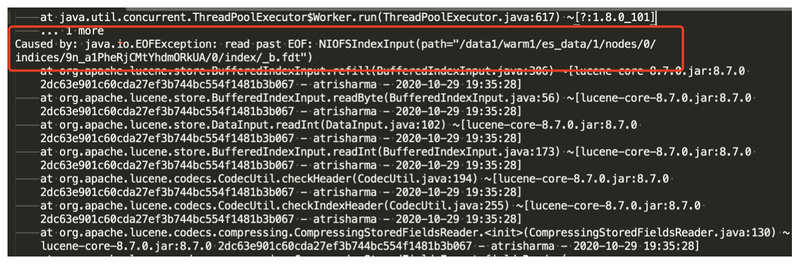
JuiceFS 1.0 was not yet released at the time of testing, and during the testing process, data corruption did occur during real-time writing, and can be solved using below config adjustments:
- attr-cache=0.1 attribute cache length in seconds (default: 1)
- entry-cache=0.1 file-entry cache length in seconds (default: 1)
- dir-entry-cache=0.1 Directory entry cache length in seconds (default: 1)
Reducing cache timeout does solve the problem of index corruption, but not without introducing some new problems: since metadata data cache have shorter timeouts, system API performance drop significantly, APIs which normally return in seconds will take a few dozens of seconds to complete.
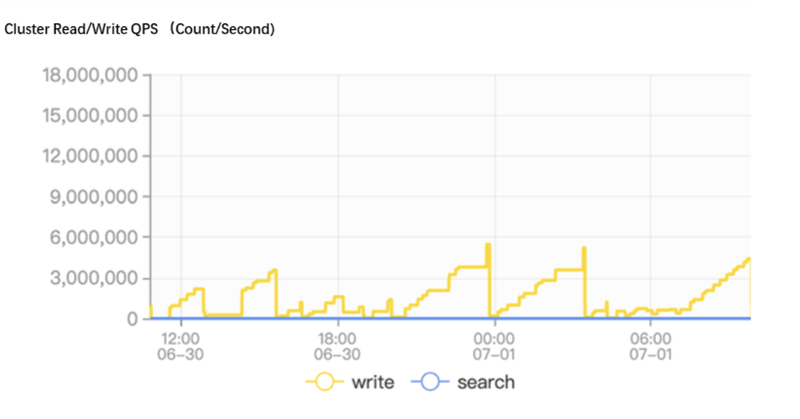
The second problem is that the write QPS dropped significantly. We can see that the Write QPS in the monitor chart is very unstable, which does not represent the real QPS of ES, because the QPS in the monitor chart is obtained by calculating difference between the number of documents, and the ES is reading some old data due to kernel caching issues in the old JuiceFS version. The problem was fixed after JuiceFS 1.0.
We then conducted a new round of testing for 1 week, which uses 3 hot nodes with 8C16G 500G SSD and 2 warm nodes with 4C16G 200G SSD, writing 1TB of data per day (1 copy) and transferring to the warm node after 1 day and no more index data corruption occurred. This pressure test gave us confidence that there were no more known issues, so we gradually migrated the whole ES to this architecture.
Differences between JuiceFS storage and object storage
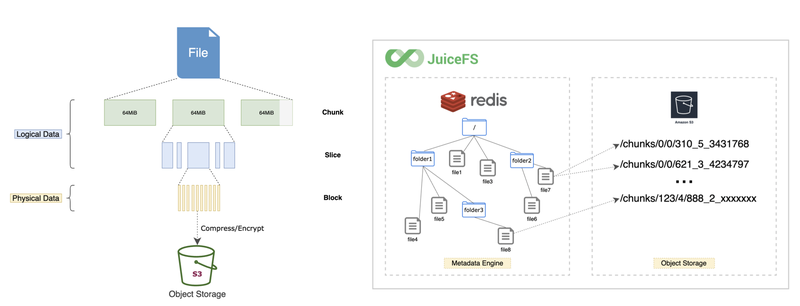
JuiceFS has its own metadata engine, so the directory structure seen in JuiceFS is different from object storage.
JuiceFS splits files into chunks and uploads to object storage, so what we see on the object store is the data chunks created by the split. JuiceFS will properly manage the data blocks in the object storage.
After a series of tests, Kingsoft Cloud adopted JuiceFS in its log service (Klog) to provide enterprise users with one-stop service of data collection, storage analysis and alerting without leaving the cloud; The data under the cloud can be uploaded to the cloud by SDK client. Finally, the data can be delivered to KS3 and KMR for processing.
03 Elasticsearch’s data tier management
ES has several common concepts: Node Role, Index Lifecycle Management, Data Stream.
Node Role, each ES node will be assigned a different role, such as master, data, ingest. Focusing on the data node, the old version is divided into three , hot, warm, cold nodes, in the latest version freeze is added.
There are four phases in Index Lifecycle Management (ILM) .
- hot: the index is being frequently updated and queried.
- warm: The index is no longer being updated, and not frequently queried.
- cold: The index is no longer being updated and is rarely queried. The information still needs to be searchable, but it doesn't matter if the queries are slow.
- delete: The index is no longer needed and can be safely deleted.
ES officially provides a lifecycle management tool that allows users to split a large index into multiple smaller indexes based on the size of the index, the size of the number of docs, and a time policy. A large index is very costly in terms of managing and query performance. The lifecycle management feature allows us to manage indexes more flexibly.
Data Stream is a new feature introduced in version 7.9, which is based on index lifecycle management to implement a data stream write that can easily handle time-series data.
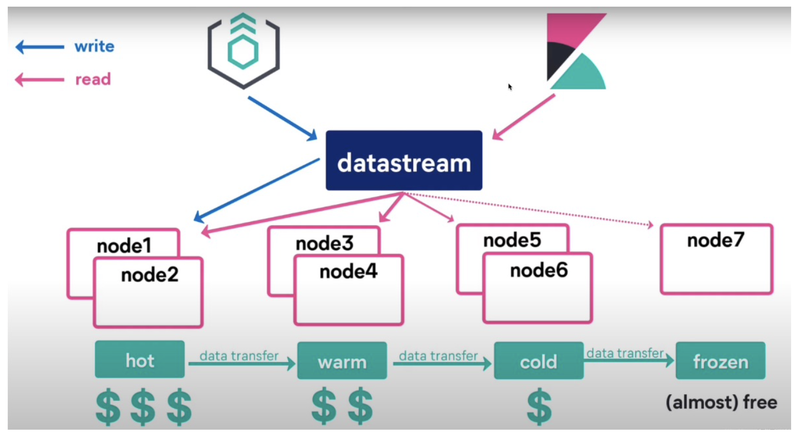
When querying multiple indexes, which are usually combined together, we can use Data Stream, which acts like an alias and can route itself to different indexes.Data Stream is more friendly to the storage management and query of time-series data.
Reasonable planning of cold node size
When we put the cold data on the object storage, it will involve the management of cold nodes, which is mainly divided into three aspects.
First: memory and CPU and storage space. The size of the memory determines the number of slices. We usually assign half of total physical memory to JVM; The other half to Lucene. Lucene is the ES search engine, allocating more memory to it will improve ES query performance. So accordingly, we can assign moreJVM memory and reduce Lucene memory in the cold data node, but the JVM memory should not exceed 31G.
Second: the CPU/memory ratio is reduced from 1:4 to 1:8. when using JuiceFS storage space can be considered to be unlimited. But due to memory limitations, unlimited storage space is not really viable. If it is scaled without limit, the whole ES cluster will have more potential stability issues in cold nodes.
Third: storage space. For 32G of memory, the reasonable storage space is 6.4 TB. The space can be expanded by increasing the number of slices, but in hot nodes, the number of slices is strictly controlled considering stability issues. Better increase this ratio in cold nodes.
There are two key factors to consider, one is the stability and the second is the data recovery time. When the node hangs, such as JuiceFS process crash, or the cold node hangs, then all the data needs to be reloaded into ES, which will generate a lot of frequent read data requests in KS3, and the more data , the longer recovery time will be.
index sharding management methods
There are three main considerations.
- shard is too large: leads to slow recovery after cluster failure; prone to data write hotspots, resulting in full bulk queue and increased rejection rate.
- shard too small: cause more shards, occupy more metadata, affect cluster stability; reduce cluster throughput.
- Too many shards: causes more segments, serious wastes of IO resources, reduces query speed; occupies more memory, affects stability.
When the data is written, the entire data size is uncertain. And usually a template is created first to determine the size of the fixed shard, determine the number of shards, and then create the mapping and the index.
The first problem is that there are excessive slices, because it will be very difficult for users to accurately predict the data scale and may create unnecessary slices.
The second is not enough slices , which will lead to an oversized index. Thus we need to merge the small slices, and then compact small segments into a larger segment to avoid taking up more IO and memory, and delete empty indexes, which will occupy memory. It is recommended to use a slice size around 20-50g.
04 Tips on using JuiceFS
Take an online cluster as an example, data size:
- 5TB written per day,
- 30 days of data storage,
- one week of hot data storage,
- number of nodes: 5 hot nodes, 15 cold nodes.
After adopting JuiceFS, the hot nodes remain unchanged and the cold nodes are reduced from 15 to 10, while we use a 1TB HDD for cache.
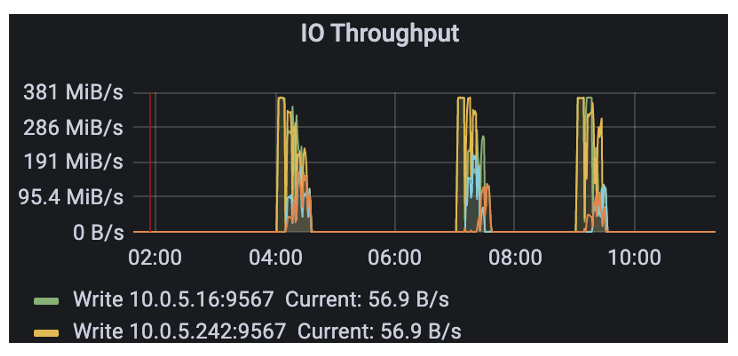
You can see that there are a lot of object storage calls in the early morning, because we put the whole lifecycle management operation to run in the low peak.
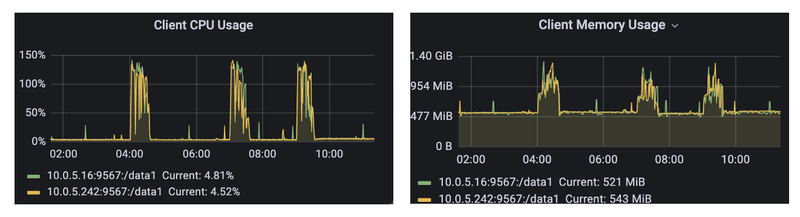
JuiceFS memory usage is usually in the hundreds of MB, and it will be less than 1.5G and its CPU usage at peak times, with no abnormal performance.
Here are some tips on using JuiceFS:
First: no file system sharing. We mount JuiceFS on cold nodes, what we see on each machine is a full amount of data. A more friendly way is to use multiple file systems, one file system for each ES node, which can be isolated, but will bring the corresponding management problems.
The problem with this practice is that each node sees a full amount of data, which is prone to some misuse. If users want to do some rm on it, they may delete the data on other machines, but considering that we do not share the file system between different clusters, but in the same cluster, we should balance the management and operation and maintenance, so we adopt a set of ES corresponding to a JuiceFS file system model.
Second: manually migrate data to warm nodes. In index lifecycle management, ES will migrate data from hot nodes to cold nodes. Policy might execute, at business rush hours, which will generate IO on the hot node, load on hot nodes is high, so we are manually controlling the migration process.
Third: Avoid large indexes. When deleting large indexes, its CPU and IO performance is worse than the hot node, potentially causing node failure.
Fourth: a reasonable slice size.
Fifth: close the recycle bin. JuiceFS enables trash by default, delete files have a 1 day retention period, not really needed in ES.
There are some other operations that involve large amounts of IO to be done at the hot node. For example, index merge, snapshot recovery, and slice reduction, index and data deletion, etc. These operations will cause failure on cold nodes. Although the cost of object storage is relatively low, the cost of frequent IO calls will increase, object storage will be charged according to the number of PUT and GET calls, so it is necessary to put these operations to the hot node.