















In the quantitative investment field, the performance and scalability of the storage system support efficient research and computational tasks. JuiceFS, an open-source high-performance distributed file system, has become the storage backbone for multiple top-tier, billion-dollar quantitative investment firms. It delivers high-performance, cost-effective, and elastically scalable storage infrastructure for their core operations—including backtesting and model training.
This article shares the critical storage challenges faced by quantitative firms and how JuiceFS addresses them. We’ll explore typical case studies focusing on cost optimization, metadata performance improvement, and seamless cloud migration.
Data types and storage challenges in the quantitative industry
First, let's understand the data usage patterns in quantitative research. The programming languages and data processing tools used are diverse, including Python, R, Java, MATLAB, and Conda. The data types involved are very rich, such as CSV, Parquet, TXT, Excel, and HDF. This requires the storage platform to be flexible enough to support various data formats efficiently.
The table below shows common data types in quantitative investing:
| Data type | Data characteristics | Data format | Use case |
|---|---|---|---|
| Order book | GB~TB per day | Parquet, NPY | High-frequency backtesting, market making |
| Tick data | GB~TB per day | Parquet, NPY | High-frequency backtesting |
| K-line / bar data | MB~GB per year | Parquet | Low-frequency backtesting |
| Factor library | Tens of GB~TB per year | Parquet, Feather | Trading reference |
In quantitative investing, data usage exhibits a distinct read-intensive, write-light pattern. Researchers frequently read data from unified data sources, while data writing and updating occur infrequently. Various types of market data and factor data are typically stored centrally and shared for read access by all researchers. Both factor research and trading strategy development involve repeated access and utilization of foundational data. Consequently, storage systems must deliver high-performance read capabilities to support rapid data access and analytical requirements.
This data usage pattern is also fully reflected in the critical task of quantitative research: backtesting. In a typical backtesting workflow, researchers repeatedly read historical market data to construct factors, generate trading signals, and validate strategy performance. Stable factors with strong predictive power are incorporated into factor libraries, serving as critical references for investment decisions.
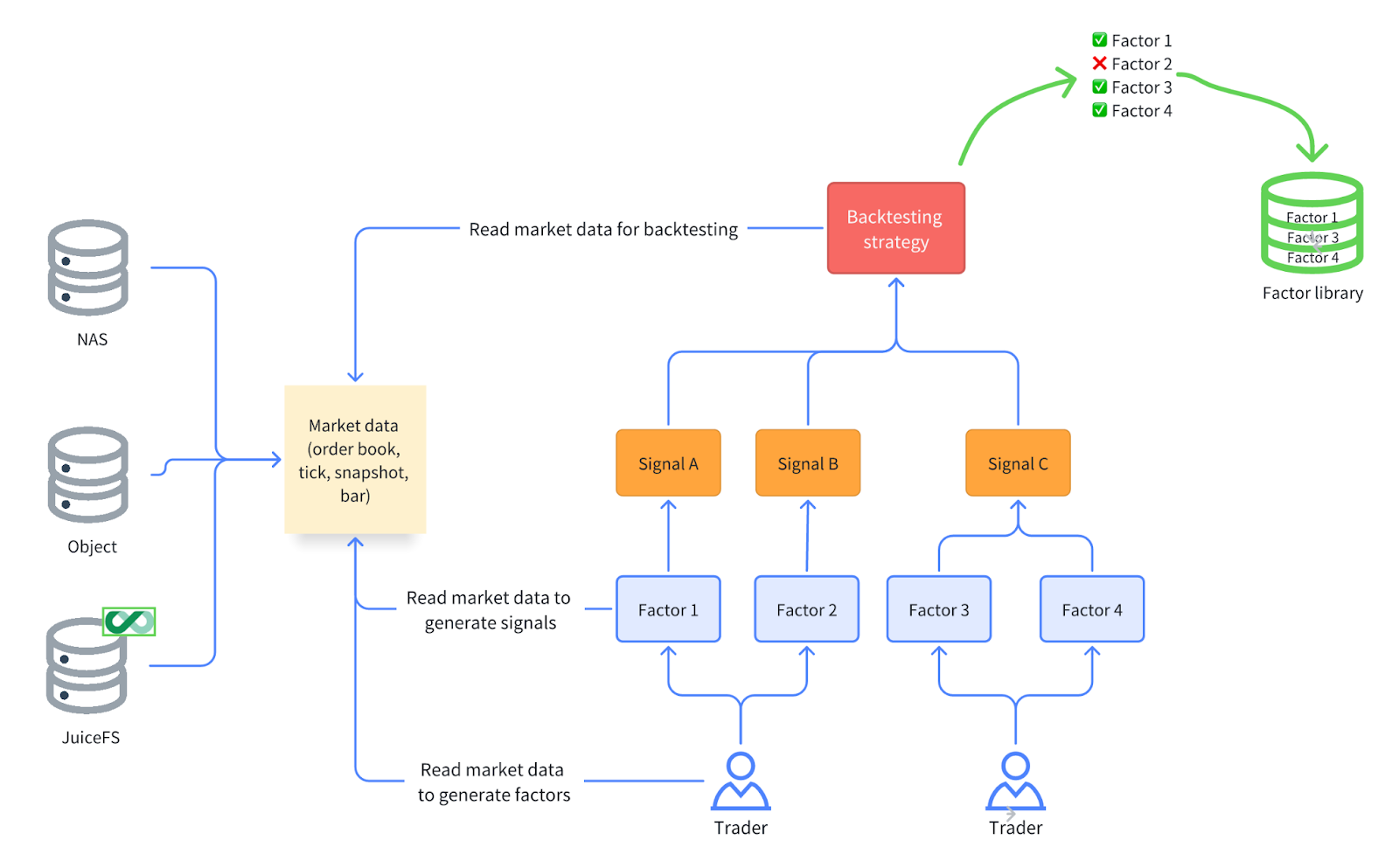
Consequently, storage systems face a series of challenges:
- The ability to handle diverse programming languages and data processing tools.
- The requirement for high performance despite low capacity needs. Although storage capacity requirements typically range from tens to hundreds of terabytes, the performance demands on the storage system are extremely high, particularly regarding throughput and IOPS. Since quantitative tasks involve extensive machine learning and deep learning computations, the storage system must provide efficient sequential read throughput and fast random read IOPS to facilitate rapid data processing and analysis.
- Adaptability to cloud environments. As more quantitative teams adopt public or hybrid clouds to build their technology platforms, storage systems need to possess high availability, elastic scalability, and flexible resource management capabilities. This meets dynamic storage demands and allows for quick adjustment of storage resources based on computational needs.
- Integration with Kubernetes, supporting CSI drivers. This is because Kubernetes has become the mainstream solution for resource orchestration in quantitative research. This integration enhances platform flexibility and scalability and enables more efficient resource management for storage systems in cloud environments.
- Data security and access control requirements. Protecting sensitive information like factor data and trading strategies is a top priority. The storage system must provide strong access control mechanisms to ensure data privacy and security. As more data moves to the cloud, features like encryption, auditing, and compliance management become essential. These measures guarantee that sensitive data remains secure in cloud environments.
Analysis of main storage solutions: NAS vs. object storage vs. JuiceFS
NAS
Many quantitative teams initially choose network-attached storage (NAS) for its out-of-the-box simplicity, typically using NFS or Samba protocols. This works well for data scales from tens to hundreds of terabytes in on-premises data centers. It’s easy to deploy and manage with controllable costs. However, several issues often emerge:
- Cost: High-performance storage in on-premise data centers often requires all-flash NAS systems, which are expensive. Hybrid flash systems (mixing SSD and HDD) often lack the performance for high-concurrency access. This becomes a bottleneck when multiple researchers read data simultaneously.
- Cloud NAS performance tied to capacity: In public cloud environments, the throughput of many NAS or parallel file system products is directly tied to purchased capacity. If a team needs 100 TB of storage but requires high throughput for backtesting (for example, 50+ GB/s reads or millions of IOPS), they might be forced to purchase PB-level capacity. This leads to waste.
- Protocol-level bottlenecks: NAS protocols rely on kernel clients. Under high load, data and metadata competing for the same channel (prior to NFS v4.2) can cause congestion, performance drops, and latency spikes, especially during peak research or backtesting periods.
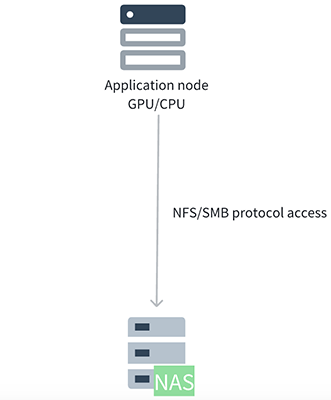
While NAS offers simplicity and good compatibility, its cost, scalability, and high-concurrency performance are significant limitations.
Object storage
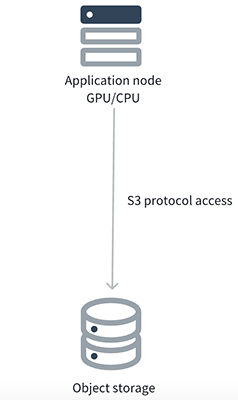
Object storage is a low-cost alternative. While it has higher single-request latency, it handles large sequential reads and writes effectively. Many teams adapt their code for sequential access, but this approach has disadvantages:
- Object storage can only be accessed via the S3 protocol. For applications already using POSIX mount points, migrating to object storage requires code modifications, which introduces intrusion into the existing system. Furthermore, object storage natively lacks efficient metadata management. Due to its flat structure, the response speed for I/O operations is slow, especially for operations like file renaming. Renaming a file essentially requires deleting the original file and creating a copy with the new name, which performs poorly.
- Files on object storage are immutable. This means that if data needs to be modified (for example, adding a column to a Parquet file), it can only be achieved by creating a new file, rather than modifying the original file in place. This immutability can cause significant inconvenience in certain scenarios, such as when dealing with database files.
- Frequent read operations on object storage incur extra data transfer fees. For the high-frequency read/write demands typical in quantitative finance, this can lead to substantial costs. Moreover, although object storage performs well for large sequential throughput, its performance is entirely dependent on the storage system itself. Under high-concurrency access patterns, it may still fail to meet the low-latency and real-time requirements crucial for quantitative research.
JuiceFS
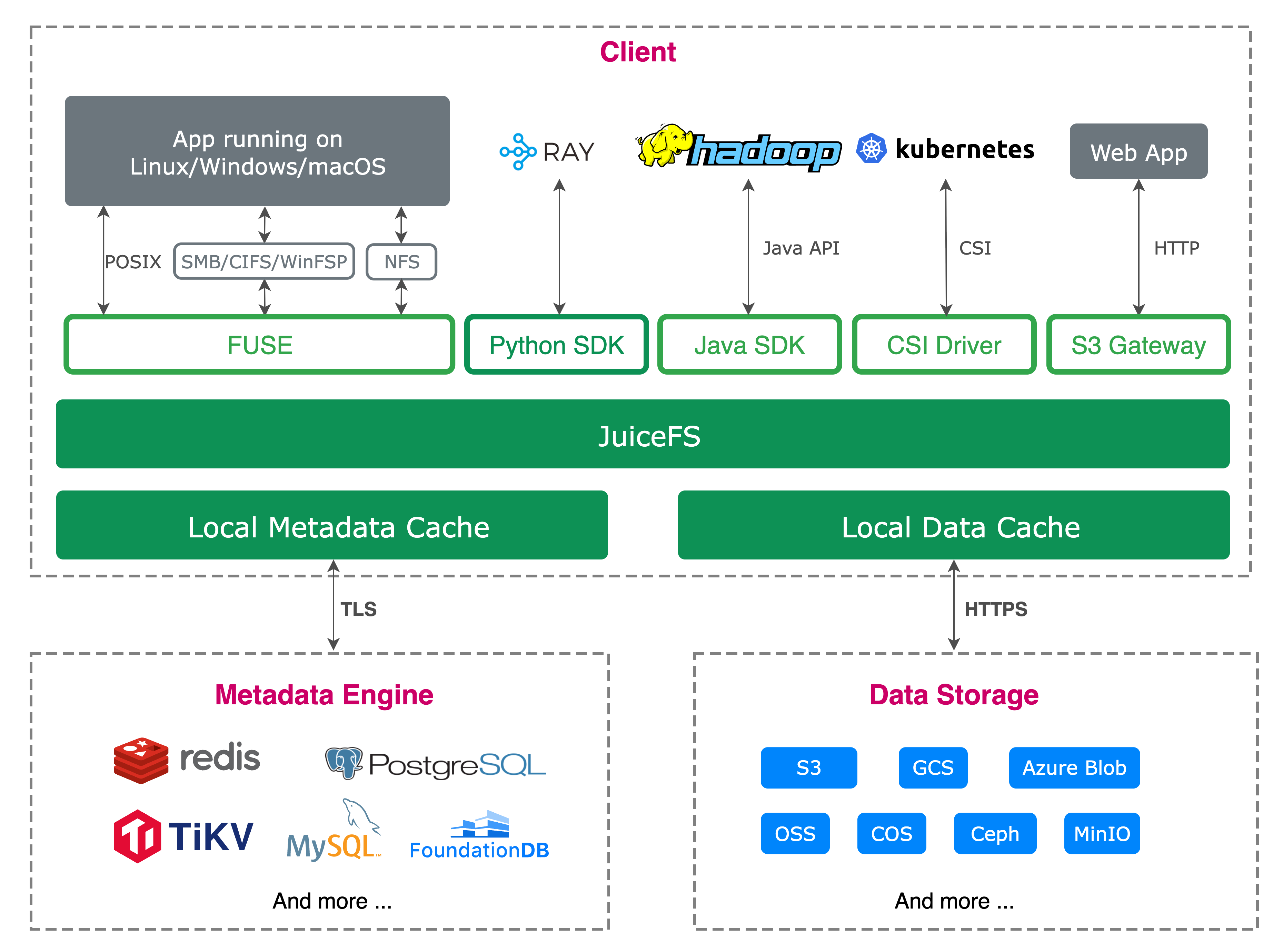
JuiceFS is a POSIX-compatible distributed file system built on object storage. It manages both structured and unstructured data, providing a unified, high-performance storage platform for quantitative research. With CSI Driver support, it integrates deeply with Kubernetes and offers cloud-native flexibility for deployment across public, private, or hybrid cloud environments.
Architecture design
JuiceFS employs a separated architecture for data and metadata management:
- Data is split into chunks and stored in object storage.
- Metadata is handled by a dedicated engine and cached in memory.
This design delivers significant performance improvements. File metadata operations—including rename, lookup, and getattr—avoid frequent access to underlying storage. The system achieves high throughput, low latency, and high IOPS performance.
Security and access control
JuiceFS provides comprehensive security features:
- Token-based access control
- POSIX ACL support
- Data encryption during transmission and at rest
- Data chunking in object storage and cache for enhanced security and compliance
Product editions
JuiceFS offers two editions:
- Community Edition: Users select their preferred metadata engine for scenario flexibility.
- Enterprise Edition: Includes high-performance metadata service and distributed caching for demanding workloads.
Deployment process
Users deploy JuiceFS through a simple process:
- Download and install the JuiceFS binary.
- Mount using the
juicefs mountcommand. - Access via POSIX mount points.
This approach maintains compatibility with existing applications, working like a local file system.
Advantages for quantitative research
This architecture delivers significant advantages for the quantitative industry:
- High throughput and IOPS support: Data usage patterns in quantitative research are typically read-heavy write-light. Especially for tasks like backtesting and factor research, frequent reading of large datasets is required. JuiceFS' chunk-based storage and efficient multi-level data caching provide high throughput and IOPS support. This meets the demanding data access requirements of quantitative research.
- Elastic scaling and cost reduction: Quantitative research often faces dynamic storage demands. JuiceFS inherently provides elastic scaling, allowing it to dynamically adjust storage and cache resources based on requirements. By using object storage as the underlying architecture combined with distributed caching, JuiceFS significantly reduces storage costs and avoids the high expense of all-flash storage.
- Data security: In quantitative investing and research, factor data and trading strategies are core assets, and they are very important. JuiceFS effectively ensures data security through data chunking and encryption mechanisms. Particularly for institutions hesitant about moving to the cloud, this chunking and encryption strategy significantly reduces the risk of data leakage. Even if partial data is intercepted, attackers cannot reconstruct the original content without the metadata. This ensures the security and compliance of sensitive information.
- Cloud environment compatibility: With the increasing adoption of cloud computing and public clouds, quantitative research is gradually migrating to cloud environments. JuiceFS supports cross-cloud synchronization and can operate efficiently in multi-cloud or hybrid cloud environments. This provides greater flexibility and scalability for quantitative research.
For on-premises quantitative firms, JuiceFS is also a viable and efficient choice. Traditional on-premises storage often uses hybrid flash or hard disk drives. Their performance often cannot meet the high-concurrency demands of quantitative research. By fully utilizing the local cache disks of application nodes and an efficient caching mechanism, JuiceFS can achieve performance close to all-flash at a low cost, significantly reducing hardware investment. Its operational simplicity and proven stability ensure reliable performance with light maintenance, as confirmed by customer feedback.
Case studies
Enhancing object storage performance and reducing costs
To further reduce storage costs, one of our customers migrated data to object storage. In their backtesting operations, they initially used a self-developed interface to directly access Amazon S3 object storage via the S3 API. While this solution could handle their primary workload of writing large data blocks and performing sequential reads—even without caching—it had several notable drawbacks.
Using the S3 API was intrusive to the application code. This means that if API issues arose, debugging and maintaining the application code would become very difficult. In addition, this API didn't implement caching and only handled protocol conversion. This imposed certain performance limitations. For these reasons, the application team didn't want to rely on this model for a long time.
To improve this situation, the company decided to migrate to JuiceFS Enterprise Edition. After migration, the application code no longer depended on the S3 API. JuiceFS, as a rich client, was directly mounted on the application nodes. This approach made the application code almost non-intrusive, allowing developers to continue compiling and running code in the original way. Meanwhile, the NVMe drives in the application nodes were used as distributed cache. This effectively optimized data access efficiency.
Using JuiceFS brought significant performance improvements. This enabled the client to achieve high-performance read/write operations on low-cost object storage:
- Local cache avoided repeated access to remote storage. This significantly reduced read latency.
- JuiceFS’ chunking and readahead mechanisms fully utilized object storage bandwidth. They enabled even single-file reads to reach system performance limits.
Overall, the migrated system showed noticeable improvements in both performance and maintenance convenience.
This company’s neural network training tasks also benefited from JuiceFS optimizations. During training, the system read approximately 100,000 files (each about 24 MB) and repeatedly read them after random shuffling. Without caching, each training epoch required reloading all files, generating massive network traffic. After implementing JuiceFS, data from the first read was automatically cached locally. This allowed subsequent training to directly fetch data from the cache pool. Bandwidth usage dramatically reduced and the overall training efficiency significantly improved. This fully met the company’s storage requirements for training.
Extremely high metadata demands
Another customer primarily uses JuiceFS for backtesting operations. They purchase market data from external sources, typically in CSV format, and store it in directories. Unlike other customers who aggregate data, this company stores raw data directly in folders. This creates a heavier data access burden. Historical market data for each stock is stored separately, with each file representing one year of data for a single stock. These files are distributed across different directories by month and year. Each time market data for a specific date needs to be read, the system must randomly read and process about 6,000 files and then arrange these files in sequence. To support backtesting, this data is used to launch hundreds of virtual machines, running 4,000 to 6,000 backtesting tasks.
This process of randomly reading large numbers of files placed enormous pressure on the storage system, particularly in high-concurrency read/write scenarios where metadata access efficiency severely impacted overall performance. The company initially used JuiceFS Community Edition combined with cloud-based Redis service to cache some data. While Redis provided good performance, its QPS limit of 500,000 couldn't meet the demands of the company’s high-concurrency backtesting tasks. When backtesting tasks reached 12,000, Redis performance hit a bottleneck. This caused the entire system to slow down significantly and prevented completion of backtesting tasks.
To solve this problem, the company tried JuiceFS Enterprise Edition. The metadata service in the Enterprise Edition showed significant performance improvements, particularly in handling large volumes of metadata requests with higher concurrency support. The Enterprise Edition's metadata service adopts a directory-tree based management approach and provides more efficient request processing. Customers no longer need to request multiple operations through key-value storage; instead, they simply inform the metadata system to read files through simple requests. The per-request processing efficiency of the Enterprise Edition metadata service is approximately 6 times that of the Community Edition. This means that for the same application operations, the required QPS is only one-sixth of the Community Edition's requirement. This results in higher overall execution efficiency.
In addition, JuiceFS Enterprise Edition provides a more powerful metadata client caching mechanism: numerous read-only requests (such as getattr and lookup) can directly hit the cache, significantly reducing the access pressure on the metadata service.
As shown in the figure below, the system handled about 500,000 QPS of read-only metadata requests, with only about 40,000 actually reaching the metadata server. Combined with the efficient processing capability of the Enterprise Edition metadata service, the overall system maintained stable operation in high-concurrency scenarios, with CPU utilization at only about 40%, enabling the company to stably support up to 12,000 backtesting tasks.
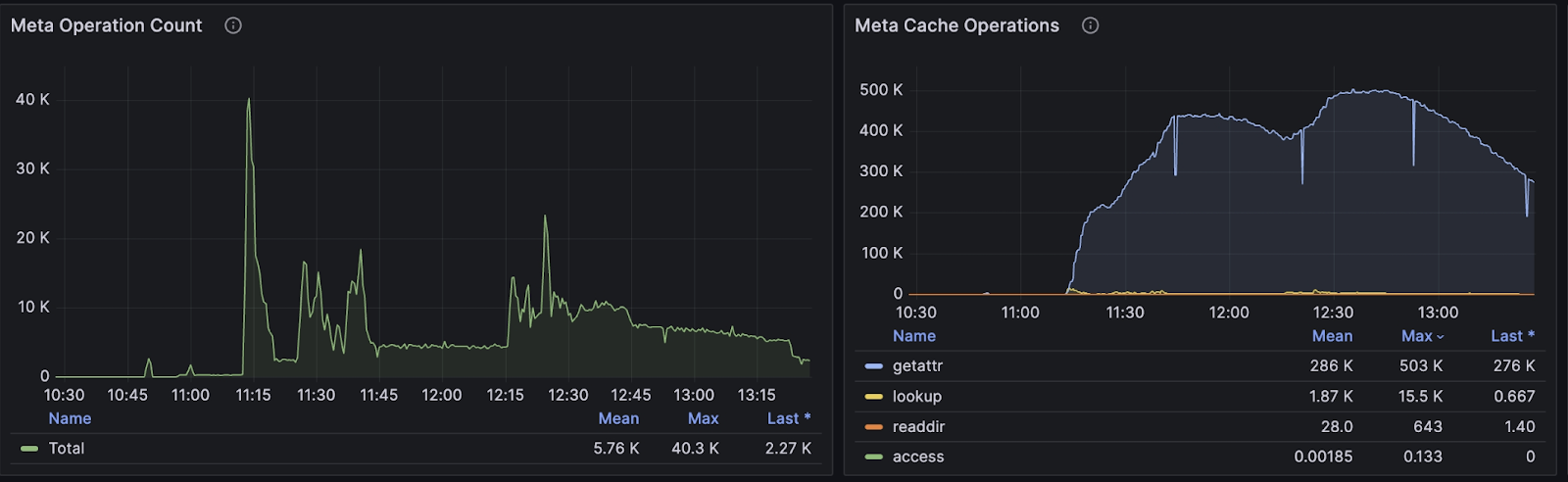
From this case, we can see that JuiceFS Enterprise Edition effectively addresses the challenges of high-concurrency read/write operations, high IOPS, and a lot of metadata requests in the quantitative industry. Even without optimizing for specific application scenarios, JuiceFS efficiently handles these intensive operational demands. It meets the quantitative industry's stringent requirements for data access speed and responsiveness.
Overcoming cloud NAS IOPS bottlenecks
In this case, our customer faced cloud storage performance issues when migrating their application to the cloud. They initially used cloud NAS to support their storage needs but quickly discovered that as the application expanded, the cloud NAS performance couldn't meet IOPS requirements. While using cloud NAS, the company’s 120 nodes already saturated the IOPS limits of standard cloud NAS. Even using high-speed cloud NAS (providing about 200,000 IOPS) still couldn't fully meet performance demands.
To address this bottleneck, the company decided to switch to JuiceFS. Through JuiceFS' distributed caching, the company could aggregate more IOPS performance. Theoretically, 5 cache nodes could provide 200,000 IOPS each. With local hard drive support, they could ultimately deliver over 1 million IOPS. This approach allowed the company to flexibly combine cache resources and scale storage performance on demand.
In extreme scenarios, the company achieved 7.5 GB/s throughput and nearly 3 million IOPS. This was sufficient to handle large-scale random read/write scenarios. Specifically, the company could increase throughput by adding network bandwidth and improve IOPS performance by increasing the number of cache nodes. Each cache node can provide about 100,000 to 200,000 IOPS. The company can also expand capacity by mounting additional hard drives or utilizing memory as needed. This allows the company to freely combine and adjust cache pool capabilities according to actual application requirements, ensuring system performance.
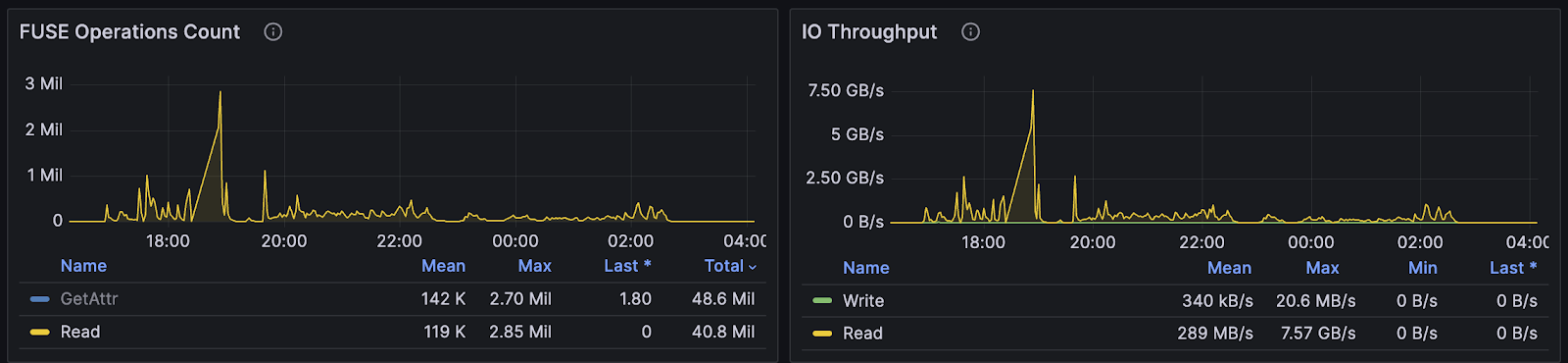
Summary
Based on the multiple cases discussed above, we can summarize several distinctive characteristics of quantitative research regarding storage:
- Quantitative applications typically have small data volumes but extremely high performance requirements. JuiceFS significantly improves access efficiency through data and metadata separation and caching mechanisms. Even without caching, it can fully utilize bandwidth through readahead and data chunking upload mechanisms. This ensures high-performance data processing capabilities.
- JuiceFS' data chunking and encryption mechanisms enhance cloud storage security. Data is split into chunks and encrypted before storage. Even if partial data is stolen, attackers cannot reconstruct the files without metadata. This design is particularly suitable for protecting sensitive data like quantitative factors and trading strategies.
- As quantitative applications gradually migrate to cloud environments, JuiceFS provides a solution that balances performance and cost. It achieves high-performance access and unified management on top of object storage. This meets diverse computing needs in public and hybrid cloud environments and builds scalable, reliable data infrastructure for quantitative institutions.
If you have any questions for this article, feel free to join JuiceFS discussions on GitHub and community on Slack.