















Douban.com is a leading Chinese social networking platform where users can share their interests, discover new content, and connect with others who share similar passions. As of June 2021, it had 230 million registered users.
Previously relying on the DPark+Mesos+MooseFS architecture, we made the strategic decision to migrate our infrastructure to the cloud and decouple storage from compute. The new data platform architecture, powered by Spark+Kubernetes+JuiceFS, brings simplified storage management, improved query efficiency, and streamlined resource allocation and utilization.
In this post, we’ll deep dive into our previous data platform architecture, the challenges we faced, the benefits of our new platform, and our future plans.
Previous data platform architecture at Douban
In 2019, our data platform consisted of the following components:
- Operating system: Gentoo Linux
- Distributed file system: MooseFS
- Cluster resource management: Apache Mesos
- Distributed computing framework: Dpark
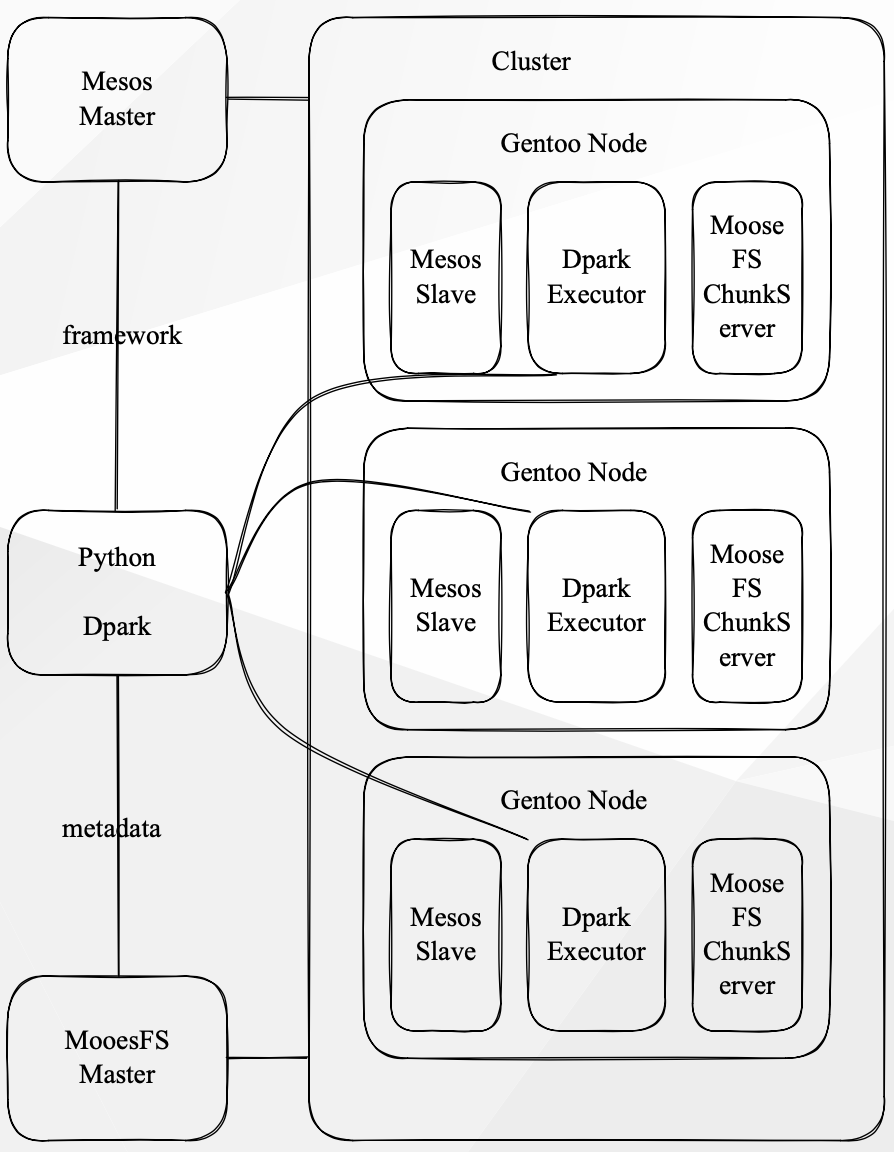
In this platform:
- Computing and storage were integrated.
- Mesos scheduled computing tasks.
- I/O operations of computing tasks fetched metadata through the MooseFS Master and obtained required data locally.
- Mesos managed the GPU computing cluster.
- The GPU was shared based on its memory.
Gentoo Linux
Gentoo Linux is an open-source operating system based on the Linux kernel.
Advantages:
- Offers customization options by allowing users to build software packages from source code.
- Enables easy adaptation and customization to meet specific requirements.
- Provides a wide range of software packages for users to choose from.
Disadvantages:
- The frequent rolling updates might introduce instability, especially in server environments.
- Creating customized packages brought about high maintenance costs.
- Dependency conflicts might arise as not all packages adhere to dependency description conventions.
- The small user community resulted in limited testing and support availability.
MooseFS
MooseFS is an open-source, POSIX-compatible distributed file system. It exclusively uses filesystem in userspace (FUSE) as the I/O interface and features fault tolerance, high availability, and scalability.
We used MooseFS as a replacement for standard file systems. To enhance its capabilities, we developed ShadowMaster for metadata backup and created analysis tools for MooseFS metadata. Overall, MooseFS demonstrated stability and reliability as a storage solution.
Apache Mesos
Mesos is an open-source cluster manager. It differs from YARN by providing a framework for fair resource allocation and isolation, such as CPU or memory. Mesos was adopted by Twitter in 2010, and IBM started using it in 2013.
Dpark
We used a Python-based version of Spark called Dpark. It extends the resilient distributed datasets (RDD) API and provides DStream functionality. We developed in-house tools to submit bash scripts or data tasks to the Mesos cluster using Dpark. We also used these tools to submit MPI-related tasks.
While Dpark could be containerized, we mainly ran our data tasks on bare metal servers. Supporting containerization would allow better utilization of online applications’ model code for in-house tasks.
Challenges for the previous architecture
We encountered the following issues with our previous architecture:
- The integrated computing and storage setup lacked flexibility.
- As our computing tasks ran on bare metal servers, we faced increasing dependency conflicts and maintenance challenges over time.
- The data stored on the platform was in row-based format, resulting in low query speed.
Therefore, we decided to build a new platform to address these issues.
Our requirements for the new platform
We looked for a new platform solution that matched the following requirements:
- We wanted to move our infrastructure to the cloud and separate compute from storage.
- The in-house platform should integrate with our existing big data ecosystem, beyond just processing text logs or unstructured/semi-structured data.
- It should enhance query efficiency.
We didn’t think that compatibility with the old platform was essential. If the cost-benefit was reasonable, we were open to a complete replacement. During the transition, if we found that some tasks from the old platform couldn’t be replaced, we would keep them temporarily.
Our requirements during the platform migration were as follows:
- Python must be the top priority programming language.
- The FUSE interface must be retained, and a direct switch to HDFS or S3 was not preferred.
- We aimed to unify the infrastructure as much as possible. Since we had already adopted Kubernetes to some extent, we ruled out Mesos or other alternatives.
- The learning curve for the new platform should be minimal, allowing the data and algorithm engineers to switch to the new computing platform with ease and at a low cost.
New data platform built on the cloud
We made several enhancements to our data platform:
- We migrated from Gentoo Linux to a containerized environment based on Debian, improving the development environment.
- We replaced MooseFS with JuiceFS as our file system, enhancing storage capabilities.
- Kubernetes became our resource management solution, streamlining resource allocation and utilization.
- We adopted the Spark framework for developing computing tasks, enabling efficient and scalable data processing.
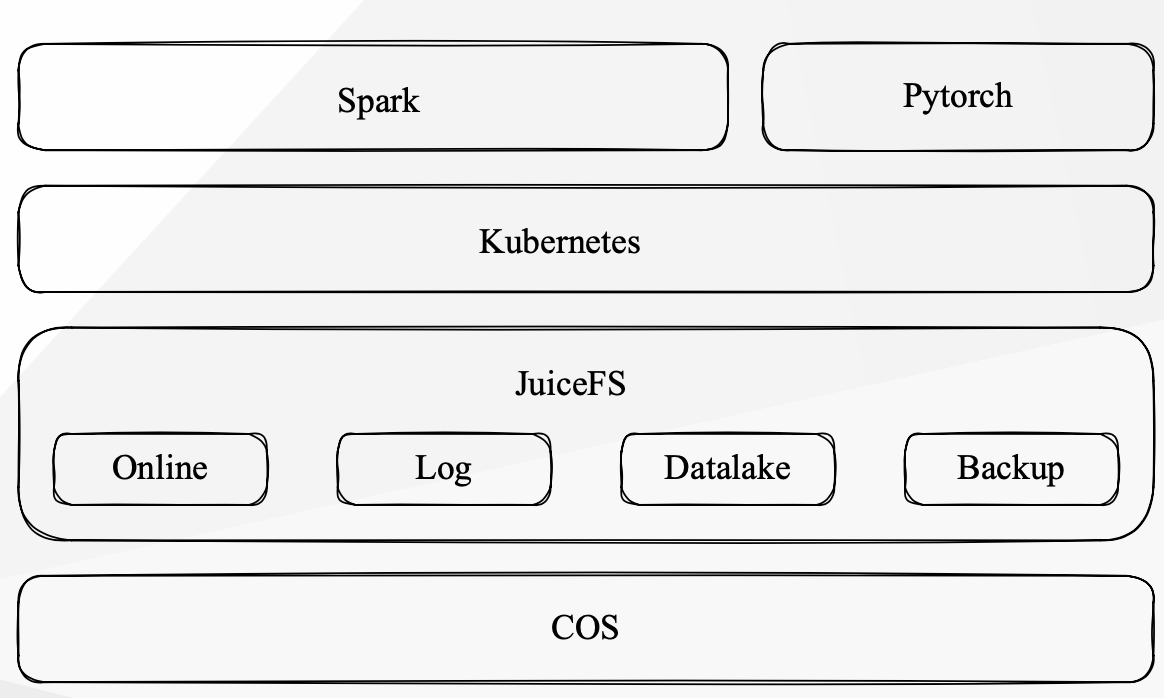
JuiceFS as a unified data storage platform
JuiceFS is a high-performance distributed file system designed for the cloud. As a unified data storage platform, it is designed to meet diverse I/O requirements and prioritize security considerations.
We created different JuiceFS volumes with specific configurations to cater to various usage scenarios. Compared to MooseFS, JuiceFS offers simplified file system creation and on-demand provisioning. Except for our SQL data platform, most of our use cases are supported by JuiceFS services.
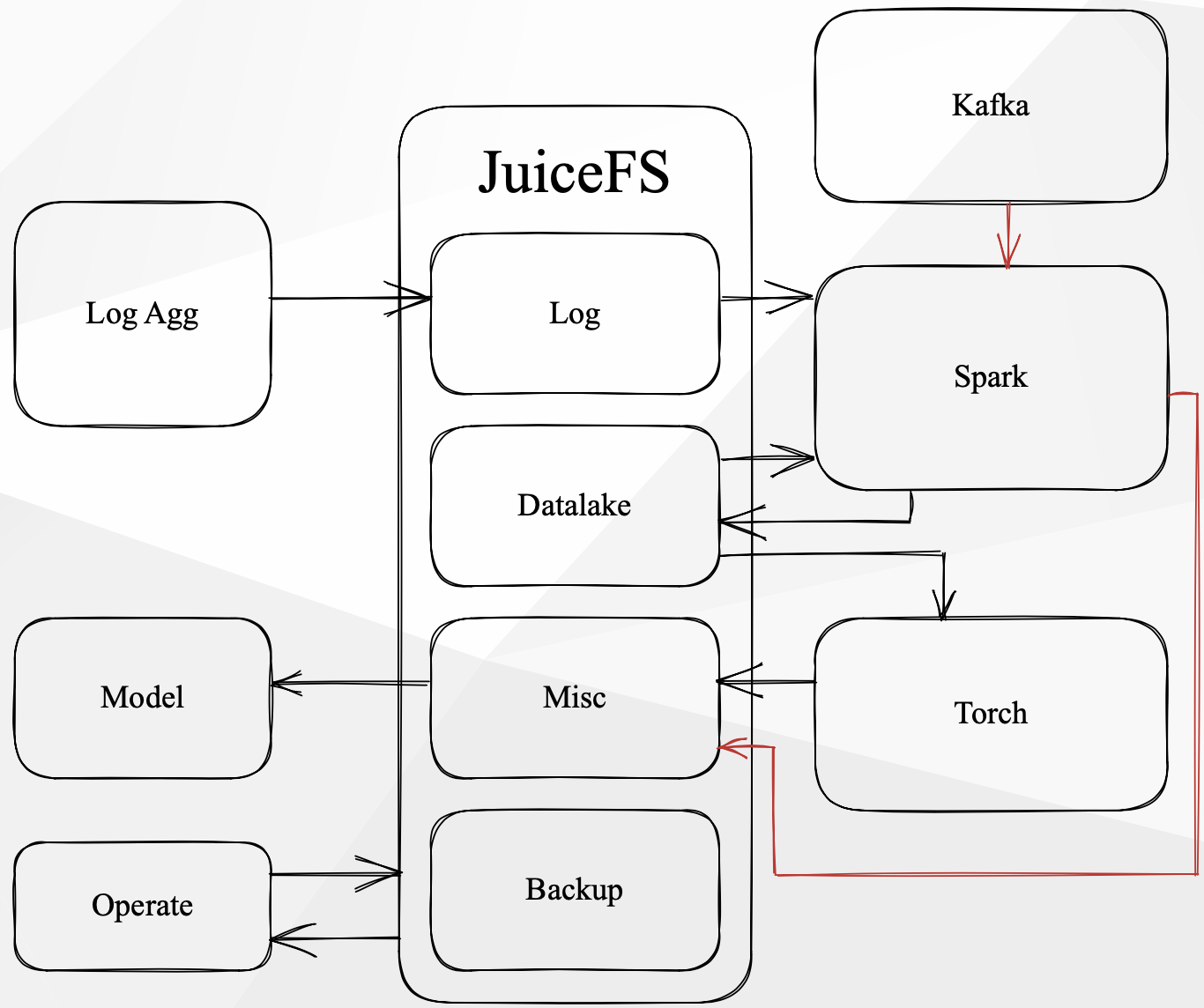
In JuiceFS, data is categorized into several types:
- Online reads and writes
- Online reads and offline writes
- Online writes and offline reads
- Offline reads and writes
All types of data operations are performed on JuiceFS. For example, logs are aggregated into volumes, and Spark may read and perform extract, transform, load (ETL) operations before writing the data to the data lake. Additionally, data sourced from Kafka is processed by Spark and then written to the data lake.
Spark's checkpointing is stored in another JuiceFS volume. The data lake is made available to our algorithm engineers for model training, and the training results are written back using JuiceFS. The operations team manages the file lifecycle on JuiceFS using various scripts and tools, including archiving if necessary.
Components of the new data platform
Debian-based container
At Douban, the operations team chose Debian-based containers as the base image, and we followed their choice. To address the issue of slow task startup, our team pre-pulled the large images on each node of our computing platform.
JuiceFS
When we switched to the JuiceFS storage system, users experienced a seamless switch as JuiceFS proved to be highly stable.
One advantage of JuiceFS over MooseFS is its compatibility with the HDFS SDK, enabling easy integration with tools like Spark. Leveraging JuiceFS CSI on Kubernetes, we conveniently utilize JuiceFS as a persistent volume.
In addition, communication with the JuiceFS team is efficient, and they promptly solve issues. For example, they proactively addressed the high checkpoint frequency in stream processing.
Kubernetes
We began using Kubernetes as early as version 1.10. Gradually, we migrated our public-facing service clusters at Douban to Kubernetes, starting from Kubernetes 1.12. This migration was seamlessly performed on our existing machines.
We established the compute cluster based on Kubernetes 1.14 after moving to the cloud. Now, our Kubernetes is version 1.26.
One of the reasons we chose Kubernetes as our computing platform is its unified set of components. Additionally, we can influence its scheduling through the scheduling framework or Volcano.
We also take advantage of the Helm community to quickly deploy essential services such as Airflow, Datahub, and Milvus to our offline Kubernetes cluster.
Spark
When we tested Spark, we ran tasks on a Mesos cluster, similar to using Dpark. Later, we chose Kubernetes and used the spark-on-k8s-operator from the Google Cloud platform to deploy Spark tasks to our Kubernetes cluster. We deployed two streaming tasks, but didn't scale them extensively.
After that, we decided to use Kubernetes and Airflow. We planned to develop our Airflow Operator, enabling direct submission of Spark tasks within Kubernetes, and utilize Spark's cluster mode to submit tasks to the Kubernetes cluster.
For development environments, we rely on JupyterLab. At Douban, we have a Python library that provides pre-defined configurations for Spark sessions, ensuring seamless submission of Spark tasks to the Kubernetes cluster.
Currently, we deploy streaming tasks using Kubernetes Deployment, which simplifies the process. Additionally, we’ll try out Kyuubi & Spark Connect to improve the reading and writing experience for offline data in online tasks.
We upgraded Spark frequently to maximize community resources and deliver new features to developers. Thanks to the community, we solved many common optimization issues in our daily computing tasks. However, we encountered challenges, such as the memory leaks in parquet zstd compression of Spark 3.2. To workaround this issue, we introduced unreleased patches in advance.
We read and write JuiceFS data using two methods:
- FUSE: FUSE is primarily used for ETL tasks, including reading and writing logs and comma-separated values (CSV) files. For tasks that have not been migrated to Spark yet, we convert Hive tables to CSV files for computing.
- HDFS: Other data is read and written via pre-configured HDFS (for example, Hive Table and Iceberg Table).
We initially considered using Delta Lake for our data lake solution. However, because it didn’t support Merge on Read and had write amplification in our specific use case, we made the decision to go with Iceberg instead and implemented it for MySQL CDC processing. We store our data on JuiceFS for reads and writes and have not encountered any performance issues so far.
How we benefit from the new platform
After we migrated to the new computing platform, we gained several functionalities that were previously unavailable. One significant improvement is the ability to use SQL-based tasks, which perform much better than before and provide improved real-time reporting for various metrics.
Spark operates differently from Mesos. Instead of sharing resources fairly among tasks, Spark allocates resources based on task requirements. This results in more predictable execution times and easier task estimation. The new platform also improves the real-time availability of accessing application data.
Migrating statistics and rankings to the new computing platform was a crucial step to keep pace with the community. Since the end of last year, these operations have been running smoothly and reliably.
What’s next
In our future plans, our top priority is to implement cost-saving measures that enable dynamic scaling of the entire computing cluster. We are actively working towards providing a more stable SQL interface by adopting a multi-tenant SQL server and exploring the latest features of Spark 3.4.
Looking ahead, we hope to use resources more efficiently by separating storage and computation through the Spark Remote Shuffle Service. Additionally, we may develop "Spark as a Service" for developers. Our aim is to stay aligned with the community and continuously improve our technical expertise.