















Note: This post was published on DZone.
TL;DR:
The author of this post questions the perspective presented in a MinIO article, which suggests that POSIX is not a suitable fit for object stores. He conducted comprehensive tests involving MinIO, s3fs-fuse, and JuiceFS. Results indicate that MinIO and JuiceFS deliver excellent performance, while s3fs-fuse lags. In small file overwrite scenarios, JuiceFS FUSE-POSIX outperforms other solutions .
Recently, I came across an article on the MinIO blog titled "Putting a Filesystem on Top of an Object Store is a Bad Idea. Here is why." The author used s3fs-fuse as an example to illustrate the performance challenges encountered when accessing MinIO data using Portable Operating System Interface (POSIX) methods, highlighting that the performance significantly lagged behind direct MinIO access. The author attributed these performance issues to inherent flaws in POSIX. However, our experience differs somewhat from this conclusion.
POSIX is a useful and widely adopted standard. Developing software following POSIX guarantees compatibility and portability across different operating systems. Most applications in various industries adhere to the POSIX standard. With the advancement of cloud computing, big data, and AI technologies, as well as the increasing volume of data stored, there is a growing demand for elastic storage solutions like object stores. Although object stores like MinIO provide SDKs in multiple languages, many traditional applications struggle to adapt their code to use object storage APIs. This has led to various storage products implementing POSIX interfaces on top of object stores to meet this inflexible demand.
Many products in the industry have successfully implemented POSIX interfaces on object stores, such as Ceph, JuiceFS, and Weka. These solutions have large user bases and numerous success stories, and they perform well in terms of performance.
While it's true that POSIX has significant complexity, the associated issues are not insurmountable. With respect and a desire to verify these claims, I set up a test environment, employed the same sample data and testing methods as in the MinIO article, and conducted a validation.
Products compared and test objectives
To provide a comprehensive assessment, I introduced JuiceFS into the comparison.
JuiceFS is an open-source cloud-native distributed file system. It employs object storage as its data storage layer and relies on a separate database to store metadata. It offers various access methods, including POSIX API, S3 API, CSI Driver, HDFS API, and WebDAV, along with unique data chunking, caching, and concurrent read/write mechanisms. JuiceFS is a file system, fundamentally distinct from tools like s3fs-fuse, which simply convert from object storage to POSIX protocols.
By introducing JuiceFS into the comparison, I aimed to objectively evaluate the advantages and disadvantages of implementing protocols like POSIX on top of object storage.
I conducted the following two tests on MinIO, JuiceFS, and s3fs-fuse:
- Writing a 10 GB file
- Overwriting small files with Pandas
All three solutions used a MinIO instance deployed on separate servers as the underlying storage. For the test samples, a 10 GB file was utilized, which was the same CSV file mentioned in the MinIO article.
All the environments, software, scripts, and sample data in this article come with complete code and instructions to ensure that you can reproduce the environment and test results.
Server and test environment setup
Two identically configured cloud servers:
- System: Ubuntu 22.04 x64
- CPU: 8 cores
- RAM: 16 GB
- SSD: 500 GB
- Network: VPC
The information for each server:
| Server | IP | Purpose |
|---|---|---|
| Server A | 172.16.254.18 | Deploying the MinIO instance |
| Server B | 172.16.254.19 | As the test environment |
Server A preparation
1.I deployed MinIO on Server A using Docker with the following commands:
# Create a dedicated directory and navigate to it.
mkdir minio && cd minio
# Create a configuration file.
mkdir config
touch config/minio
2.I wrote the following information to the config/minio file:
MINIO_ROOT_USER=admin
MINIO_ROOT_PASSWORD=abc123abc
MINIO_VOLUMES="/mnt/data"
3.I created the MinIO container:
sudo docker run -d --name minio \
-p 9000:9000 \
-p 9090:9090 \
-v /mnt/minio-data:/mnt/data \
-v ./config/minio:/etc/config.env \
-e "MINIO_CONFIG_ENV_FILE=/etc/config.env" \
--restart unless-stopped \
minio/minio server --console-address ":9090"
4.On MinIO's Web Console, I pre-created three buckets:
| Bucket name | Purpose |
|---|---|
| test-minio | For testing MinIO |
| test-juicefs | For testing JuiceFS |
| test-s3fs | For testing s3fs-fuse |
Server B preparation
1.I downloaded the 10 GB test sample file.
curl -LO https://data.cityofnewyork.us/api/views/t29m-gskq/rows.csv?accessType=DOWNLOAD
2.I installed the mc client.
mc is a command-line file manager developed by the MinIO project. It enables read and write operations on both local and S3-compatible object storage in the Linux command line. The mc cp command provides real-time progress and speed updates during data copying, facilitating the observation of various tests.
Note: To maintain test fairness, all three approaches used
mcfor file write tests.
# Download mc.
wget https://dl.min.io/client/mc/release/linux-amd64/mc
# Check the mc version.
mc -v
mc version RELEASE.2023-09-20T15-22-31Z (commit-id=38b8665e9e8649f98e6162bdb5163172e6ecc187)
Runtime: go1.21.1 linux/amd64
# Install mc.
sudo install mc /usr/bin
# Set an alias for MinIO.
mc alias set my http://172.16.254.18:9000 admin abc123abc
3.I downloaded s3fs-fuse.
sudo apt install s3fs
# Check the version.
s3fs --version
Amazon Simple Storage Service File System V1.93 (commit:unknown) with OpenSSL
# Set object storage access key.
echo admin:abc123abc > ~/.passwd-s3fs
# Modify key file permissions.
chmod 600 ~/.passwd-s3fs
# Create the mounting directory.
mkdir mnt-s3fs
# Mount the object storage.
s3fs test-s3fs:/ /root/mnt-s3fs -o url=http://172.16.254.18:9000 -o use_path_request_style
4.I installed JuiceFS.
I used the official script to install the latest JuiceFS Community Edition.
# One-click installation script
curl -sSL https://d.juicefs.com/install | sh -
# Check the version.
juicefs version
juicefs version 1.1.0+2023-09-04.08c4ae6
5.I created a file system. JuiceFS is a file system that needs to be created before use. In addition to object storage, it requires a database as a metadata engine. It supports various databases. Here, I used the commonly used Redis as the metadata engine.
Note: I've installed Redis on Server A, accessible via
172.16.254.18:6379with no password. The installation process is omitted here. You can refer to the Redis documentation for details.
# Create the file system.
juicefs format --storage minio \
--bucket http://172.16.254.18:9000/test-juicefs \
--access-key admin \
--secret-key abc123abc \
--trash-days 0 \
redis://172.16.254.18/1 \
myjfs
6.I accessed JuiceFS using the more commonly used POSIX and S3 API methods and tested their performance.
# Create mounting directories.
mkdir ~/mnt-juicefs
# Mount the file system in POSIX mode.
juicefs mount redis://172.16.254.18/1 /root/mnt-juicefs
# Access the file system using the S3 API method.
export MINIO_ROOT_USER=admin
export MINIO_ROOT_PASSWORD=abc123abc
juicefs gateway redis://172.16.254.18/1 0.0.0.0:9000
# Set an alias for the JuiceFS S3 API in mc.
mc alias set juicefs http://172.16.254.18:9000 admin abc123abc
Note: The JuiceFS Gateway can also be deployed on Server A or any other internet-accessible server since it exposes a network-based S3 API.
Tests and results
Here is a quick summary of my tests and results:
| Test | MinIO | S3FS-FUSE |
JuiceFS (FUSE) |
JuiceFS (S3 gateway) |
|---|---|---|---|---|
| Writing a 10 GB file | 0m27.651s | 3m6.380s | 0m28.107s | 0m28.091s |
| Overwriting small files with Pandas | 0.83s | 0.78s | 0.46s | 0.96s |
Test 1: Writing a 10 GB file
This test was designed to evaluate the performance of writing large files. The shorter the time taken, the better the performance. I used the time command to measure the duration of write operations, providing three metrics:
real: The actual time from the start to the end of the command. It included all waiting times, such as waiting for I/O operations to complete, waiting for process switches, and resource waiting.user: The time executed in user mode, indicating the CPU time used for executing user code. It typically represented the computational workload of the command.sys: The time executed in kernel mode, indicating the CPU time used for executing kernel code. It typically represented the workload related to system calls, such as file I/O and process management.
MinIO
I ran the following command to perform a copy test:
time mc cp ./2018_Yellow_Taxi_Trip_Data.csv my/test-minio/
Results for writing a 10 GB file directly to MinIO:
real 0m27.651s
user 0m10.767s
sys 0m5.439s
s3fs-fuse
I ran the following command to perform a copy test:
time mc cp ./2018_Yellow_Taxi_Trip_Data.csv /root/mnt-s3fs/
Results for writing a 10 GB file directly to s3fs-fuse:
real 3m6.380s
user 0m0.012s
sys 0m5.459s
Note: Although the write time was 3 minutes and 6 seconds for
s3fs-fuse, there were no write failures as described in the MinIO’s article.
JuiceFS
I tested the performance of JuiceFS for large file writes using both the POSIX and S3 API methods:
# POSIX write test
time mc cp ./2018_Yellow_Taxi_Trip_Data.csv /root/mnt-juicefs/
# S3 API write test
time mc cp ./2018_Yellow_Taxi_Trip_Data.csv juicefs/myjfs/
Results for JuiceFS POSIX writing a 10 GB file:
real 0m28.107s
user 0m0.292s
sys 0m6.930s
Results for JuiceFS S3 API writing a 10 GB file:
real 0m28.091s
user 0m13.643s
sys 0m4.142s
Summary of large file write results
The following figure shows the test results:
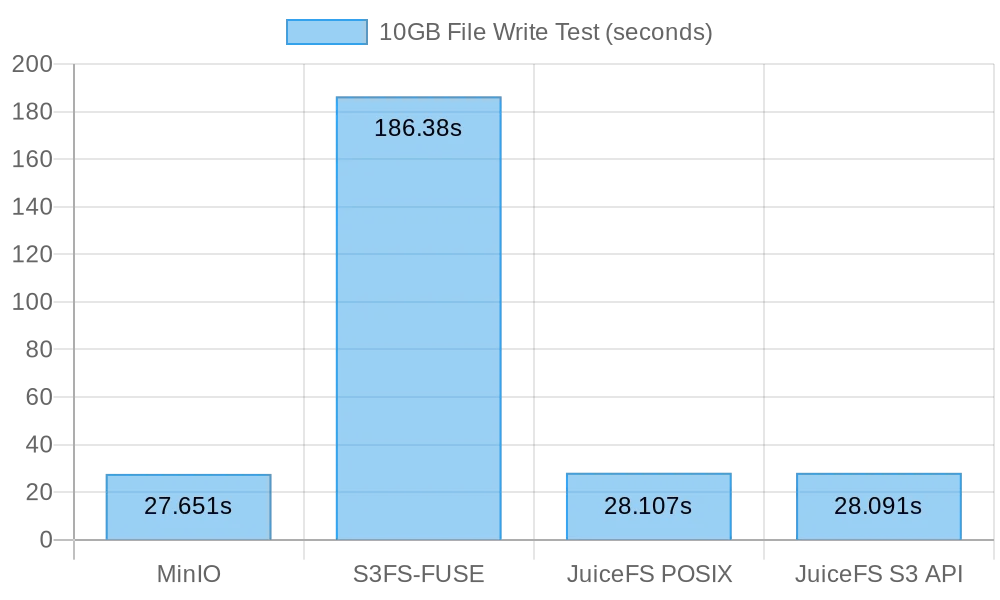
The test results show that both direct writing to MinIO and JuiceFS delivered comparable performance, completing the task within about 30 seconds. In contrast, s3fs-fuse took over 3 minutes to write a 10 GB file, which was approximately 6 times slower than the former two.
When writing large files, mc utilizes the Multipart API to upload files in chunks to the S3 interface. Conversely, s3fs-fuse can only write to POSIX in a single thread. JuiceFS also automatically divides large files into chunks and concurrently writes them to MinIO during sequential writes, ensuring performance on par with direct MinIO writes. S3FS, on the other hand, first writes to a cache disk in a single thread and subsequently uploads the file in chunks to MinIO, resulting in longer write times.
Based on the calculation that it took 30 seconds to write a 10 GB file, the average speed was 333 MB/s. This was limited by the bandwidth of cloud server SSDs. These test results indicated that both MinIO and JuiceFS could maximize the local SSD bandwidth, and their performance would improve with enhancements to server cloud disks and network bandwidth.
Test 2: Overwriting small files with Pandas
This test assessed the performance of object storage systems in small file overwrite scenarios. The test scripts for each software slightly differed. You can find all script code here.
Minio
I got the test script and ran the test:
# Get the test script.
curl -LO https://gist.githubusercontent.com/yuhr123/7acb7e6bb42fb0ff12f3ba64d2cdd7da/raw/30c748e20b56dec642a58f9cccd7ea6e213dab3c/pandas-minio.py
# Run the test.
python3 pandas-minio.py
The result was as follows:
Execution time: 0.83 seconds
s3fs-fuse
I got the test script and ran the test:
# Get the test script.
curl -LO gist.githubusercontent.com/yuhr123/7acb7e6bb42fb0ff12f3ba64d2cdd7da/raw/30c748e20b56dec642a58f9cccd7ea6e213dab3c/pandas-s3fs.py
# Run the test.
python3 pandas-s3fs.py
The test result was as follows:
Execution time: 0.78 seconds
JuiceFS POSIX
I got the test script and ran the test:
# Get the test script.
curl -LO gist.githubusercontent.com/yuhr123/7acb7e6bb42fb0ff12f3ba64d2cdd7da/raw/30c748e20b56dec642a58f9cccd7ea6e213dab3c/pandas-juicefs-posix.py
# Run the test.
python3 pandas-juicefs-posix.py
The test result was as follows:
Execution time: 0.43 seconds
JuiceFS S3 API
I got the test script and ran the test:
# Get the test script.
curl -LO https://gist.githubusercontent.com/yuhr123/7acb7e6bb42fb0ff12f3ba64d2cdd7da/raw/30c748e20b56dec642a58f9cccd7ea6e213dab3c/pandas-juicefs-s3api.py
# Run the test.
python3 pandas-juicefs-s3api.py
The test result was as follows:
Execution time: 0.86 seconds
Summary of Pandas small file overwrites
The following figure shows the test results:
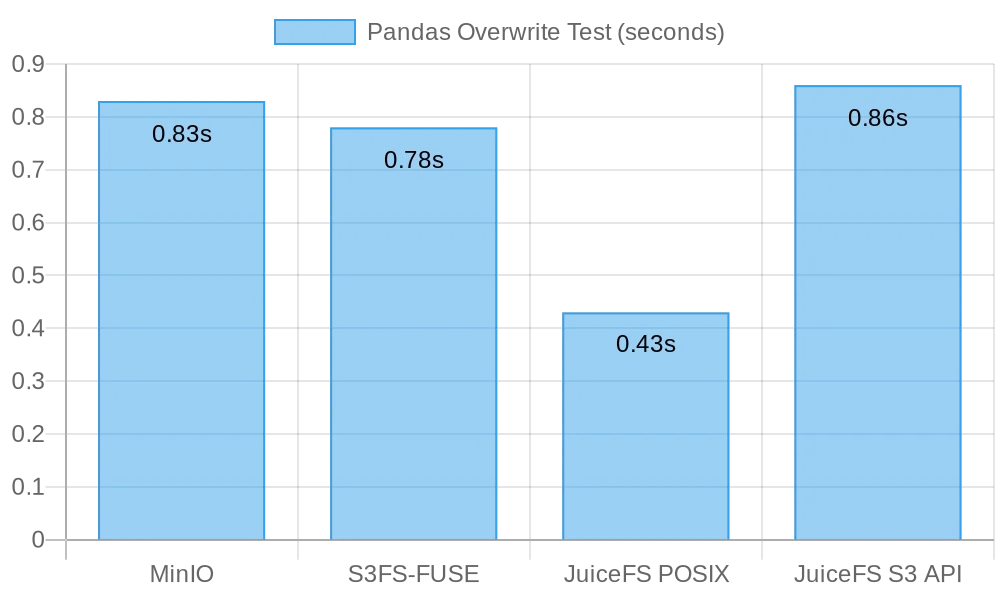
In this test, JuiceFS FUSE-POSIX demonstrated the fastest speed, nearly twice as fast as the other solutions. MinIO, s3fs-fuse, and JuiceFS S3 Gateway exhibit similar performance. From the perspective of small file overwrites, the POSIX interface proved more efficient, delivering better performance than object storage interfaces.
Issues and analysis
Issue 1: Why was S3FS so slow?
Analysis: From the test data, it's clear that when writing the same 10 GB file, S3FS took 3 minutes, while MinIO and JuiceFS both completed the task in around 30 seconds.
This significant performance difference was primarily due to different technical implementations. When s3fs-fuse writes a file, it first writes the file to a local temporary file and then uploads it to object storage in chunks. If there's insufficient local disk space, it uploads synchronously. It needs to copy data between local disk and S3 storage. Therefore, with large files or a substantial number of files, it results in performance degradation.
Furthermore, S3FS relies on the underlying object storage's metadata management capabilities. When it deals with a large number of files, frequent interaction with object storage to retrieve metadata has a significant impact on performance. In simple terms, the larger the file size and total quantity of files written to S3FS, the larger the proportional performance overhead.
Issue 2: Why was JuiceFS faster?
Analysis: In the test, both JuiceFS and S3FS utilized FUSE for reading and writing. JuiceFS fully used disk bandwidth like MinIO, but it did not encounter performance issues as with S3FS.
The answer lies in their respective technical architectures. While data is processed through the FUSE layer during file writes, JuiceFS uses high concurrency, caching, and data chunking techniques to reduce communication overhead between the FUSE layer and the underlying object storage. This allows JuiceFS to handle more read and write requests for files simultaneously, reducing waiting times and transmission latency.
Additionally, JuiceFS employs a dedicated database (in this case, Redis) to manage metadata. When dealing with a particularly large number of files, an independent metadata engine can effectively alleviate the workload, enabling faster file location.
Conclusion
The tests above demonstrate that using object storage as a foundation and implementing a POSIX interface on top of it doesn't necessarily cause a loss of performance. Whether writing large or small files, JuiceFS exhibits performance comparable to direct MinIO writes, without any degradation in underlying object storage performance due to POSIX access. Furthermore, in terms of Pandas table overwrites, JuiceFS FUSE-POSIX performance remains consistent and even surpasses MinIO by nearly double.
The test results indicate that some software, like s3fs-fuse, may experience performance degradation when converting between S3 API and POSIX interfaces. While it can be a convenient tool for temporary S3 access, for stable and high-performance long-term use, careful research and validation are necessary to select more suitable solutions.
For simple unstructured file archiving, direct use of MinIO or cloud object storage is a good choice. However, for scenarios that involve large-scale data storage and processing, such as AI model training, big data analysis, Kubernetes data persistence, and other frequent read and write operations, JuiceFS' independent metadata management, concurrent read and write capabilities, and caching mechanisms provide superior performance. It's a high-performance file system solution worth considering.
If you have any questions or would like to learn more details about our story, feel free to join discussions about JuiceFS on GitHub and the JuiceFS community on Slack.