















Background
Metadata is the core of storage system, of which performance is critical to the capability and scalability of the entire data platform. Especially when dealing with massive files. There are a lot of create, open, rename and delete operations on metadata during the platform task creation, run and end commit phases. Therefore, metadata performance is one of the most important factors to be considered when selecting a file system.
Among the mainstream big data storage solutions, HDFS is the most widely adopted for more than ten years; object storage like Amazon S3 is the more popular solution for big data storage on cloud in recent years; JuiceFS is a newcomer in the big data world, which is built for cloud and based on object storage, for big data scenario. Therefore, we selected three typical storage solutions, HDFS, Amazon S3 and JuiceFS Community Edition, to test the performance of metadata.
Test Methods
NNBench is a component of Hadoop dedicated to benchmark file system metadata performance, and it is used for this test.
The original NNBench has some limitations so we have modified its code to better suit our testing:
- The original NNBench test task was single-threaded and had low resource utilization, so we changed it to multi-threaded to increase pressure.
- The original NNBench uses hostname as part of the path name. It doesn’t work well when running multiple concurrent tasks in the same host, while files will be repeatedly created and deleted in multiple tasks which isn’t quite the case with real world big data workloads. So we changed it to use the Map sequence number to generate the path name to avoid the conflict when running multiple test tasks on a single host.
Test environment
Test area: us-east-1
Test software.
emr-6.4.0, hadoop3.2.1, HA deployment
master (3): m5.xlarge, 4 vCore, 16 GiB
core (3): m5.xlarge, 4 vCore, 16 GiB
JuiceFS community version: v1.0.0
JuiceFS metadata engine: ElastiCache, 6.2.6, cache.r5.large
Performance
First, let's look at the performance of the good old HDFS.
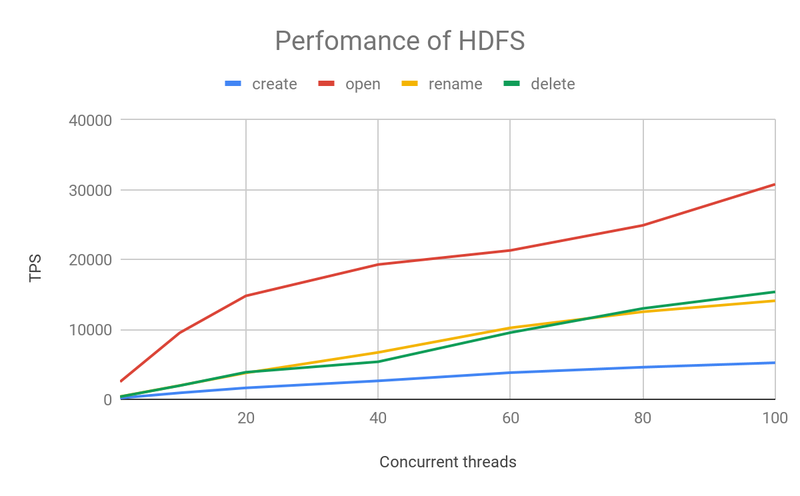
This graph depicts the number of requests per second (TPS) processed by HDFS as the number of concurrency grows, which is essentially linear as concurrency increases.
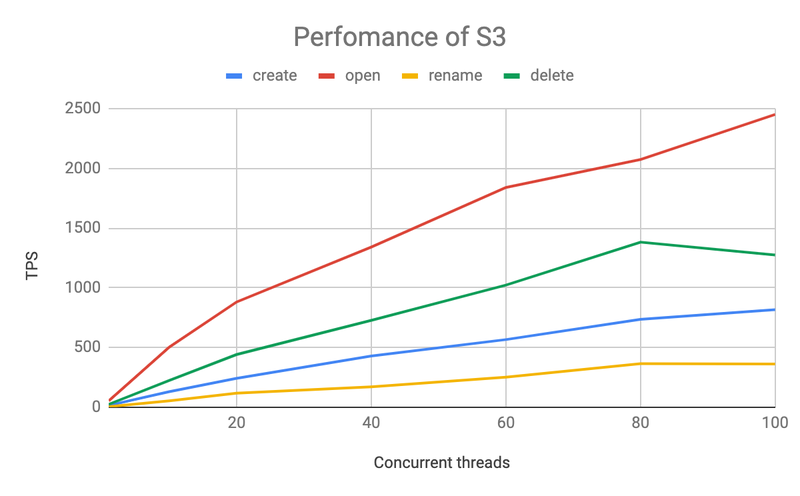
- S3 is an order of magnitude slower than HDFS, but the speed of its various operations remains stable, and the total TPS grows as the number of concurrent operations increases.
- However, S3 performance is less stable, and we can see that Delete requests are decreasing at 100 concurrency, which is probably related to the load of S3 itself.
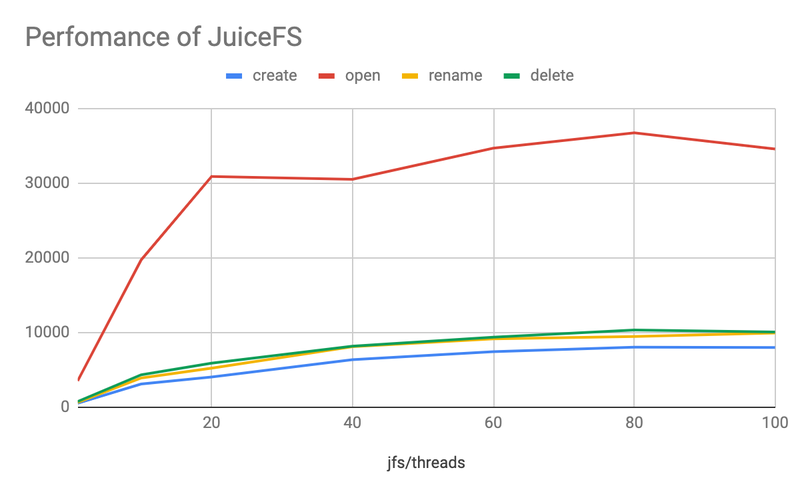
- The overall trend is similar to HDFS, with Open being much faster than other operations.
- The TPS of JuiceFS also basically grows linearly up to 20 concurrent operations, then slows down and reaches the upper limit at around 80 concurrent operations
Performance Comparison
To better visualize the performance difference between the three, we directly compare HDFS, AWS S3 and JuiceFS together:
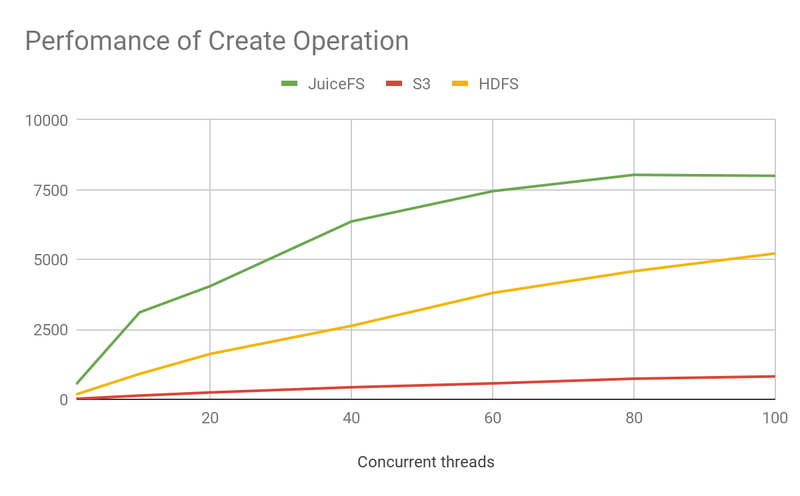
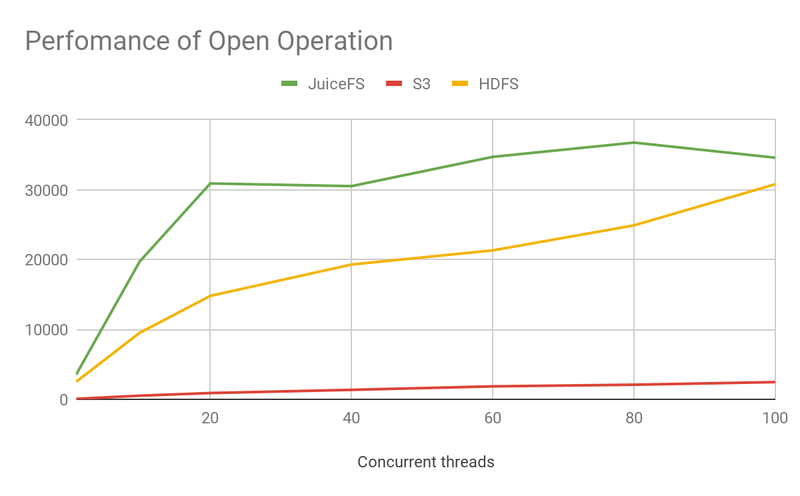
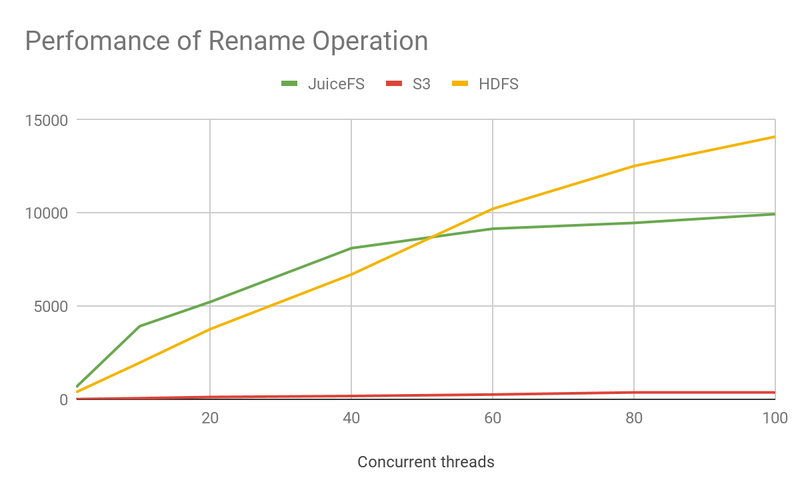
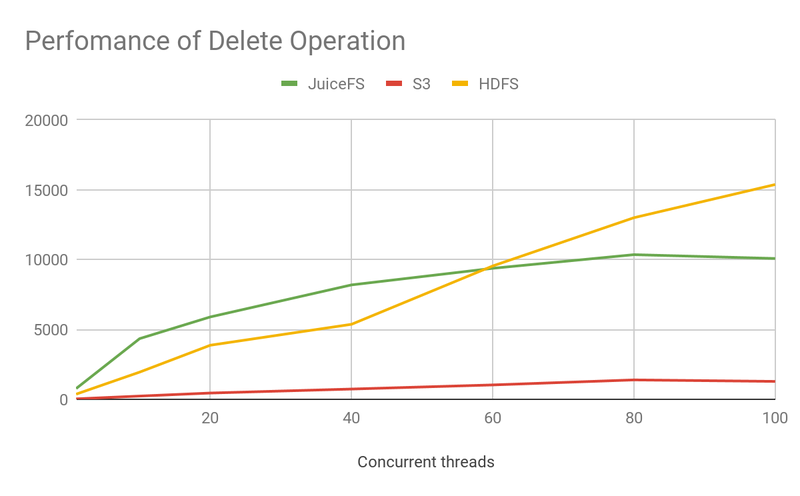
- JuiceFS is significantly ahead of S3 in all metadata operations.
- JuiceFS is ahead of HDFS in Create and Open operations.
- In this test, JuiceFS used ElastiCache as the meta engine. The operations reach a performance bottleneck around 80 concurrency which is worse than HDFS.
Conclusion
Generally when we evaluate the performance of a system, we focus on its operation latency (time consumed by a single operation) and throughput (processing power under full load), and we put these two metrics back together.
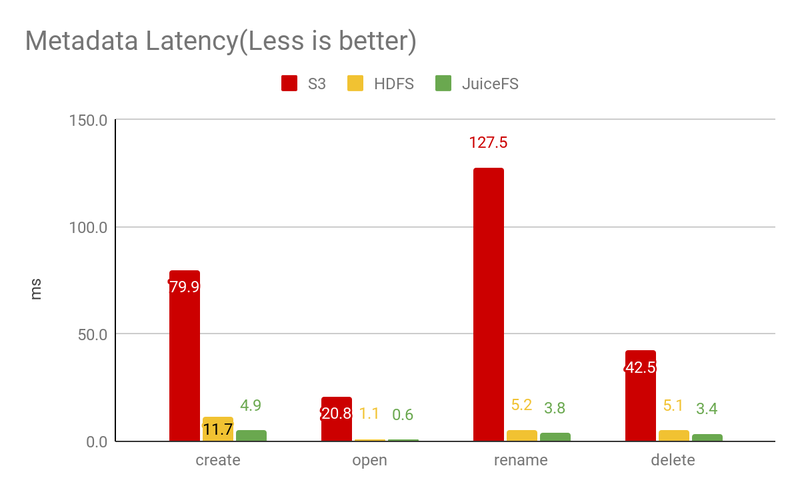
The graph above shows the latency of each operation under 20 concurrent operations (not running at full load) and you can see that
- S3 is very slow, especially with the Rename operation, because it is implemented by Copy + Delete. In this test, Rename is executed only on a single empty file, while in real big data scenario, it is more common to Rename the whole directory, the gap will be even bigger.
- JuiceFS is faster than HDFS.
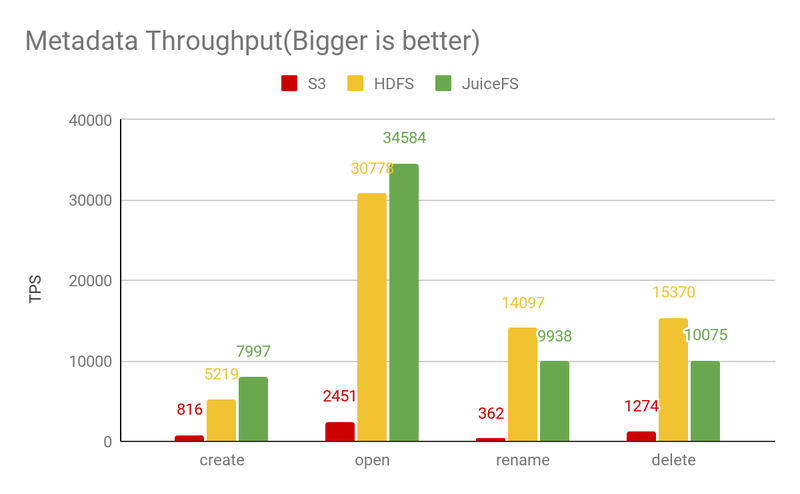
The graph above shows a comparison of throughput at 100 concurrency, which shows that
- S3's throughput is very low, with an order of magnitude or two difference from the other two products, meaning that it needs to use more computational resources and generate higher concurrency to get the same processing power.
- JuiceFS has essentially the same processing power as HDFS, with higher performance than HDFS for some specific operations.
- As concurrency continues to rise, HDFS performance can still continue to improve, but JuiceFS is limited by the performance of the metadata engine itself and reaches a bottleneck. If you need high throughput, you can use TiKV as the metadata engine.
JuiceFS Community Edition can be adapted to a variety of mature metadata engines, each with its own performance characteristics. For example, the low latency of Redis, the reliability of MySQL, and the high throughput of TiKV. For more tests, see: Metadata Engine Performance Comparison Test | JuiceFS Document Center