















Hugging Face Transformers is a powerful machine learning framework that offers a suite of APIs and tools for downloading and training pre-trained models. To improve training efficiency and avoid redundant downloads, Transformers automatically downloads and caches model weights and datasets, typically stored in the ~/.cache/huggingface/hub directory.
However, in scenarios with multiple users or nodes handling the same or related tasks, each device may need to download the same models and datasets. This leads to increased management complexity and wasted network resources. To tackle this issue, you can set the Hugging Face cache directory to a shared storage solution. This allows all users needing the resources to share the same data.
When choosing a shared storage solution, if the devices are few and local, you might consider using Samba or Network File System (NFS). However, if compute resources are distributed across different clouds or data centers, a distributed file system that ensures both performance and consistency—such as JuiceFS—is a better fit.
With JuiceFS’ distributed, multi-client sharing, and strong consistency features, different compute nodes can efficiently share and migrate training resources without the need for duplicating the same data. This significantly optimizes resource utilization and storage management while enhancing the overall efficiency of AI model training.
JuiceFS architecture
JuiceFS is an open-source, cloud-native distributed file system that employs a decoupled architecture for data and metadata storage. It uses object storage for storing data and key-value or relational databases for metadata management. You can set up these computing resources by yourself or purchase them from cloud platforms. This makes JuiceFS easy to deploy and use.
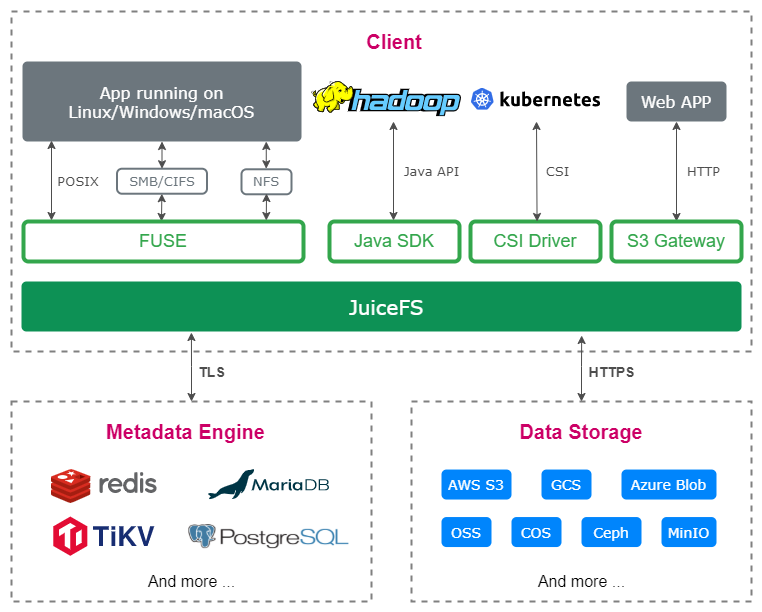
Underlying data storage
JuiceFS supports nearly all mainstream public cloud object storage services, such as Amazon S3, Google Cloud Storage, and Alibaba Cloud OSS, along with on-premises deployments like MinIO and Ceph.
The metadata engine
JuiceFS is compatible with various databases for its metadata engine, including Redis, MySQL, and PostgreSQL. In addition, you can use JuiceFS Cloud Service. It features a high-performance distributed metadata engine developed by Juicedata for demanding performance needs.
The JuiceFS client
JuiceFS offers both an open-source edition (JuiceFS Community Edition) and a cloud service edition (JuiceFS Cloud Service). They use different clients but share similar usage methods. This article will focus on JuiceFS Community Edition.
JuiceFS Community Edition provides a cross-platform client that supports Linux, macOS, and Windows operating systems. Once you've set up a JuiceFS file system with your compute resources, you can access it using the API or FUSE interface provided by the JuiceFS client for file reading, writing, and metadata queries.
For storing Hugging Face's cached data, you can mount JuiceFS to the ~/.cache/huggingface/ directory. This enables Hugging Face-related data to be stored in JuiceFS. Alternatively, you can customize the Hugging Face cache directory by setting an environment variable that points to the mounted JuiceFS directory.
Next, we’ll introduce how to create a JuiceFS file system and use JuiceFS for the storage directory of Hugging Face.
Create a JuiceFS file system
First, prepare the following object storage and metadata engine:
- The object storage bucket:
https://jfs.xxx.com - The object storage access key:
your-access - The object storage secret key:
your-secret - The Redis database:
your-redis.xxx.com:6379 - The Redis password:
redis-password
The object storage information is only used once during the creation of the JuiceFS file system and is written into the metadata engine. Subsequent use requires only the metadata engine's address and password.
Install the JuiceFS client
For Linux and macOS, you can install the JuiceFS client with the following command:
curl -sSL https://d.juicefs.com/install | sh -
For Windows, it’s recommended to use the JuiceFS client within the WSL 2 Linux environment. You can also download the precompiled JuiceFS client. For more details, see the JuiceFS document.
Create the JuiceFS file system
Use the format command to create the JuiceFS file system:
juicefs format \
--storage s3 \
--bucket https://jfs.xxx.com \
--access-key your-access \
--secret-key your-secret \
"redis://:[email protected]:6379" \
hf-jfs
In the code block above:
hf-jfsis the name of your JuiceFS file system, which you can customize.--storage s3specifies the object storage type as S3. You can refer to the official documentation for more object storage types.- The metadata engine URL starts with
redis://, followed by the username and password, separated by:, then the Redis address and port, separated by@. It’s recommended to wrap the entire URL in quotes.
Mount JuiceFS to the Hugging Face cache directory
If you haven't installed the Hugging Face Transformers yet, create the cache directory first and then mount JuiceFS:
# Create the Hugging Face cache directory.
mkdir -p ~/.cache/huggingface
# Mount JuiceFS to the Hugging Face cache directory.
juicefs mount -d "redis://:[email protected]:6379" ~/.cache/huggingface
Next, install the Hugging Face Transformers, which will automatically cache data to JuiceFS. For example:
pip install transformers datasets evaluate accelerate
Please adjust the installation based on the specific packages required for your hardware and environment.
Alternatively, you can specify the Hugging Face cache directory via environment variables. This allows you to direct the Hugging Face cache directory to the mounted JuiceFS directory without altering the code.
For example, if your JuiceFS mount directory is /mnt/jfs:
juicefs mount -d "redis://:[email protected]:6379" /mnt/jfs
Set the Hugging Face cache directory via the HUGGINGFACE_HUB_CACHE or TRANSFORMERS_CACHE environment variable:
export HUGGINGFACE_HUB_CACHE=/mnt/jfs
This configuration ensures that Hugging Face Transformers will cache data to the JuiceFS mounted directory.
Access Hugging Face cached data anywhere
Due to JuiceFS’ distributed multi-client shared storage features, you can set the Hugging Face cache directory to the JuiceFS mount point and complete the initial model resource download.
Subsequently, on any node that requires those resources, mount JuiceFS and use one of the methods mentioned above to reuse cached data. JuiceFS employs a "close-to-open" mechanism to ensure data consistency when multiple nodes read and write the same data.
It's important to note that the speed of downloading model resources from Hugging Face may be affected by network conditions, with variations based on different countries, regions, and network routes. In addition, when using JuiceFS to share data cache directories, similar network latency issues may arise. To improve speed, it’s recommended to enhance bandwidth and reduce network latency between working nodes and the underlying object storage of JuiceFS, as well as the metadata engine.
Conclusion
This article discussed two methods for using JuiceFS as the cache directory for Hugging Face Transformers: pre-mounting JuiceFS to the Hugging Face cache directory and specifying the cache directory via environment variables. Both methods facilitate the sharing and reuse of AI training resources across multiple nodes.
If you have multiple nodes that need to fetch the same Hugging Face cached data or wish to load the same training resources across different environments, JuiceFS is an ideal choice.
I hope the information provided in this article helps enhance your AI model training process. If you have any questions for this article, feel free to join JuiceFS discussions on GitHub and community on Slack.