















juicefs sync is a powerful data synchronization tool that supports concurrent synchronization or migration of data between various storage systems, including object storage, JuiceFS, NFS, HDFS, and local file systems. In addition, this tool provides advanced features such as incremental synchronization, pattern matching (similar to Rsync), and distributed synchronization.
In JuiceFS 1.2, we introduced several new features for juicefs sync. We also optimized performance for multiple scenarios to improve users' data synchronization efficiency when dealing with large directories and complex migrations.
New features:
- Enhanced selective sync
- Direct writing to target files with
--inplace - Monitoring sync progress metrics via Prometheus
Performance optimizations:
- Improved large file sync
- Enhanced forced update
- More efficient single file sync
New features
Enhanced selective sync
Matching with **
Prior to version 1.2, juicefs sync did not support ** matching (matching any path elements, including /). For example, if a user needed to exclude a file named bar located under the foo directory at any recursive level, earlier versions couldn't handle this requirement. In version 1.2, this can be achieved with --exclude /foo/**/bar.
One-time filtering
Before version 1.2, juicefs sync used a layered filtering mode for data synchronization. This was similar to Rsync's behavior. Users familiar with Rsync could apply their experience to juicefs sync. However, many users found this filtering mode complex and difficult to use in certain scenarios.
For example, the requirement to only sync /some/path/this-file-is-found under the root directory would be written as:
--include /some/
--include /some/path/
--include /some/path/this-file-is-found
--exclude *
This rule might confuse users unfamiliar with layered filtering mode. In addition, this approach seems overly complicated for such a simple requirement.
To address this, JuiceFS 1.2 introduced a one-time filtering mode. For the same example, "only sync /some/path/this-file-is-found under the root directory," the new mode's rule is much simpler and easier to understand:
--include /some/path/this-file-is-found
--exclude *
--match-full-path
Users can enable this mode with the --match-full-path option.
Principle for one-time filtering
In the one-time filtering mode, the object name is directly matched against multiple patterns in sequence, as shown in the figure below:
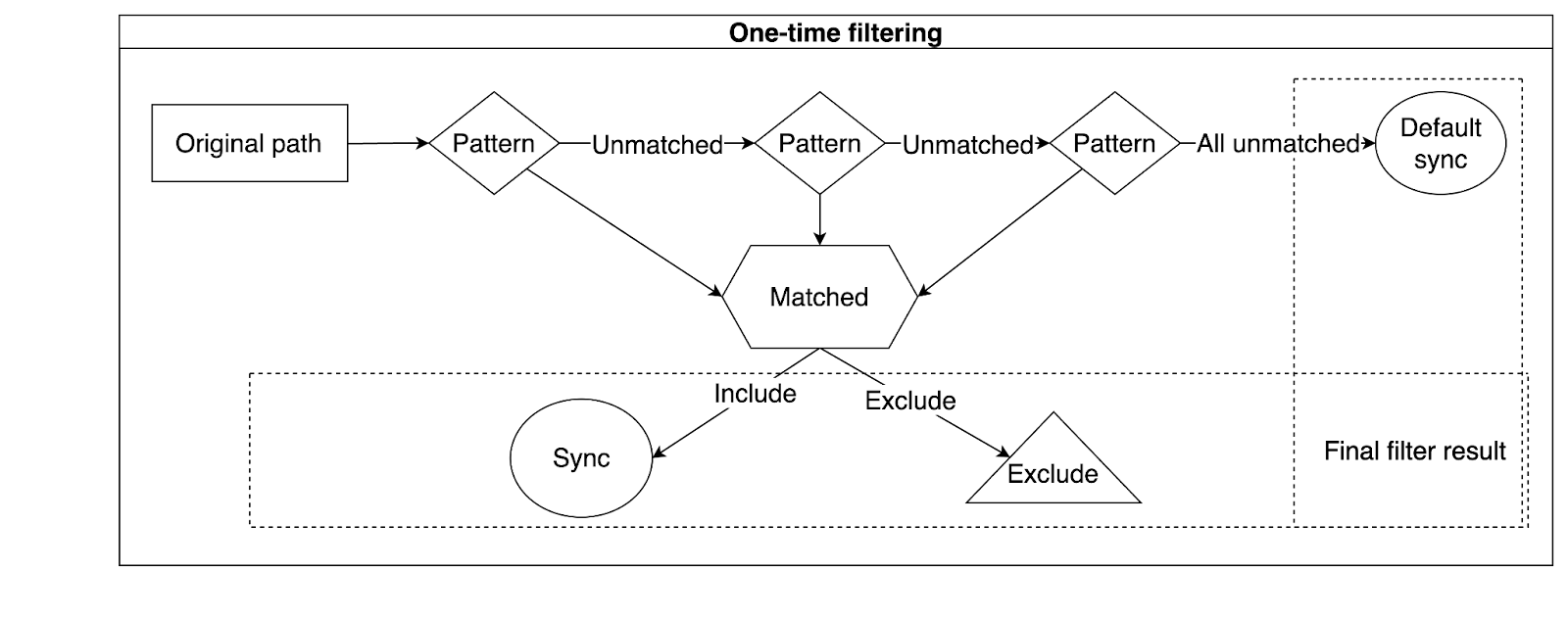
Examples of exclude and include rules in one-time filtering mode:
--exclude *.oexcludes all files matching*.o.--exclude /foo**excludes files or directories namedfooin the root directory.--exclude **foo/**excludes all directories ending withfoo.--exclude /foo/*/barexcludesbarfiles two levels down from thefoodirectory in the root.--exclude /foo/**/barexcludesbarfiles at any recursive level under thefoodirectory in the root. (**matches any number of directory levels)- Using
--include */ --include *.c --exclude *includes only directories andcsource files, excluding all other files and directories. - Using
--include foo/bar.c --exclude *includes only thefoodirectory andfoo/bar.c.
The inplace parameter
The --inplace parameter introduces a new data writing method that allows juicefs sync to write directly to the target file. By default, when syncing data to file system types of storage (File, HFDS, NFS, SFTP), juicefs sync creates a temporary file on the target, writes data to it, and then renames it to complete the sync.
While this reduces the impact on the target file system, the rename operation incurs some performance overhead. From version 1.2, users can change this behavior with the --inplace parameter, allowing writing data directly to the final target file, even if it already exists (existing file content will be cleared).
Progress metrics
The sync progress of juicefs sync is displayed as a progress bar in the terminal. It’s convenient for users to monitor. However, this method is not suitable for other applications to accurately obtain this information. Therefore, we added the --metrics parameter to the sync subcommand. This allows sync progress to be exposed as a series of Prometheus metrics at a specific address.
juicefs_sync_checked{cmd="sync",pid="18939"} 1008
juicefs_sync_checked_bytes{cmd="sync",pid="18939"} 3.262846983e+09
juicefs_sync_copied{cmd="sync",pid="18939"} 0
juicefs_sync_copied_bytes{cmd="sync",pid="18939"} 0
juicefs_sync_failed{cmd="sync",pid="18939"} 0
We also added the --consul parameter. It allows the sync service to be registered with consul.
Performance optimization
In version 1.2, we optimized performance for the following three scenarios.
Large file sync
Before version 1.2, syncing large files with juicefs sync could lead to high memory usage or underutilized bandwidth. This is because we used multipart uploading for syncing large files, where the original object was split into parts and uploaded concurrently. Since the maximum number of parts is 10,000, larger original objects result in larger parts. This leads to higher memory usage with the same concurrency (memory usage = concurrency x part size).
One solution to avoid high memory usage is to reduce concurrency, but this underutilizes bandwidth. A better solution is to reduce the part size during actual upload. This lowers memory usage with the same concurrency.
Based on the second solution, we optimized the large file sync logic in version 1.2, as shown in the following figure:
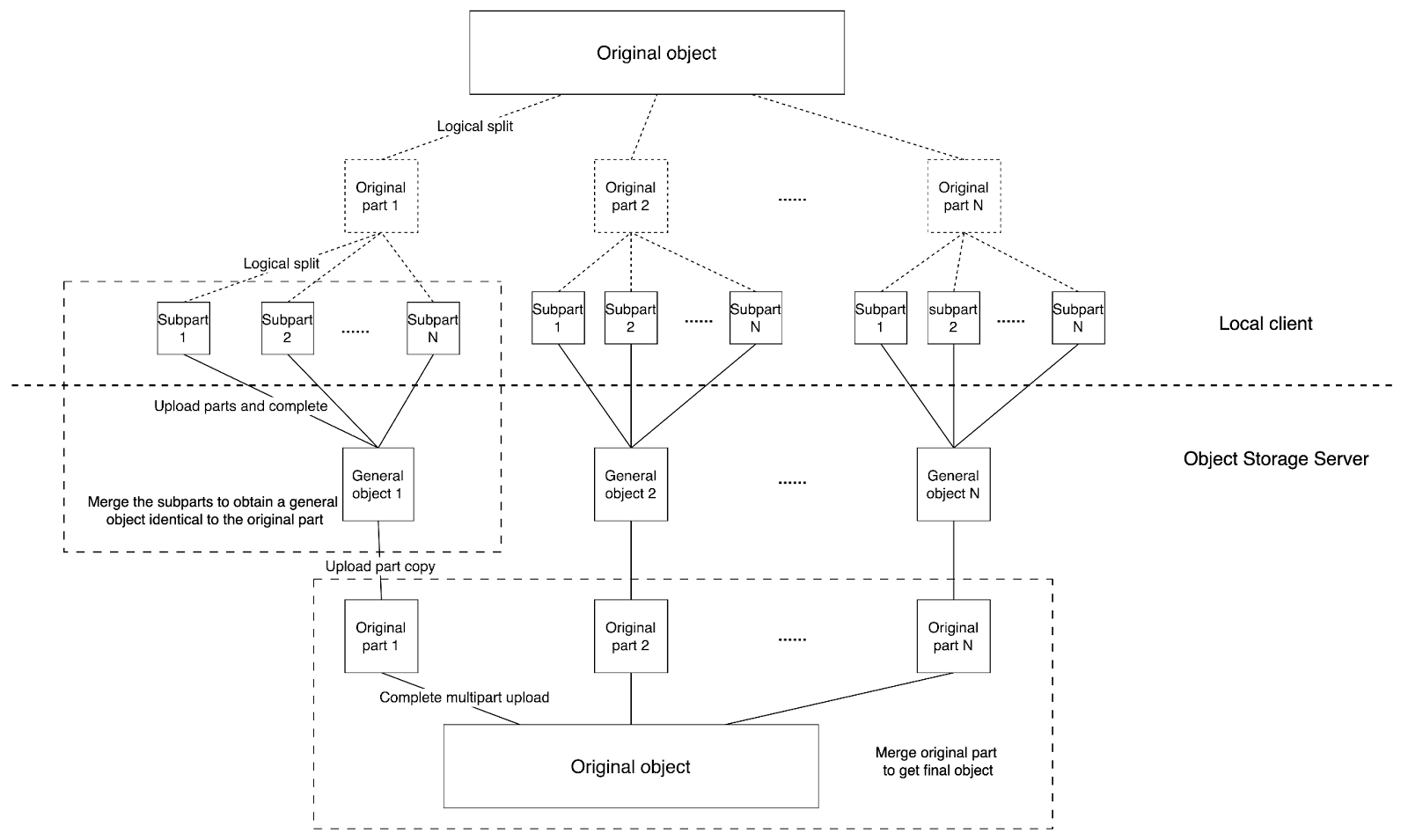
To put it simply, for the parts that are still too large after the initial splitting, we’ll split them in parts again for uploading, merge them to get a general object, then call the UploadPartCopy API to transform it back into a part, and finally merge all the parts.
Compared to the previous process, this approach involves an additional round of splitting parts. The benefit is that after two rounds of splitting, the size of each part during the actual upload is reduced. This fundamentally resolves issues of high memory usage and bandwidth underutilization when synchronizing large files.
Forced update mode
By default, juicefs sync lists the object lists of both the source and destination simultaneously. It compares the lists and skips objects that already exist at the destination. When using the --force-update parameter, all objects from the source are forcibly synced. In this case, the ListObjects request at the destination is unnecessary.
To improve efficiency, in JuiceFS 1.2, we optimized this process. When the --force-update parameter is used, the destination is no longer listed. This optimization can significantly enhance performance when syncing data to large directories.
Single file sync
When users encounter a scenario where only a single file needs to be synced:
juicefs sync s3://mybucket1.s3.us-east-2.amazonaws.com/file1000000 s3://mybucket2.s3.us-east-2.amazonaws.com/file1000000 --limit 1
By default, juicefs sync lists the object lists of both the source and destination to skip objects that already exist at the destination. However, in this case, only the file1000000 object needs to be synced. Listing the entire bucket to retrieve information about a single object is inefficient.
Instead, we can use the HeadObject API to directly request information about the file1000000 object.
Therefore, in version 1.2, for scenarios involving syncing a single file, we replaced the ListObjects API with the HeadObject API to fetch the information of the object to be synced. This optimization greatly enhances performance when syncing a single file between large directories.
Feel free to download and try JuiceFS v1.2.0-beta1. If you have any feedback or suggestions, you can join JuiceFS discussions on GitHub and our community on Slack.