















Note: This post was published on DZone.
Traditional machine learning models can be stored on standalone machines or local hard drives when working with small datasets and simple algorithms. However, as deep learning advances, teams increasingly encounter storage bottlenecks when handling larger datasets and more complex algorithms.
This highlights the importance of distributed storage in the artificial intelligence (AI) field. JuiceFS, an open-source high-performance distributed file system, provides a solution to this problem.
In this article, we’ll discuss the challenges AI teams face, how JuiceFS can speed up model training, and common strategies for faster model training.
Challenges faced by AI teams
AI teams often encounter the following challenges:
- Large datasets: As both data and model size grow, standalone storage is unable to meet application demands. Therefore, distributed storage solutions become imperative to address these issues.
- Archiving historical datasets in full: In certain scenarios, large amounts of new datasets are generated on a daily basis and must be archived as historical data. This is particularly crucial in the field of autonomous driving, where data collected by road test vehicles, such as radar and camera data, are highly valuable assets for the company. Standalone storage proves inadequate in these cases, making distributed storage a necessary consideration.
- Too many small files and unstructured data: Traditional distributed file systems struggle with managing a large number of small files, resulting in a heavy burden on metadata storage. This is especially problematic for visual models. To address this issue, we need a distributed storage system that is optimized for storing small files. This ensures efficient upper-layer training tasks and easy management of a large volume of small files.
- POSIX interfaces for training frameworks: In the initial stages of model development, algorithm scientists often rely on local resources for research and data access. However, when scaling to distributed storage for larger training needs, the original code typically requires minimal modifications. Therefore, distributed storage systems should support POSIX interfaces to maximize compatibility with code developed in the local environment.
- Sharing public datasets and data isolation: In some fields such as computer vision, authoritative public datasets need to be shared across different teams within a company. To facilitate data sharing between teams, these datasets are often integrated and stored in a shared storage solution to avoid unnecessary data duplication and redundancy.
- Low data I/O efficiency in cloud-based training: Cloud-based model training often uses object storage as the underlying storage for a storage-compute separation architecture. However, the poor read and write performance of object storage can result in significant bottlenecks during training.
How JuiceFS helps improve model training efficiency
What is JuiceFS?
JuiceFS is an open-source, cloud-native, distributed file system compatible with POSIX, HDFS, and S3 API. Using a decoupled architecture which stores metadata in a metadata engine and uploads file data to object storage, JuiceFS delivers a cost-effective, high-performance, and elastic storage solution.
JuiceFS has users in more than 20 countries, including leading enterprises in AI, internet, automotive, telecommunications, and fintech industries.
The architecture of JuiceFS in the model training scenario.
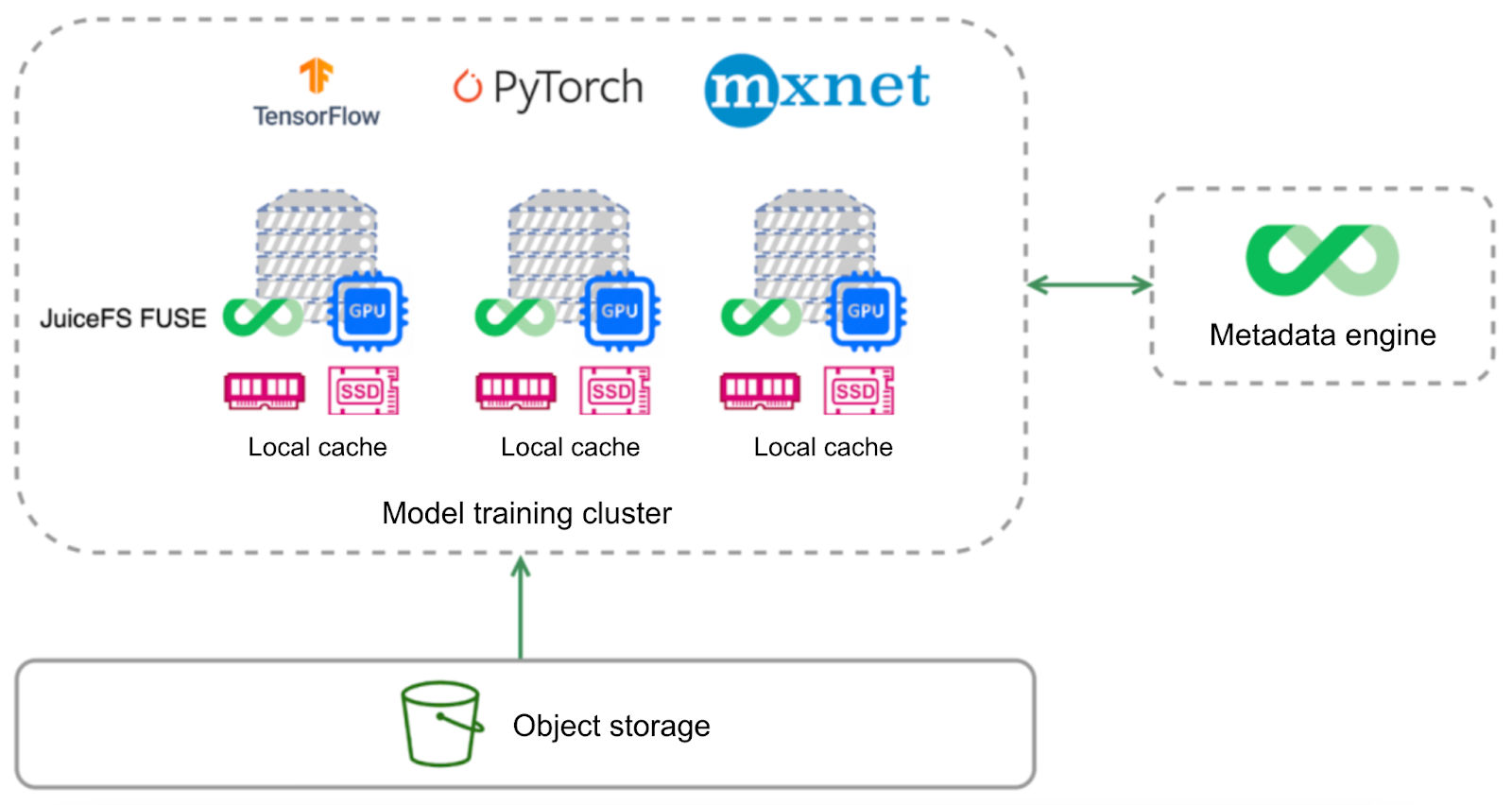
The diagram above shows the architecture of JuiceFS in a model training scenario, which consists of three components:
- Metadata engine: Any database such as Redis or MySQL can serve as the metadata engine. Users can make a choice based on their own needs.
- Object storage: You can use any supported object storage services, provided by public cloud or self-hosted.
- JuiceFS Client: To access the JuiceFS file system just like a local hard drive, users need to mount it on each GPU and computing node.
The underlying storage relies on the raw data in object storage, and each computing node has some local cache, including metadata and data cache.
JuiceFS design allows for multiple levels of local cache on each computing node:
- The first level: a memory-based cache
- The second level: a disk-based cache
Object storage is accessed only upon cache penetration.
For a standalone model, in the first round of training, the training set or dataset usually doesn't hit the cache. However, from the second round onwards, with sufficient cache resources, it's almost unnecessary to access object storage. This can accelerate data I/O.
The read and write cache process in JuiceFS
We previously compared using or not using cache on training efficiency when accessing object storage. The results showed that JuiceFS could achieve more than 4 times performance improvement compared to object storage on average, and up to nearly 7 times performance increase, due to JuiceFS’ metadata cache and data cache.
The diagram below shows the process of read and write cache in JuiceFS:
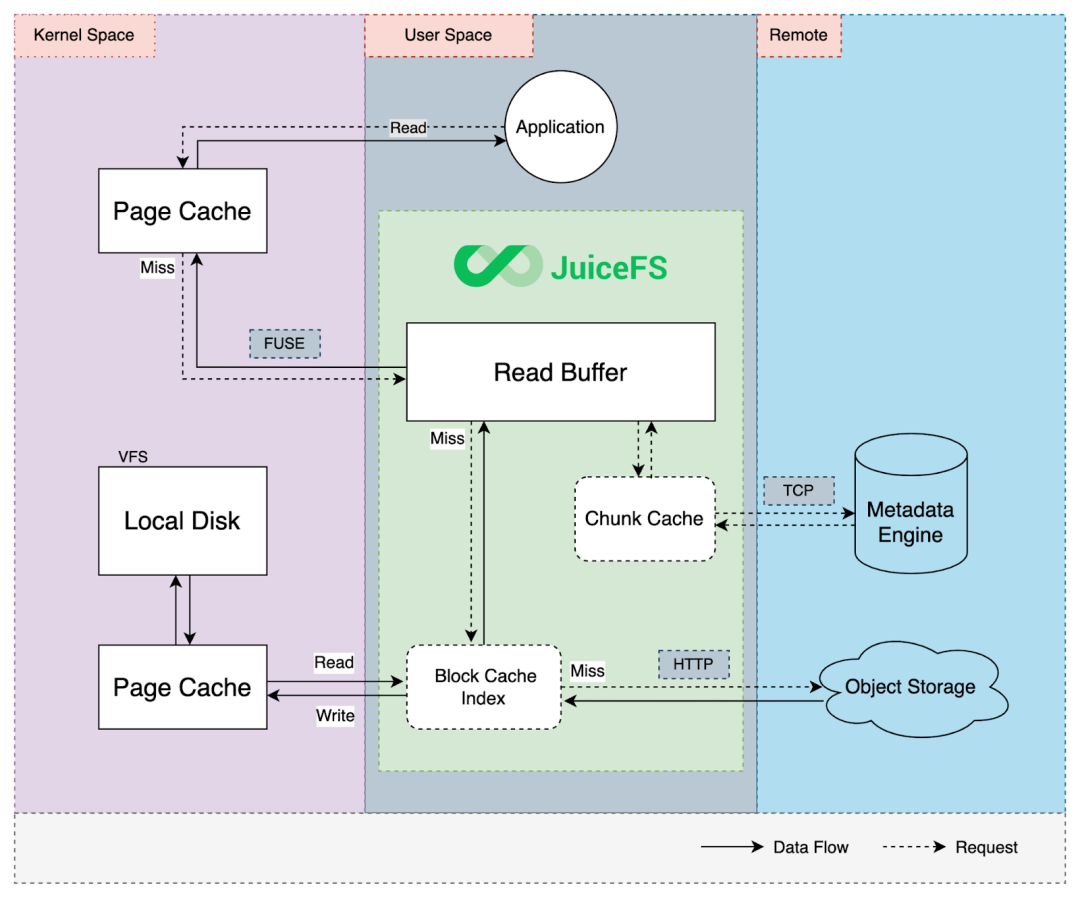
For the "chunk cache" in the figure above, a chunk is a logical concept in JuiceFS. Each file is divided into multiple chunks of 64 MB to improve read performance of large files. This information is cached in the memory of the JuiceFS process to accelerate metadata access efficiency.
The read cache process in JuiceFS:
1.The application, which can be an AI model training application or any application initiating a read request, sends the request.
2. The request enters the kernel space on the left. The kernel checks whether the requested data is available in the kernel page cache. If not, the request goes back to the JuiceFS process in the user space, which handles all read and write requests.
By default, JuiceFS maintains a read buffer in memory. When the request cannot retrieve the data from the buffer, JuiceFS accesses the block cache index, which is a cache directory based on local disks. JuiceFS divides files into 4 MB blocks for storage, so the cache granularity is also 4 MB.
For example, when the client accesses a part of a file, it only caches the 4 MB block corresponding to that part of the data to the local cache directory, rather than the entire file. This is a significant difference between JuiceFS and other file systems or caching systems.
3. The block cache index quickly locates the file block in the local cache directory. If it finds the file block, JuiceFS reads from the local disk, enters the kernel space, and returns the data to the JuiceFS process, which in turn returns it to the application.
4. After the local disk data is read, it’s also cached in the kernel page cache. This is because if direct I/O is not used, Linux systems store data in the kernel page cache by default. The kernel page cache speeds up cache access. If the first request hits and returns data, the request does not enter the user space process through the filesystem in userspace (FUSE) layer. If not, the JuiceFS Client will go through the cache directory for this data. If not found locally, a network request is sent to the object storage, and the data is fetched and returned to the application.
5. When JuiceFS downloads data from the object storage, data is asynchronously written to the local cache directory. This ensures that when accessing the same block next time, it can be hit in the local cache without needing to retrieve it from the object storage again.
Unlike data cache, the metadata cache time is shorter. To ensure strong consistency, Open operations are not cached by default. Considering that metadata traffic is low, its impact on overall I/O performance is small. However, in small file intensive scenarios, the overhead of metadata also occupies a certain proportion.
Why is AI model training too slow?
When you use JuiceFS for model training, performance is a critical factor you should consider, because it directly affects the speed of the training process. Several factors may impact JuiceFS’ training efficiency:
Metadata engine
The choice of metadata engine, such as Redis, TiKV, or MySQL, can significantly impact performance when processing small files. Generally, Redis is 3-5 times faster than other databases. If metadata requests are slow, try a faster database as the metadata engine.
Object storage
Object storage affects the performance and throughput of data storage access. Public cloud object storage services provide stable performance. If you use self-built object storage, such as Ceph or MinIO, you can optimize the components to improve performance and throughput.
Local disk
The location of the cache directory storage has a significant impact on overall read performance. In cases of high cache hit rates, the I/O efficiency of the cache disk affects overall I/O efficiency. Therefore, you must consider factors such as storage type, storage medium, disk capacity, and dataset size.
Network bandwidth
After the first round of training, if the dataset is not sufficient to be fully cached locally, network bandwidth or resource consumption will affect data access efficiency. In the cloud, different machine models have different network card bandwidth. This also affects data access speed and efficiency.
Memory size
Memory size affects the size of the kernel page cache. When there is enough memory, the remaining free memory can be used as JuiceFS’ data cache. This can further speed up data access.
However, when there is little free memory, you need to obtain data access through local disks. This leads to increased access overhead. Additionally, switching between kernel mode and user mode affects performance, such as context switching overhead of system calls.
How to troubleshoot issues in JuiceFS
JuiceFS offers many tools to optimize performance and diagnose issues.
Tool #1: the `juicefs profile` command
You can run the `juicefs profile` command to analyze access logs for performance optimization. After each filesystem is mounted, an access log is generated. However, the access log is not saved in real time and only appears when it’s viewed.
Compared to viewing the raw access log, the `juicefs profile` command aggregates information and performs sliding window data statistics, sorting requests by response time from high to low. This helps you focus on requests with slower response times, further analyzing the relationship between the request and the metadata engine or object storage.
Tool 2: the `juicefs stats` command
The `juicefs stats` command collects monitoring data from a macro perspective and displays it in real-time. It monitors CPU usage, memory usage, buffer usage in memory, FUSE read/write requests, metadata requests, and object storage latency for the current mount point. These detailed monitoring metrics make it easy to view and analyze potential bottlenecks or performance issues during model training.
Other tools
JuiceFS also provides performance analysis tools for CPU and heap profiling:
- The CPU profiling tool analyzes bottlenecks in JuiceFS process execution speed and is suitable for users familiar with source code.
- The heap profiling tool analyzes memory usage, especially when the JuiceFS process occupies a large amount of memory. It’s necessary to use the heap profiling tool to determine which functions or data structures are consuming a lot of memory.
Common methods for accelerating AI model training
Metadata cache optimization
You can optimize metadata cache in two ways as follows.
Adjusting the timeout of the kernel metadata cache
The parameters `--attr-cache`, `--entry-cache`, and `--dir-entry-cache` correspond to different types of metadata:
- `attr` represents file attributes such as size, modification time, and access time.
- `entry` represents files and related attributes in Linux.
- `dir-entry` represents directories and the files they contain.
These parameters respectively control the timeout of the metadata cache.
To ensure data consistency, the default timeout value of these parameters is only one second. In model training scenarios, the original data is not modified. Therefore, it's possible to extend the timeout time of these parameters to several days or even a week. Note that the metadata cache cannot be invalidated actively and can only be refreshed after the timeout period has expired.
Optimizing the user-level metadata cache of the JuiceFS Client
When opening a file, the metadata engine typically retrieves the latest file attributes to ensure strong consistency. However, since model training data is usually not modified, the `--open-cache` parameter can be enabled and a timeout can be set to avoid repetitive access to the metadata engine every time the same file is opened.
Additionally, the `--open-cache-limit` parameter controls the maximum number of cached files. The default value is 10,000, meaning that the metadata of the 10,000 most recently opened files will be cached in memory at most. This value can be adjusted based on the number of files in the dataset.
Data cache optimization
JuiceFS data cache includes kernel page cache and local data cache:
- Kernel page cache cannot be tuned by parameters. Therefore, enough idle memory should be reserved on the computing nodes so that JuiceFS can make full use of it. If the resources on the computing node are tight, JuiceFS doesn’t cache data in the kernel.
- The local data cache is controllable by users, and the cache parameters can be adjusted according to specific scenarios.
- `--cache-size` adjusts the cache size, with a default value of 100 GB, which is sufficient for most scenarios. However, for datasets that occupy particularly large storage space, the cache size needs to be adjusted appropriately. Otherwise, the 100 GB cache space may be filled up quickly, making it impossible for JuiceFS to cache more data.
- Another parameter that can be used with `--cache-size` is `--free-space-ratio`. It determines the amount of free space on the cache disk. The default value is 0.1, which allows up to 90% of the disk space to be used for caching data.
JuiceFS also supports using multiple cache disks at the same time. It’s recommended to use all available disks as much as possible. Data will be evenly distributed to multiple disks through polling to achieve load balancing and maximize the storage advantages of multiple disks.
Cache warm-up
To improve training efficiency, you can use cache warm-up to speed up training tasks. JuiceFS supports warming up metadata cache and local data cache in the client. The `juicefs warmup` command builds cache in advance, so that the cache is available at the beginning of the training task to improve efficiency.
Increasing buffer size
Buffer size also affects read performance. By default, the buffer size is 300 MB. But in high-throughput training scenarios, this may not be enough. You can adjust the buffer size according to the memory resources of the training node.
Generally speaking, the larger the buffer size, the better the read performance. But do not set a value too large, especially in container environments where the maximum memory is limited. It’s necessary to set the buffer size based on the actual workload and find a relatively reasonable value. You can use the `juicefs stats` command introduced earlier in the article to monitor the buffer usage in real time.
If you have any questions or would like to learn more, feel free to join our discussions on GitHub and community on Slack.
About the author
Changjian Gao, a technical expert at Juicedata, is a core member of the team that helps build the JuiceFS open source community.