















Conda is a highly popular environment and package management system in artificial intelligence (AI) application development. It’s widely appreciated for its ability to create virtual environments isolated from system resources with ease.
Conda supports rebuilding the same working environments across different operating systems. However, there are still challenges in environment sharing and reuse. For example, reusing the same environment on different machines often requires several manual steps and can lead to dependency inconsistencies. In addition, managing multiple environment versions and keeping them synchronized can be tedious for rapidly iterating projects.
As a cloud-native distributed file system, JuiceFS simplifies the process of sharing data and environments significantly. Developers can store Conda environments on JuiceFS to enable environment configuration sharing and real-time access. JuiceFS’ cross-platform compatibility ensures seamless data sharing across multiple operating systems and cloud environments. This meets complex multi-platform development needs.
In this article, I’ll share the basics of Conda, common methods for sharing Conda virtual environments, and how JuiceFS can simplify environment sharing.
Basics of Conda
Conda comes in two main versions:
- Anaconda, which includes lots of pre-installed data science and machine learning libraries.
- Miniconda, a minimal version that only contains Python and Conda environment management tools.
| Feature | Anaconda distribution | Miniconda |
|---|---|---|
| Created and published by Anaconda | Yes | Yes |
| Includes Conda | Yes | Yes |
| Includes Navigator | Yes | No |
| Number of packages | 300+ | < 70 |
| Installation size | ~4.4 GB | ~480 MB |
Conda is an open-source, cross-platform tool that supports Linux, Mac, and Windows. Although installation methods are slightly different between systems, you can refer to the official documentation for details. This article will not cover installation instructions.
Viewing virtual environments
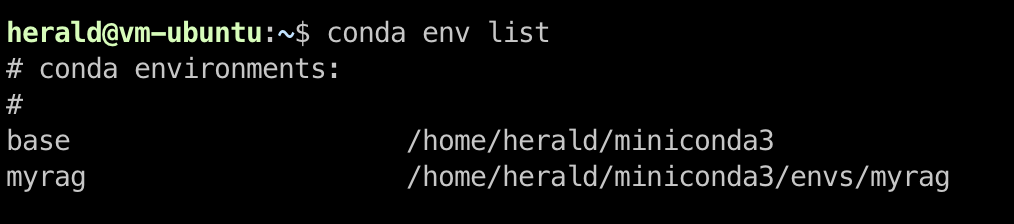
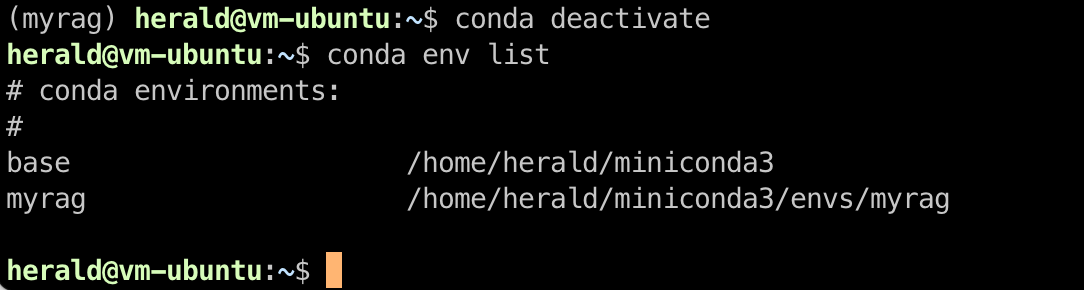
By default, Conda stores virtual environment data in its installation directory. You can use the conda env list command to view details. The following figure shows the default virtual environment path on a Linux system.

Creating a virtual environment
To create a new virtual environment, use the create command. For example, the following command creates a virtual environment named myrag. The process is quick, and you can confirm creation instantly.
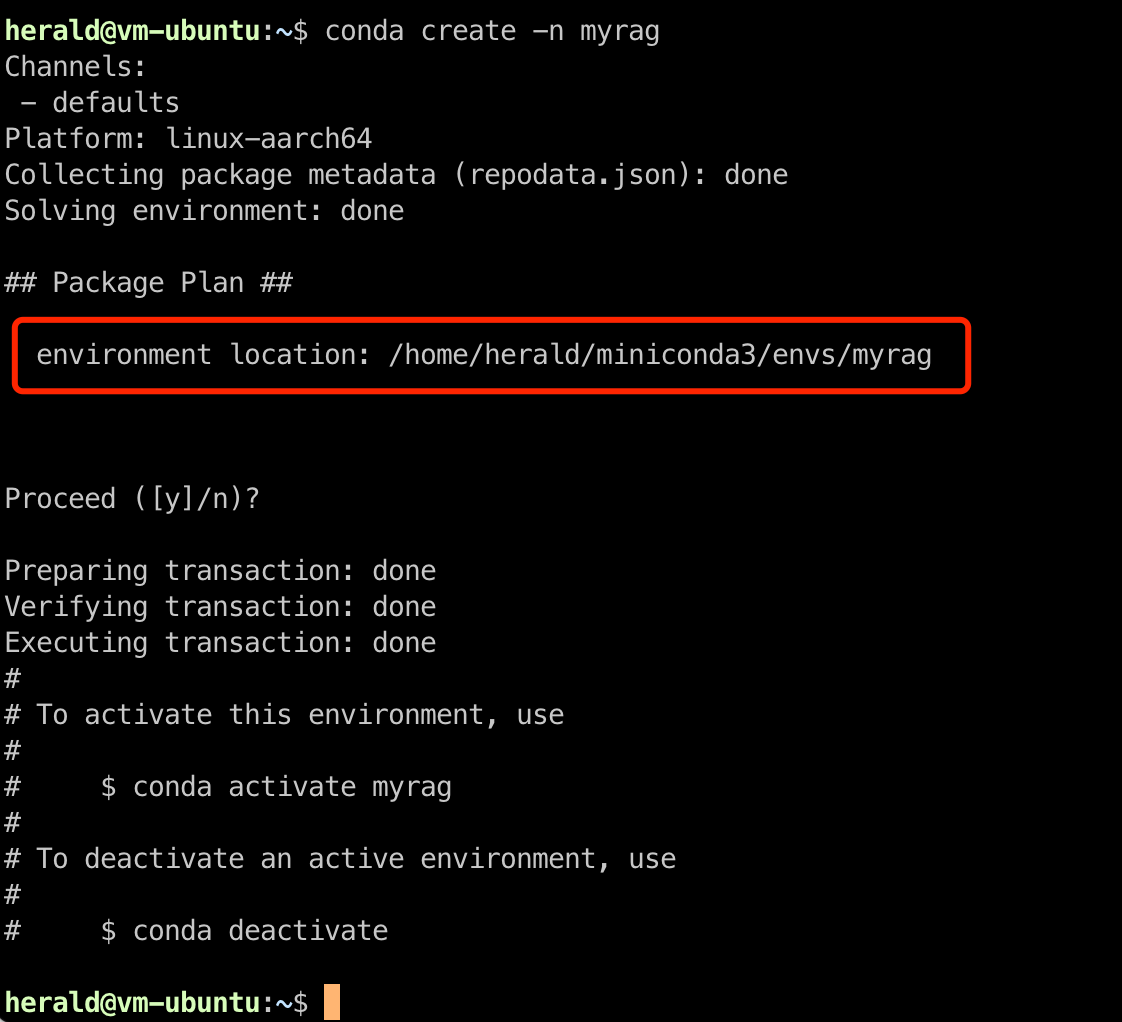
New virtual environments are stored in the $base/envs/ directory of Miniconda.
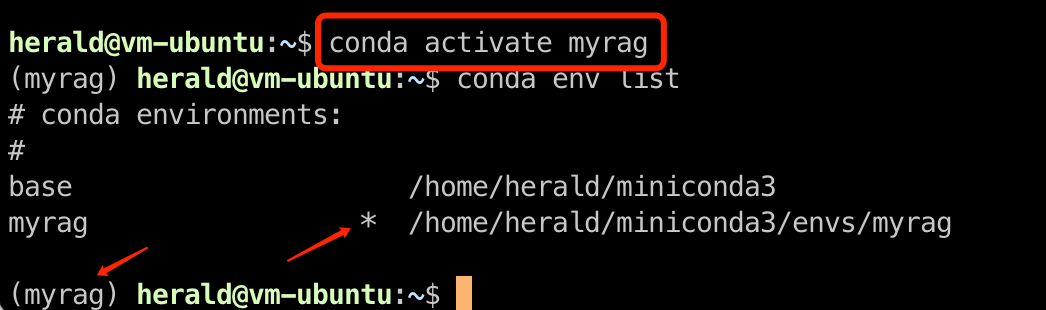
Activating a virtual environment
Activate a virtual environment using the activate command. Activated environments are marked with an asterisk (*), and the virtual environment name appears before the terminal prompt.
Basic usage
Once activated, you can use conda install to install various packages and libraries from the Anaconda repository. For example, in the myrag environment, the current Python version might be 3.12.3.

Running the command conda install conda-forge::python updates Python to version 3.13.0.
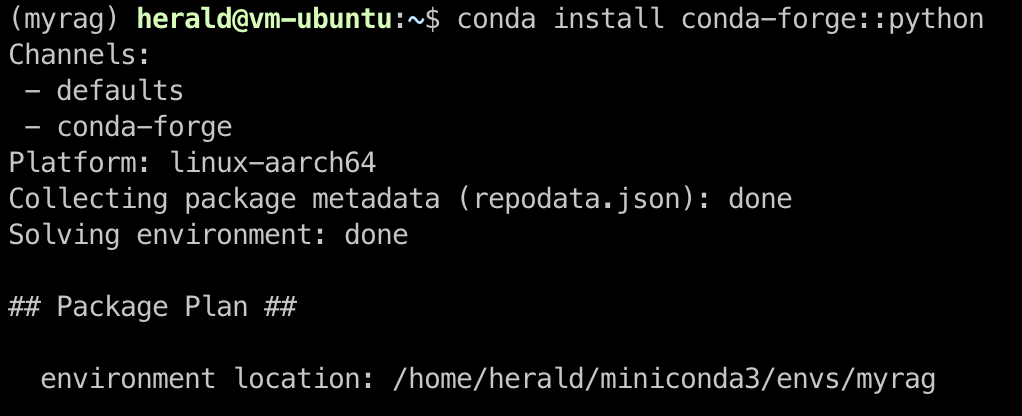

Similarly, you can install specific versions of NodeJS, Rust, Golang, Java, and more in the virtual environment. Packages installed with conda install are stored in the virtual directory, isolated from the operating system and other environments.
Exiting a virtual environment
To exit a virtual environment, run the conda deactivate command.
Challenges of reusing virtual environments
Modern development environments are often complex and diverse, involving multi-person, multi-machine collaboration. Individual developers may also maintain multiple development environments simultaneously. Efficiently reusing a pre-configured development environment across devices saves time and effort while preventing issues like version inconsistencies.
Common methods for sharing Conda environments include:
- Sharing
environment.ymlconfiguration files - Using the
conda-packtool - Directly sharing virtual directories
Sharing configuration files
This approach involves exporting information about the current environment, including installed packages, dependencies, and paths, to an environment.yml configuration file. The file can then be used to recreate the environment on other devices.
# Export environment configuration
conda env export > environment.yml
Copy the configuration file to the target device and rebuild the virtual environment:
# Create the virtual environment from the configuration file.
conda env create -f environment.yml
This method is officially recommended by Conda. It’s advantageous because it works across systems and architectures. It shares a list of materials (rather than materials). Therefore, on the target device, you need to install the required resources according to the list. However, for environments with many packages, this approach requires downloading resources again on the target device, which can be time-consuming in poor network conditions.
Using packaging tools
This method involves using tools like conda-pack to package the virtual environment into a compressed archive, which can then be extracted and used on the target device.
# Install conda-pack.
conda install conda-pack
# Package the current environment.
conda pack -n xxx
conda-pack will package the virtual environment into a tar.gz compressed package and copy it to the target device. You can decompress it and use it directly.
This method addresses some shortcomings of the first method, particularly for environments with numerous packages. However, it does not support real-time synchronization of environment changes across devices. In addition, environments containing editable packages installed with pip or setup.py cannot be packaged.
Directly sharing virtual directories
This approach involves copying or sharing the Conda virtual directory with other devices. While it is the simplest method, it has significant limitations. Virtual environments may contain hardcoded paths that are different between devices. This may cause compatibility issues. This method requires the same CPU architectures and operating systems across devices.
The methods above of reusing virtual environments have their own pros and cons and suitable scenarios. It’s difficult to determine which one is better. But what is certain is that an efficient reuse environment requires a reliable data sharing solution.
Especially for rapidly changing projects such as AI applications, the consistency and efficient collaboration of the development environment are particularly important. When there are a large number of machines, the resources in the environment change frequently, and all require the use of a consistent virtual environment, it’s necessary to use professional tools like JuiceFS that can easily provide multi-device data sharing capabilities to meet the needs.
Using JuiceFS to host Conda virtual environments
JuiceFS is a cloud-native distributed file system that uses object storage as its backend and a dedicated database for metadata management. This design enables JuiceFS clients across different clouds and regions to efficiently share and access the same data. With built-in caching and data consistency guarantees, JuiceFS is ideal for scenarios requiring reliable multi-client data sharing.
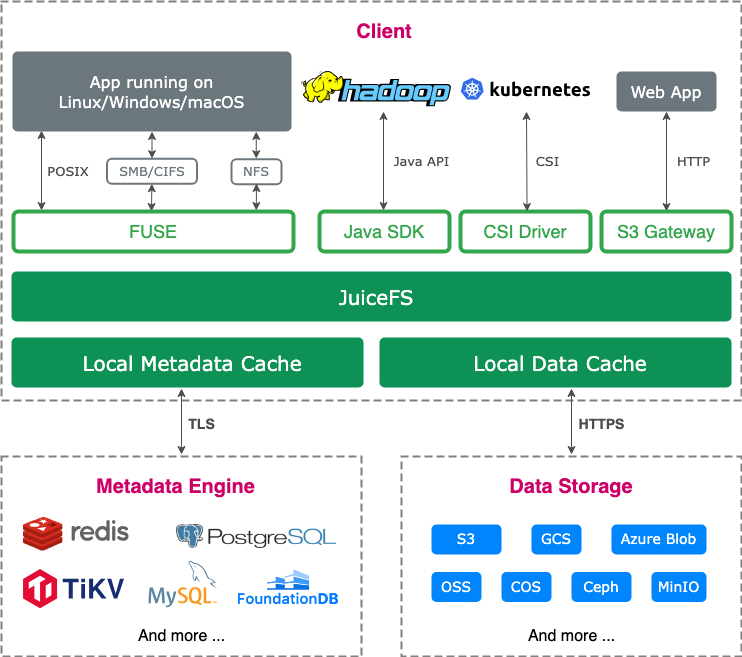
As an open source, easy-to-use, and powerful distributed file system, JuiceFS can achieve efficient access and sharing of data in different environments. Its low latency and high concurrency capabilities allow developers to quickly access and synchronize the Conda virtual environment, significantly reducing the time of environment configuration and synchronization.
Introducing JuiceFS into the development environment and flexibly using its sharing and caching features can give Conda convenient resource sharing capabilities.
Preparing JuiceFS
JuiceFS is open-source and can be freely distributed under the Apache 2.0 license.
Tip: If you have higher performance requirements, you can choose JuiceFS Cloud Service or on-premises deployed Enterprise Edition. They are driven by Juicedata' self-developed high-performance distributed metadata engine and can carry larger-scale data.
If you’re using JuiceFS Community Edition, you can set up a file system by purchasing nearby object storage and databases (such as Redis, Postgres, and MySQL). The creation process is easy and detailed in the official document.
The following example creates a file system named myjfs using Redis and MinIO built by the local intranet (the metadata engine is redis://192.168.3.18/1).
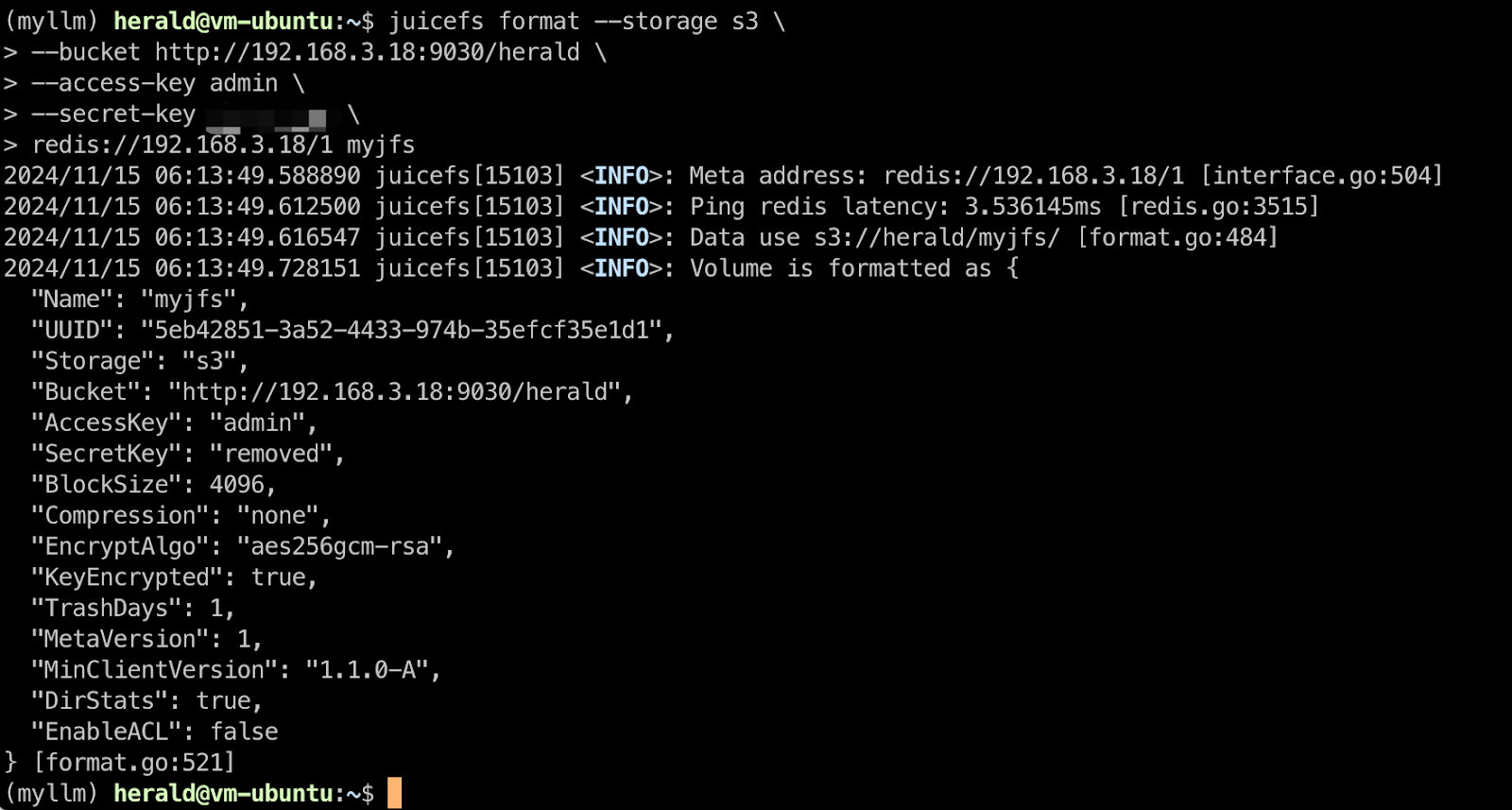
After creating the file system, the next step is to mount it. You can choose any desired mount point. In this example, the -d option is used to mount the file system in daemon mode to the /myjfs directory. In addition, the --writeback mode is enabled, which writes data to the local cache disk first and asynchronously uploads it to the object storage. This provides faster write speeds.
Note: The
--writebackmode requires reliable disk performance, as data is temporarily stored in the cache disk before it’s uploaded to the object storage. To prevent incomplete writes, take precautions against power outages during data writing.
sudo juicefs mount -d --writeback redis://192.168.3.18/1 /myjfs
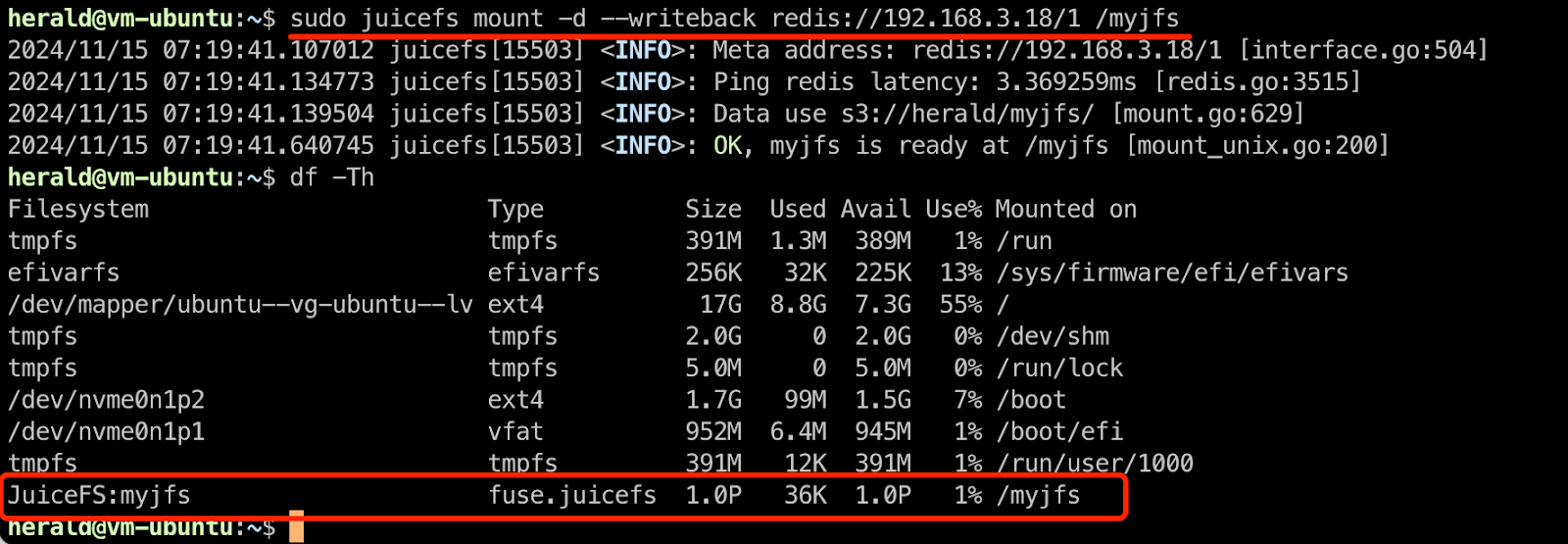
JuiceFS is a distributed file system that can be mounted on any machine capable of accessing the Redis and MinIO services it relies on. With the JuiceFS client, you can mount the file system on multiple machines simultaneously.
Now, you can treat the JuiceFS mount point as a high-performance network disk for sharing files like environment.yml or compressed packages exported with conda-pack. You can also configure Conda's default storage path to point to the JuiceFS mount point (/myjfs in this example) so that virtual environments can be shared across all devices.
Changing Conda's default storage path
Conda’s default storage path can be changed by modifying its configuration file. On Linux or macOS, this file is located at ~/.condarc, and on Windows, it’s at C:\Users\<username>\.condarc. This file is automatically created the first time you run the conda config command.
You can manually edit the envs_dirs array in the configuration file to define the storage paths for all available virtual environments. Alternatively, you can use the following command to update the path, for example, to /myjfs/conda:
conda config --add envs_dirs /myjfs/conda
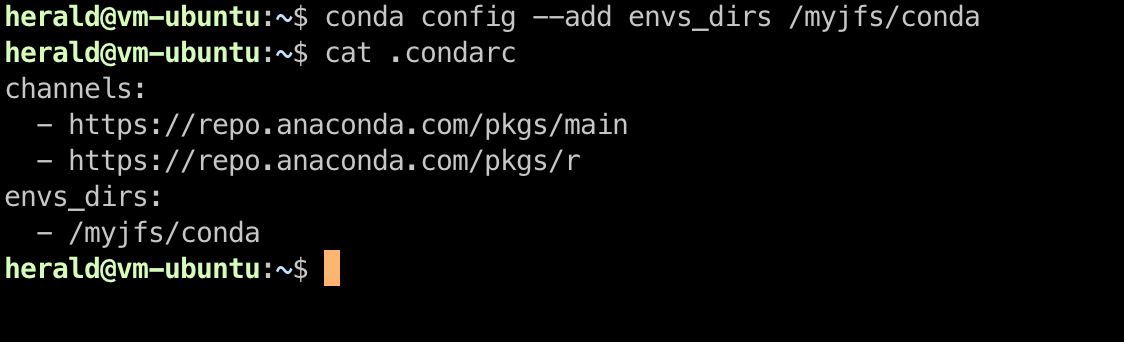
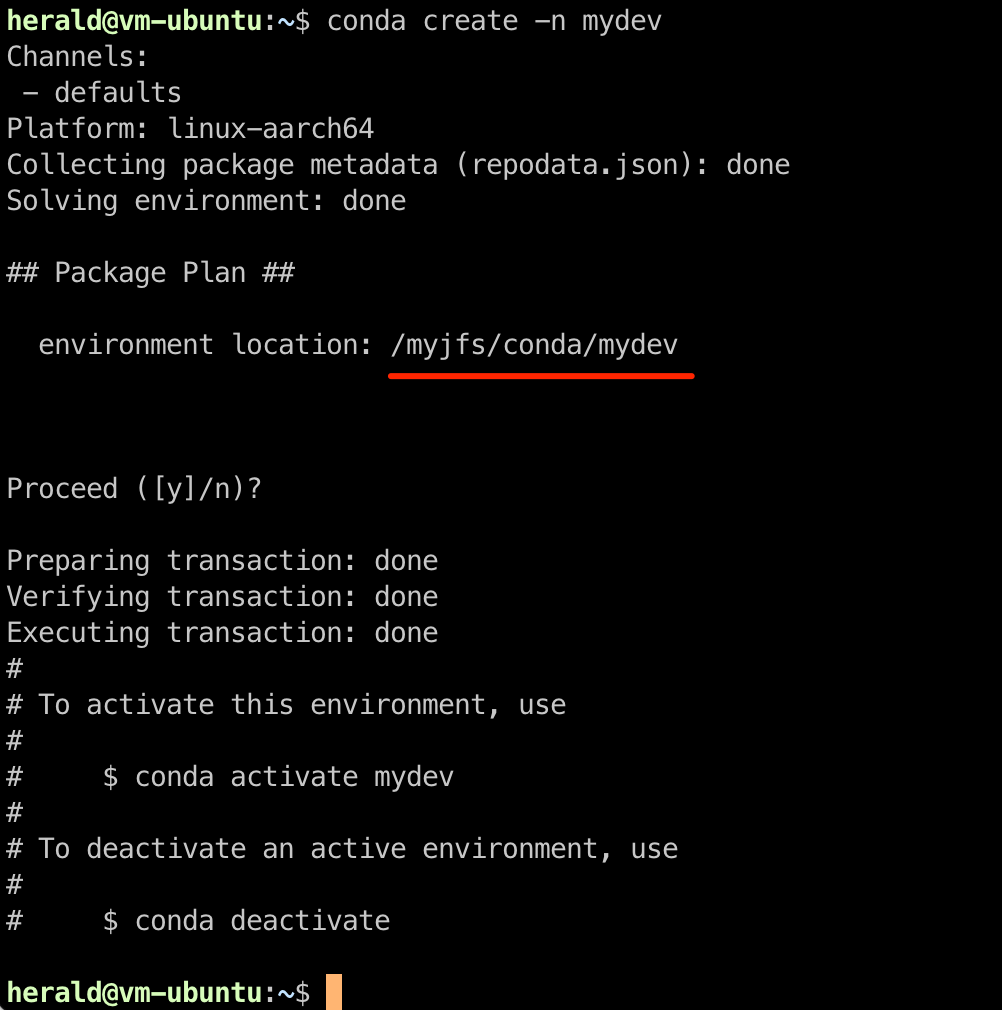
Once the path is updated, any new virtual environments created will be stored on JuiceFS.
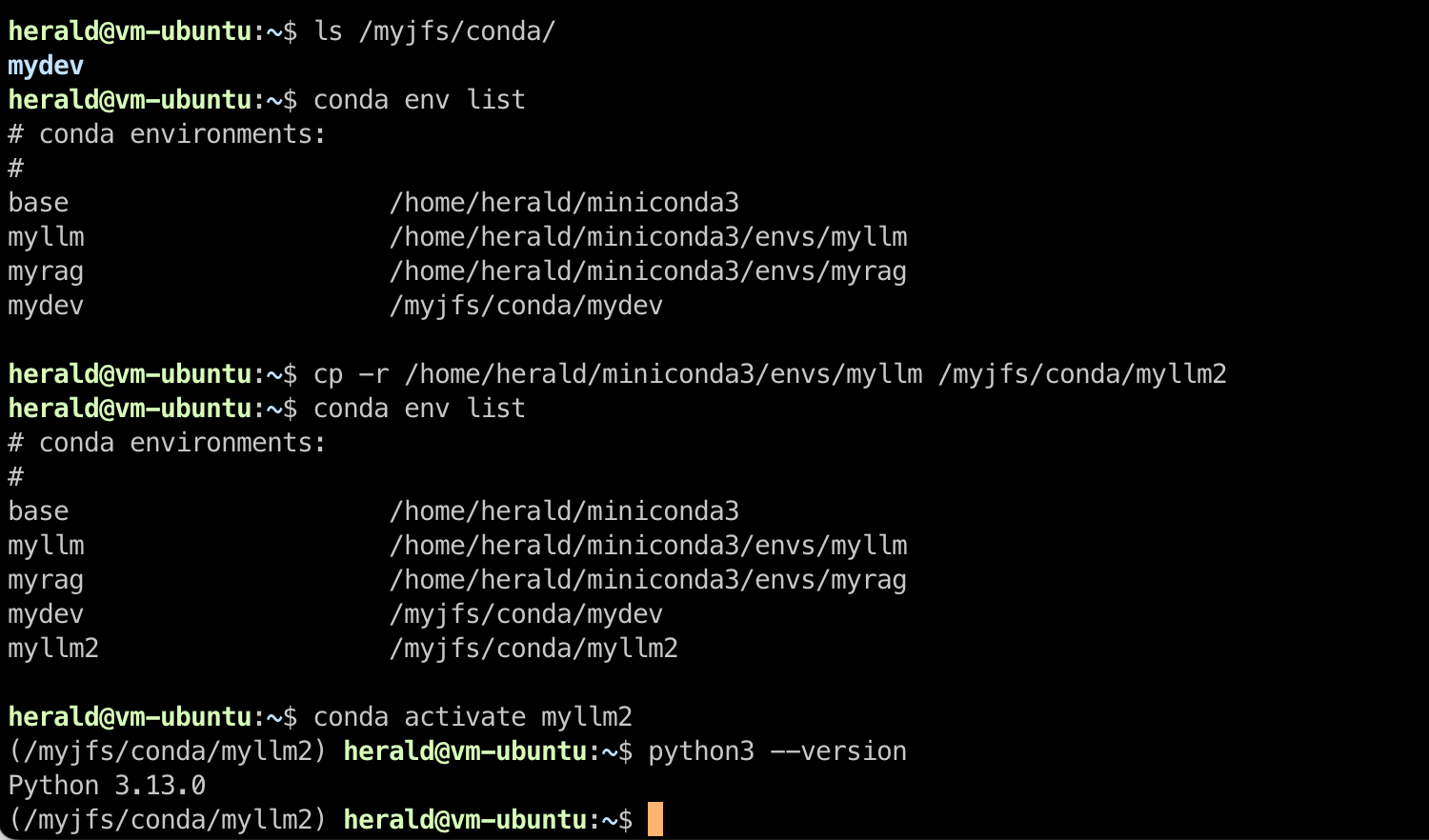
Similarly, you can copy existing virtual environment directories to the JuiceFS mount point and use them directly.
Speeding up access with warmup
When reusing a Conda environment on another machine, you can accelerate access by preloading the required directories into the local cache using the warmup command provided by JuiceFS. For example, the following command preloads the entire /myjfs/conda directory:

Note
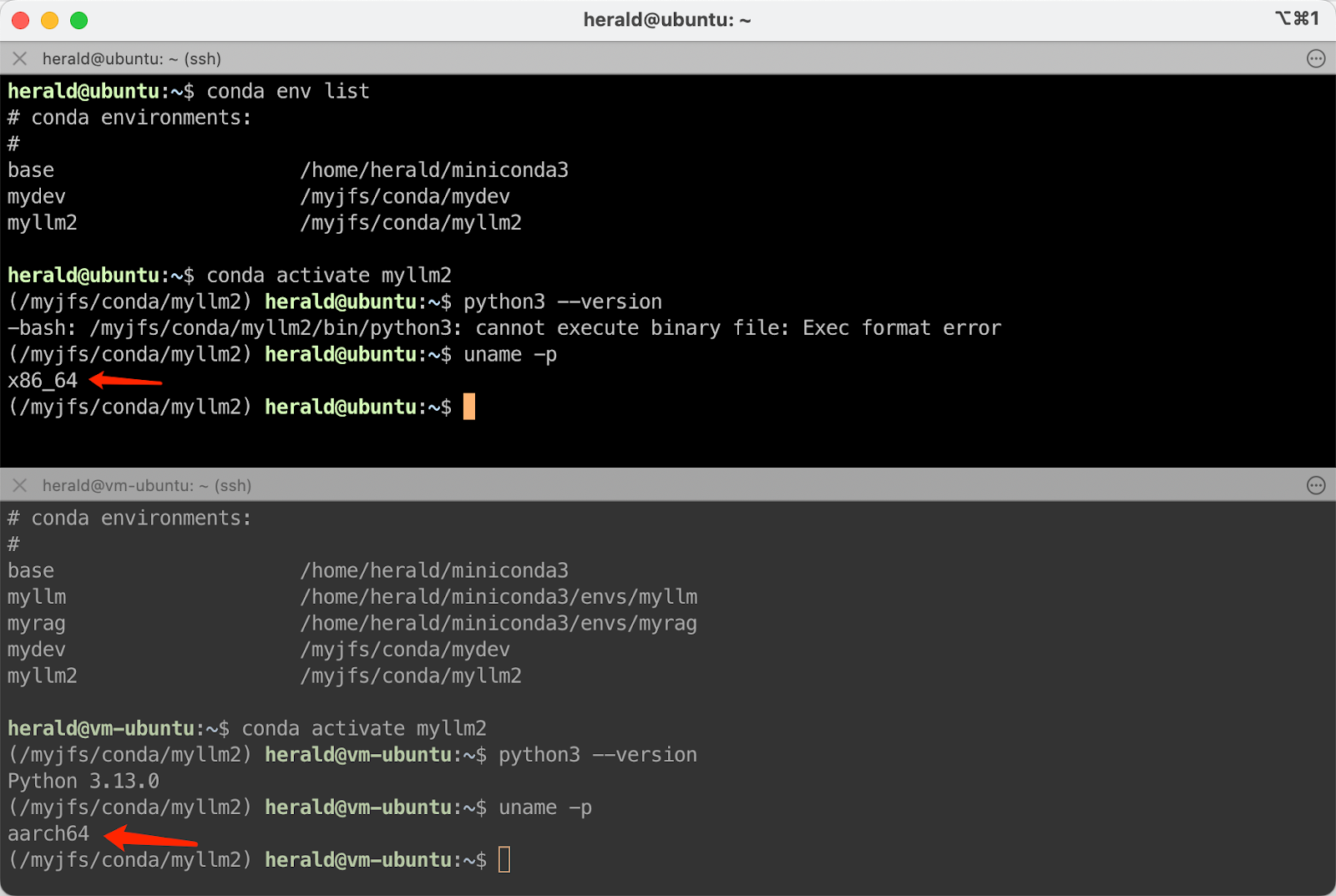
When sharing virtual environments across directories or using exported tools, note that Conda environments created on systems with different CPU architectures cannot be reused. This is because the packages in a Conda environment are compiled for specific CPU architectures.
For example, in the scenario shown below, the system is x86_64 architecture. While it can activate a shared virtual environment, it cannot execute the programs in it because the environment was created on the aarch64 architecture system. The two architectures are incompatible.
Other performance considerations
Using JuiceFS as the storage path for Conda virtual environments may result in slower read/write speeds compared to local disks. This is due to the cloud-based nature of JuiceFS, where the underlying object storage and database are network-based, introducing some latency. To optimize performance, you can try the following:
- Deploy a local database and object storage in an intranet environment to minimize the distance between resources and devices.
- Equip the mounting machine with faster SSDs to ensure the cache is written to a high-speed disk.
- Increase bandwidth to eliminate network bottlenecks.
In addition, you can adapt your method of sharing Conda environments based on their type and scale, ensuring that both Conda and JuiceFS operate in their optimal states.
Conclusion
This article introduced how to effectively reuse Conda virtual environments in a multi-machine environment using JuiceFS, along with key considerations. We hope the tips and experiences shared here will enhance your daily development and team collaboration, boosting overall efficiency.
We encourage you to try these methods and explore further optimizations in practice. If you encounter any issues during configuration or usage, feel free to join JuiceFS discussions on GitHub and community on Slack to share feedback, ask questions, and engage in discussions. Your contributions will help advance the entire community.