















Today, containerization technology can be said to be everywhere, Docker from the initial stars, to now is also a generation of excellent alternatives, Kubernetes, Podman, LXC, containerd and other technical terms more and more frequently appear in the public eye. But no matter how the technology changes, the underlying logic of containerization technology has not yet changed, data persistence is always an important matter that containerization technology has to take seriously.
Containers and Data Persistence
As we know, Docker containers are layered storage, as shown in the following architectural diagram, the image consists of a series of read-only layer, the top layer of the container is a read-write layer, data can be read directly from any layer, rewrite data need to be copied from the read-only layer to the read-write layer first, that is, copy-on-write mechanism. This data read-write mechanism can provide high space utilization, but inevitably lower performance than the native file system, and the container storage layer is volatile, as the container is destroyed, the data stored on the read-write layer will also be deleted.
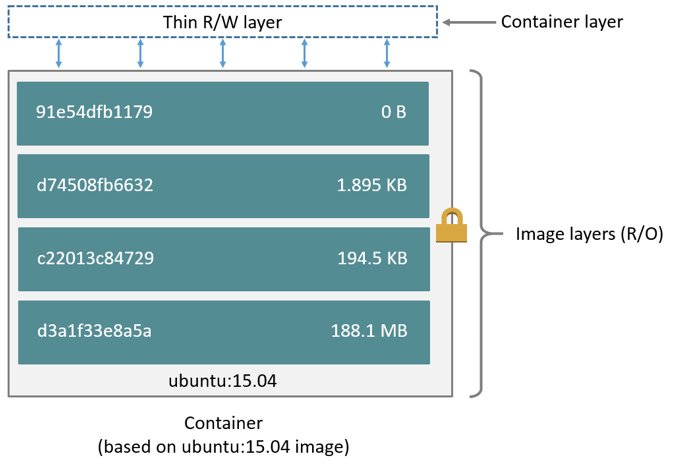
It is suitable to use containers to store data generated by programs during runtime that does not require long-term storage, but for write-intensive applications, such as databases, and for data that needs to be stored for a long time or shared among multiple containers, it is important to store the data in a persistent and reliable way.
For containerized technologies such as Docker, Podman, etc., data persistence is mainly done using volumes or bound mounts.
Volume
Volumes are the preferred method of data persistence for containerization technologies. Take Docker as an example, volumes are managed by the Docker process and cannot be read or written directly by external programs, which can improve storage security to a certain extent. Volumes can be created, read/write, migrated or deleted through the Docker CLI or Docker API, and can be safely shared by multiple containers.
Bind Mounts
Bind mounts is to map the directory of the host to the directory specified in the container, so that it is equivalent to storing the data generated by the container directly on the host, it is a convenient way to share data between the container and the host. However, the bound mounted directory is transparent outside the container and may be accessed by other processes, so be careful to manage it properly.
From the official Docker documentation, you can see the difference between volumes and bound mounts. Simply put, volumes are easier to manage and migrate due to their unique format, easier to share across multiple containers, better performance than bound mounts in Mac or Windows environments, and so on. Of course, it is pointless to discuss the advantages outside of the scenario, and in fact both basic data persistence methods have their unique advantages in different scenarios.
The challenge of data persistence
Volumes and bound mounts solve the data persistence problem for containers, but over time, persisting data on the host will inevitably present some new challenges.
- The challenge of host storage scale-up
- The Challenge of Sharing Data Across Platforms
- The Challenges of Data Offsite Disaster Recovery
- Performance Challenges of Large Scale Data on the Cloud
- The Challenges of Data Migration
It is not difficult to understand that data persistence storage in the host, sooner or later will always face the problem of storage scale-up. Even if the pre-planned computing cluster does not have the problem of insufficient storage capacity in a short period of time, there may be other challenges, such as the need for data to flow between different regions and different cloud computing platforms, or the need to do off-site disaster recovery and off-site migration of persistent data, and so forth are often accompanied by the generation of data at the same time, through Most of the problems can be solved by "dedicated networks" and "establishing clusters of the same size offsite", but this will obviously increase the cost of human and financial resources exponentially.
Is there a simpler, more flexible and cost-effective solution for data persistence?
Persistent container data with JuiceFS
JuiceFS is an open source high-performance shared file system that can access almost any object storage locally as a local disk, and can also be mounted and read on different hosts across platforms and regions at the same time. It uses the architecture of "data" and "metadata" separate storage, using cloud-based object storage and database, can be shared on any number of networked hosts.
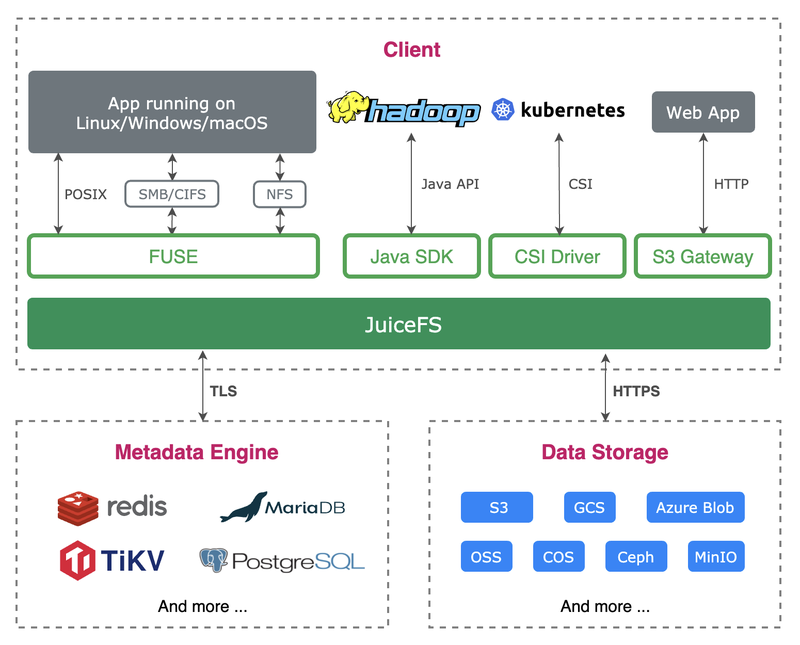
For containerization, JuiceFS can easily map cloud-based storage to containers by bind mount, and for pure containerization scenarios, JuiceFS provides Docker Volume Plugin to easily create JuiceFS-based storage volumes for use and sharing data between containers and anywhere outside containers.
Next let's go through the two ways of using JuiceFS to do data persistence for containers. But before we get started, there is some preparation required.
Preparations
As mentioned earlier, JuiceFS uses an architecture with separate storage for data and metadata, where data is usually stored in an object storage and metadata is stored in a separate database. Whether used directly on the operating system or in a container, creating a JuiceFS file system requires the object storage and database to be prepared in advance.
In terms of underlying storage, JuiceFS adopts a pluggable design, which means that you can choose almost any object storage for data storage, and you can also use local disk or file storage based on WebDAV, SFTP and other protocols. For metadata storage, you can choose Redis, TiKV, MySQL, PostgreSQL and other network-based databases, as well as standalone databases like SQLite. In short, users can flexibly match according to the needs of the scenario, and can either choose the services provided by the cloud computing platform or build the services by themselves.
Considering the performance and network latency of file systems, especially for cases where data needs to be shared between containers, between servers, or between cloud computing platforms, object storage and databases should be located as close as possible to the location where the file system is used. For example, if your Docker is running on Amazon EC2, choosing Amazon's S3 and database to create JuiceFS file system to use will improve read and write efficiency and stability, and will also reduce resource consumption.
For demonstration purposes, we assume that the following cloud computing resources are prepared.
Cloud Server
- Operating System: Ubuntu Server 20.04 x86_64
- IP: 123.3.18.3
Object Storage
- Type: s3
- Bucket endpoint: https://myjfs.s3.amazonaws.com
- Access Key: mykey
- Secret Key: mysecret
Redis Database
- redis://mydb.cache.amazonaws.com:6379
- Password: mypassword
Using Bind Mounts
Bind Mounts is to map directories on the host to the container, and when using JuiceFS storage, it is to map JuiceFS directories mounted on the host to the container.
When creating a JuiceFS file system, we can either use the client on the host or use the official JuiceFS client image. To keep things simple, we will create the file system on the host, first installing the JuiceFS Community Edition client using the one-click install script:
curl -sSL https://d.juicefs.com/install | sh -Then create a filesystem called myjfs using the prepared object store and database, and for security purposes, write the relevant passwords to the environment variable.
export ACCESS_KEY=mykey
export SECRET_KEY=mysecret
export META_PASSWORD=mypasswordPassword writing to environment variables is not only more secure, but also has fewer command options when formatting the file system, creating the file system:
juicefs format --storage s3 \
--bucket https://myjfs.s3.amazonaws.com \
redis://mydb.cache.amazonaws.com/1 myjfsOnce the file system is created, it can be mounted on the server immediately:
export META_PASSWORD=mypassword
sudo juicefs mount redis://mydb.cache.amazonaws.com/1 /mnt/myjfs -d/mnt/myjfs is the entry point for storage in the JuiceFS file system, all the files will be stored in a specific format to the object storage, and the related metadata will be stored in the database. Now we can map /mnt/myjfs or any subdirectory of it directly to a Docker container to use as persistent storage.
For example, we create a MySQL database container that uses /mnt/myjfs/mysql on the host as the persistent storage for the database.
sudo docker run --name mysql -d \
-v /mnt/myjfs/mysql:/var/lib/mysql \
-e MYSQL_ROOT_PASSWORD=my-secret-pw \
mysql:8This way, all database related data is saved to JuiceFS, and since it is a bound mount, we can see the database generated content in real time on the host in /mnt/myjfs/mysql. Of course, since the database directory is transparently visible to the host, this is bound to have some security risks, for which we can use storage volumes.
Using Volumes
The JuiceFS Docker Volume Plugin that allows us to easily create JuiceFS file systems and create cloud-based storage volumes on them, but this approach is only available for Docker environments and not for other containerization technologies.
Install Volume Plugin
sudo docker plugin install juicedata/juicefs --alias juicefsCreating Storage Volumes
Creating a volume is simple, just repeat the -o option to specify the information about the file system. The following command creates a JuiceFS file system named myjfs and creates a storage volume named myjfs on top of it.
sudo docker volume create -d juicefs \
-o name=myjfs \
-o metaurl=redis://:[email protected]/1 \
-o storage=s3 \
-o bucket=https://myjfs.s3.amazonaws.com \
-o access-key=mykey \
-o secret-key=mysecret \
myjfsUsing Volumes
Then we mount the myjfs volume to the container, following the example of the MySQL database container from earlier, with the following command:
sudo docker run --name mysql -d \
-v myjfs:/var/lib/mysql \
-e MYSQL_ROOT_PASSWORD=my-secret-pw \
mysql:8This way, all data generated by the database is stored in a JuiceFS file system called myjfs.
Troubleshooting
If you encounter exceptions when using JuiceFS Docker Volume Plugin, you can refer to the official documentation to troubleshoot.
The relationship between volumes and JuiceFS
When you create a volume using the JuiceFS volume plugin, you are essentially creating a JuiceFS file system that emulates a storage volume. As we know, a JuiceFS file system is composed of an object storage Bucket and a database. In the view of the volume plug-in, this file system consisting of the Bucket and the database will provide persistent storage for the container in the form of a storage volume, and all data stored to the volume plugin will be stored in the JuiceFS file system.
Because the JuiceFS file system is only emulated as a storage volume, the file system itself is not changed in any way, so there is no difference between this file system and the one created directly with the JuiceFS client, and you can mount, read and write to it on any device with the JuiceFS client. As an example, the myjfs volume created earlier can be mounted to read and write on the host computer or any other computer:
export META_PASSWORD=mypassword
sudo juicefs mount redis://mydb.cache.amazonaws.com/1 /mnt/myjfs -dOnce mounted, what you see on /mnt/myjfs is consistent with what you see in the mysql container /var/lib/mysql directory, and what you write is visible and consistent across all mount points, both outside and inside the container, in real time.
Creating Multiple Volumes
Now we know that a volume corresponds to a JuiceFS file system, and a file system is composed of a bucket and a database. When you need to create more than one volume, you need to prepare an additional set of bucekt and database.
Hint: You can create multiple JuiceFS file systems using the same Object Storage Bucket, just make sure the file system names are different from each other.
In the previous section, we have created a file system called myjfs using Redis database 1, which creates a subdirectory myjfs on the object storage Bucket to store data. Now we can use database 2 to create another storage volume called fs2 .
sudo docker volume create -d juicefs \
-o name=fs2 \
-o metaurl=redis://:[email protected]/2 \
-o storage=s3 \
-o bucket=https://myjfs.s3.amazonaws.com \
-o access-key=mykey \
-o secret-key=mysecret \
fs2Although the new volume use the same Bucket, JuiceFS creates a separate fs2 directory under the Bucket to store data because the file system names are different, so there is no conflict with the previous myjfs, just make sure each file system uses a separate database.
Sharing, Disaster Tolerance and Migration
The transparent read and write nature of data both inside and outside the container makes persistent data on JuiceFS very easy to share and migrate. As long as the object storage and database that make up the file system are accessible over the network, they can be mounted and access on any host with a JuiceFS client installed.
For example, if a container is deployed in Amazon Cloud and another container is deployed in AliCloud, when you need to share a copy of data on both containers, you can simply create a JuiceFS-based storage volume with the same Bucket and Database on both ends. We know that a storage volume is essentially a JuiceFS file system, and furthermore, because the JuiceFS file system supports simultaneous shared mounts on any number of devices, we can share the same JuiceFS storage volume on any platform and any number of containers according to actual business needs.
By analogy, JuiceFS' ability to share mounts anywhere gives users the flexibility to adjust their data disaster recovery and dynamic migration strategies.
Summary
This article introduces the method of using JuiceFS as container data persistence, starting from the data persistence principles and requirements of containerization technologies such as Docker and Podman, and analyzing the principles and usage examples in order to help readers better understand and get started.