















JuiceFS is a distributed file system built on object storage. To enhance write efficiency, it offers a writeback feature, where data is first written to the local disk cache of the application node before being asynchronously written to object storage. This significantly reduces write latency. For example, in a test of writing 10,000 entries, enabling writeback allows the data transfer to complete within 10 seconds, whereas without writeback, it took 2 minutes. However, the writeback feature also comes with certain risks and usage limitations.
In this article, we’ll deep dive into JuiceFS' write mechanism and explain how writeback works, its applicable scenarios, and important considerations. We hope this article can help you fully understand both the advantages and potential issues of this feature.
JuiceFS standard write mode
The JuiceFS data writing process involves two steps:
- Data chunks are written to object storage and returned synchronously: The client writes the split data chunks to object storage. Regardless of the write speed of the object storage (even with latency as high as hundreds of milliseconds), JuiceFS waits for acknowledgment before proceeding.
- Metadata write: After the object storage responds, JuiceFS writes the metadata.
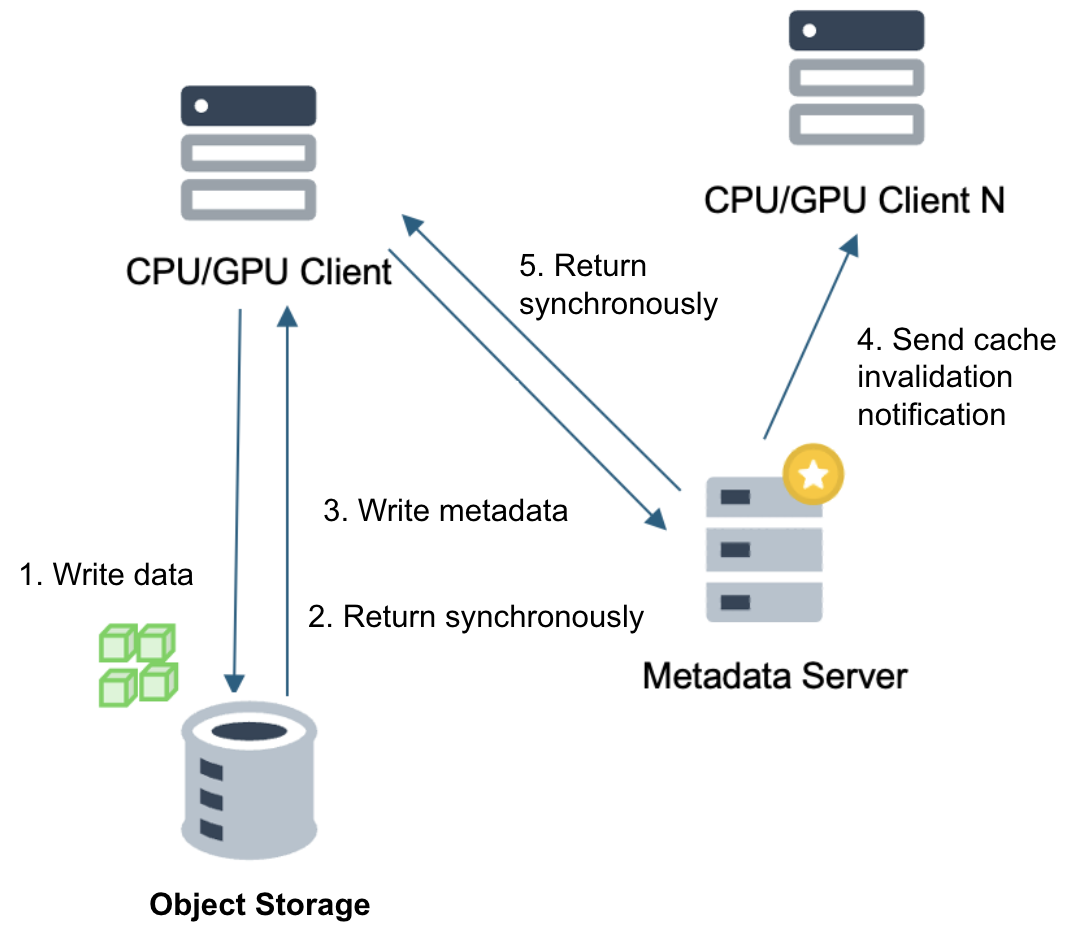
The Community and Enterprise Editions are different in their cache invalidation mechanisms. This leads to different approaches in handling data consistency:
- The Community Edition: Each client has an in-memory metadata cache with a default expiration time of 1 second. Due to the lack of an active notification mechanism in the Community Edition, clients can only passively wait for the cache to expire to obtain the latest data. As a compromise, the default time is set to 1 second; increasing this setting is only recommended in read-only scenarios.
- The Enterprise Edition: The Enterprise Edition supports active cache invalidation notifications. When a file is modified, it sends invalidation notices to all clients using that file, instructing them to request data directly from the metadata server upon the next read instead of using their local cache. This allows the Enterprise Edition to maintain longer metadata cache time, further reducing server pressure.
How writeback works
The primary goal of writeback mode is to accelerate the write process. Data is first written to the local disk, and an additional rawstaging directory is created under the cache-dir directory to store local data that hasn't been uploaded to object storage yet. This data is referred to as staging data.
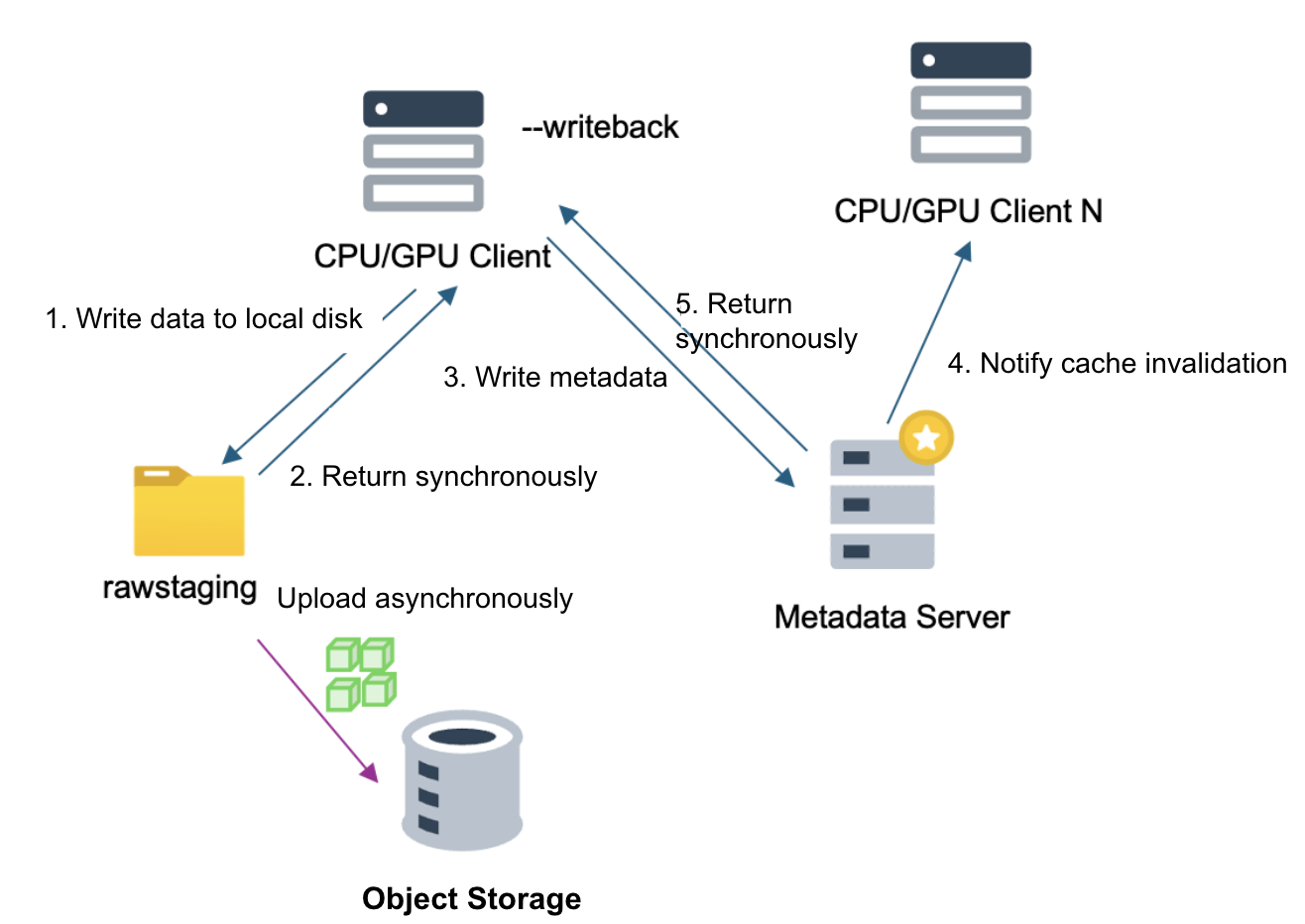
Data is written to the local disk and returned a response immediately. This makes write speeds much faster than direct writes to object storage—typically within milliseconds. High-performance NVMe disks can even achieve sub-millisecond latency. After writing, the client notifies the metadata server that the data write is complete, and the subsequent synchronization process is the same as in standard writes. However, data chunks are uploaded asynchronously to object storage. Upload speed and completion time depend on network and node load, making it impossible to predict the exact status initially.
While writeback mode offers higher write speeds, we generally do not recommend it to customers, primarily due to the following two concerns:
- Risk of unuploaded data: Many customers mistakenly assume that data has been successfully written to object storage after they receive a synchronous response. However, the data may still reside locally and not yet be uploaded. If the node is shut down or even destroyed at this point, data will continue to upload after a restart, but if the node is destroyed, the data will be permanently lost.
- Immediate unavailability on other nodes: Files written to the local staging directory are inaccessible to other nodes until uploaded to object storage. This violates read-after-write consistency and breaks close-to-open strong consistency. It may be unacceptable in certain scenarios.
Applicable scenarios for writeback mode
Despite its risks, writeback mode offers significant advantages in improving write speeds, especially in scenarios requiring rapid write responses. For example, when writing a large number of small files, as long as the risks of delayed writes to object storage and data loss due to asynchronous uploads can be effectively mitigated, writeback mode is an efficient and practical choice. You can flexibly adopt it based on your actual needs.
Take the example of writing 10,000 entries into the "numbers" directory in JuiceFS. Without enabling caching or writeback mode, monitoring shows that each PUT request to object storage transfers only a few hundred bytes, with a latency of 20+ milliseconds. Writing 10,000 entries takes approximately two minutes, which is extremely slow.
When writeback mode is enabled, the PUT latency remains unchanged. However, the PUT traffic becomes aggregated, with each request sending tens of thousands of bytes (such as 21 KB or 70 KB). In this case, the application receives a response within 5 seconds, and data transmission completes within 10 seconds, significantly improving efficiency.
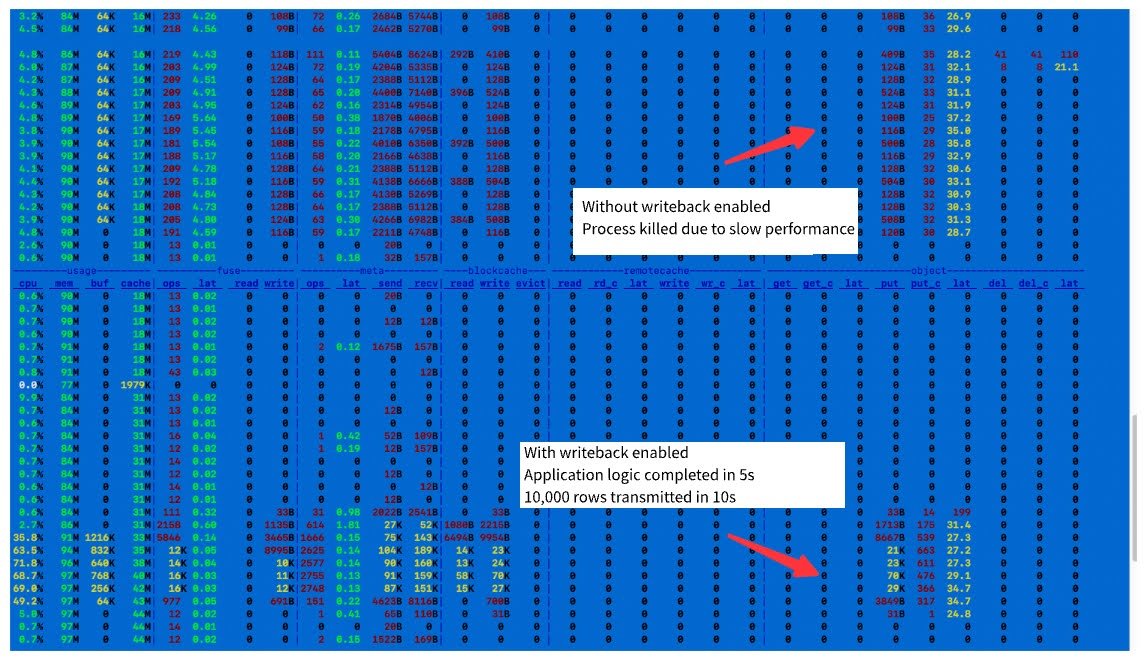
In different scenarios, it’s essential to evaluate the risks. The risk of slow write tasks is the long duration, during which application changes may lead to data issues. In contrast, writing quickly first and aggregating uploads later, while carrying a risk of data loss, shortens the duration. In real-world cases, this efficiency difference can expand from 5 seconds to 5 hours, and the risks posed by application changes during these 5 hours cannot be ignored.
Based on the analysis above, we summarize the recommended scenarios for writeback mode:
- Frequent checkpoint writing in training tasks: For example, some training tasks write checkpoints hourly, and GPUs must wait for a response before continuing. With writeback mode enabled, even if a node fails and cannot recover, the loss is limited to one hour of training data, and the probability of failure is low. From an application perspective, immediate responses after writes significantly improve GPU utilization and reduce waiting time. However, if only one checkpoint is written per day, it’s advisable to wait a few minutes to ensure data is written to object storage before returning, ensuring data security.
- User development environments: For example, in AI scenarios, many users set their home directories on JuiceFS. Without writeback mode, installing a software package may take three to five minutes, whereas with writeback mode enabled, installation time can be reduced to a dozen seconds. Since this is typically a personal directory and rarely shared with other mount points, the risk of data destruction is low. Thus, enabling writeback mode to accelerate operations is recommended.
- Scenarios with numerous small files or temporary decompression: For example, when pulling files from JuiceFS and decompressing them, a large number of small files are involved. Enabling writeback mode can significantly improve decompression speed and efficiency.
- Scenarios with frequent random writes.
Regarding the application of writeback mode, see StepFun Built an Efficient and Cost-Effective LLM Storage Platform with JuiceFS. StepFun uses the distributed file system GPFS as a cache disk and places the staging directory on GPFS to address data security and readability issues. It’s important to note that the number of GPFS nodes should not be excessive, as this may introduce stability risks. Nonetheless, the benefits are significant: during checkpoint data writes, enabling writeback mode greatly improves write fault tolerance and throughput performance.
Future optimization plans
In JuiceFS Enterprise Edition 5.3, we plan to introduce the concept of shared block devices to replace the writeback mode relying on single-node local disks. Simply put, a block device will be simultaneously mounted by multiple clients as the staging directory, ensuring read-after-write consistency. Shared block devices are typically cloud disks with high reliability and low failure rates, effectively addressing data access consistency issues.
However, shared cloud disks have limitations—a single cloud disk can be mounted by 16 clients at most. To address this, we propose a single-mounted device solution: one node mounts the device, and other nodes read data through it. When enough nodes provide enough single-mounted disks, data hotspot issues are partially resolved. This is a promising write acceleration solution on top of object storage.
If you have any questions for this article, feel free to join JuiceFS discussions on GitHub and community on Slack.