















When using JuiceFS, you might have these questions:
- Why isn't the object storage space freed up immediately after deleting files?
- How can I efficiently clean up a large number of files accumulating in the trash?
- Why is the deletion operation so slow or performance degraded when deleting files in batches within a short period of time?
The workflow behind JuiceFS' garbage collection (GC) is quite intricate. It’s hard to intuitively grasp when file states change and resources are truly released.
To pull back the curtain, this article will systematically break down the key processes and underlying logic of GC, explain the roots of common issues, and offer practical advice for efficient cleanup and system maintenance.
Background knowledge: JuiceFS file storage structure
JuiceFS handles file deletion through an asynchronous mechanism. It responds to user delete requests instantly but postpones the actual cleanup for later, when the system is not busy. This approach smooths out workload spikes, reduces system load, and enhances system stability. Furthermore, this phased cleanup strategy offers greater flexibility for potential data recovery.
This efficient design is rooted in JuiceFS' underlying architecture. It employs a separation of metadata and data storage, and manages file data in chunks. When you delete a file, the system doesn't immediately remove the actual data. Instead, it only adds a deletion marker in the metadata layer. The real data reclamation happens later in an asynchronous process.
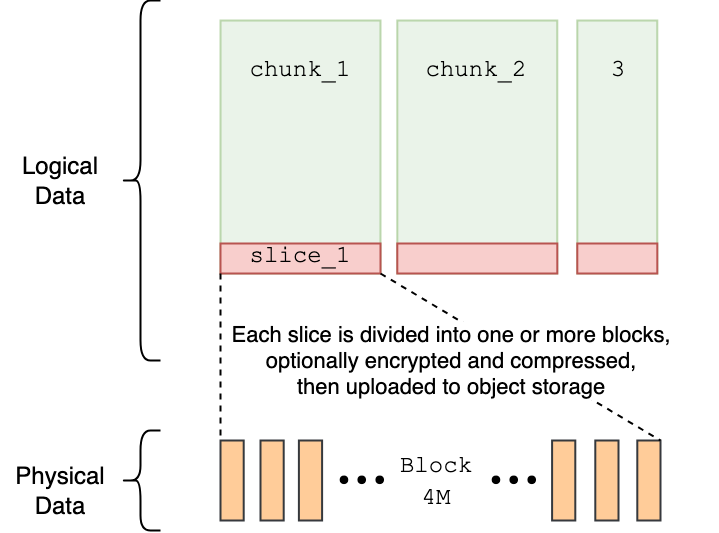
To fully grasp this asynchronous deletion logic, we need to understand how JuiceFS organizes data internally. The system manages file data through chunks, slices, and blocks. This structure not only dictates file performance during storage and access but also directly influences how data is located, referenced, and cleaned up during deletion.
- Chunks: Each file consists of one or more chunks, each with a maximum size of 64 MB. Regardless of file size, all read and write operations locate the corresponding chunk based on offset. This boosts retrieve and access efficiency.
- Slices: This is the unit of writing within a chunk. Each continuous write operation generates one slice. A slice must reside entirely within a single chunk, so its size cannot exceed 64 MB. The process of writing a file typically produces multiple slices.
- Blocks: To improve write efficiency to object storage, each slice is further split into multiple blocks (default maximum size is 4 MB) before being written. Multi-threaded concurrent writing is used to improve throughput.
JuiceFS GC process
Now that we've covered the background, let's walk through the main file deletion workflow. JuiceFS' deletion mechanism can be divided into three key processes:
- Trash management
- File deletion processing
- Underlying slice cleanup
Trash management
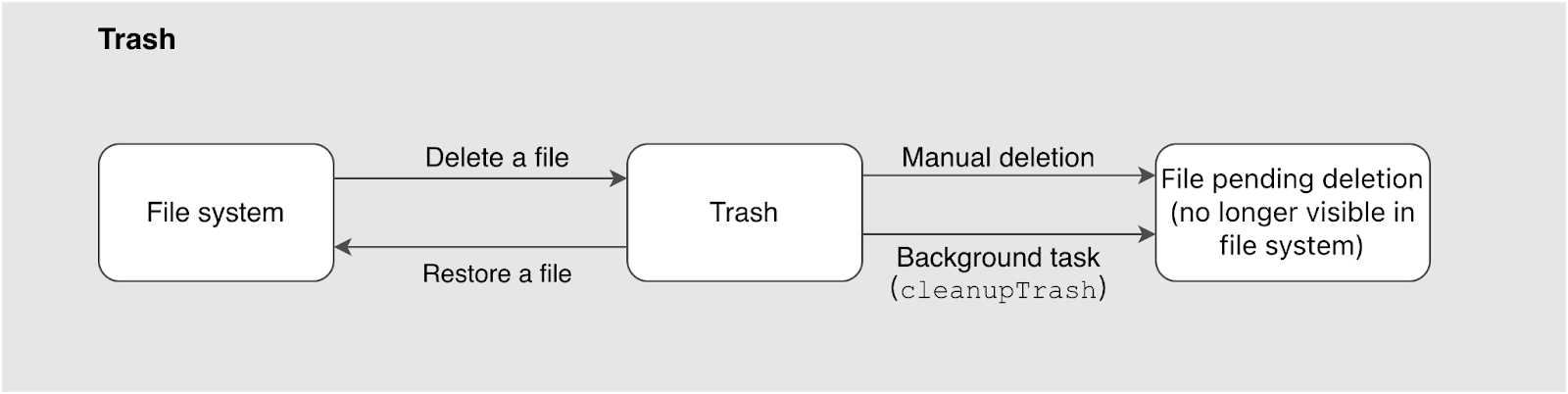
The file deletion journey begins with a user's delete request. When an upper-layer interface initiates a file deletion, the system doesn't remove the file immediately. Instead, it moves the file to the trash (enabled by default). In this step, only the pointer from the file's parent directory changes; the file's other metadata and its actual content remain unchanged.
Once a file stays in the trash beyond its configured retention period, a background cleanup task or a manual operation converts it into a "pending deletion" state, pushing it into the subsequent cleanup pipeline.
To better understand and manage files in the trash, let's look at its directory structure and operation.
The trash resides in the .trash directory under the mount point. Deleted files are saved into subdirectories named based on the deletion time (accurate to the hour), for example, .trash/2024-01-15-14/. To avoid file name conflicts, files moved to the trash are automatically renamed following this pattern: <ParentDirID>_<FileID>_<OriginalFileName>.
The system also provides a flexible recovery mechanism for files in the trash. See Trash for details. Files in the trash aren't kept forever. JuiceFS cleans them up in two ways:
- Automatic cleanup: A background task (
cleanupTrash) runs hourly. It gradually cleans files based on the set retention period, marking them for deletion. - Manual cleanup: You can use the OS
rmcommand or thejuicefs rmrtool to directly delete files or directories from the trash. Manual cleanup typically reclaims space faster than waiting for the background task, but the process is asynchronous. The actual deletion of objects from storage is handled by subsequent tasks, which will be covered later.
Furthermore, trash cleanup performance is constrained by the processing capacity of a single client. When dealing with massive file deletions, consider mounting JuiceFS on multiple clients and performing manual cleanup simultaneously to significantly boost the overall efficiency of large-scale deletion operations.
File deletion
In this stage, the system first checks if the file is still in use:
- If the file hasn't been closed (for example, it's still held open by a process), it's placed in a
sustainedstate, waiting for all references to be released before re-entering the cleanup workflow. - If the file is closed, the system marks it as a deletable file (internal state
delfile), indicating it's ready for the deletion queue.
Next, the system attempts to add these deletable files (delfile) to the file deletion queue. This queue acts as a buffer for files awaiting cleanup. To prevent impacting system performance, the queue has a limited capacity. If the queue is full, deletion requests for regular files are temporarily skipped, letting the background cleanup task handle them later.
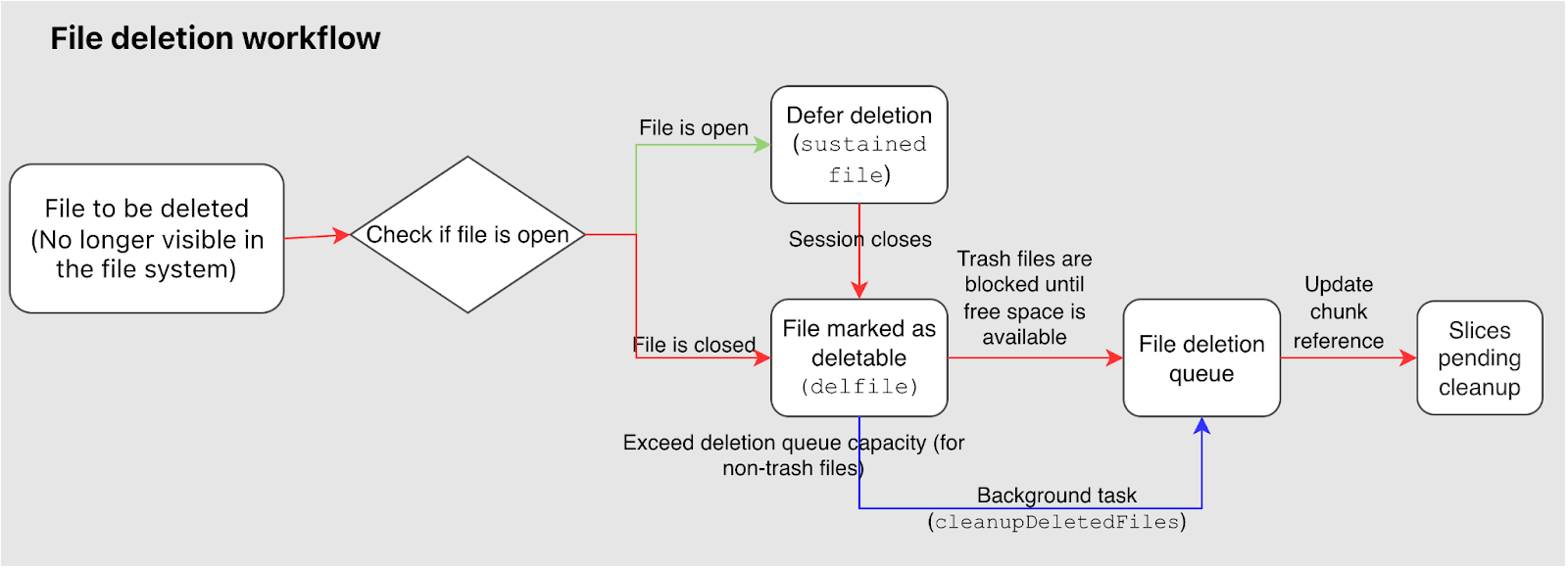
For files in the trash, if a user performs a manual delete operation while the deletion queue is full, that operation will block synchronously until space becomes available in the queue. This ensures manual deletions are queued within the current process and won't be skipped.
To guarantee all deletable files are eventually processed, JuiceFS provides a background task named cleanupDeletedFiles that runs hourly. This task scans for files still marked as delfile and adds them into the deletion queue in batches, ensuring the cleanup pipeline keeps moving.
Once a file enters the deletion queue, the system scans all its associated chunks. For each chunk, it decrements the reference count for every contained slice and then cleans up the chunk metadata. Slices whose reference count drops to zero are marked as pending cleanup, entering the slice cleanup stage.
Slice cleanup and space reclamation
In the previous stage, the reference counts for all slices associated with the deleted file were updated. Now, the system checks the current reference count for these slices:
- If it's still greater than 0, the slice is still being used by another file and won’t be cleaned up.
- If the reference count has reached 0, it means the slice is completely obsolete, and the system adds it to the slice deletion queue for the final cleanup step.
A scheduled background task, cleanupSlices, periodically scans this queue and performs batch deletion. Users can also trigger a manual GC to actively remove these invalid slices. Slices entering this workflow are precisely located down to their physical blocks in the object storage. The actual delete operations are performed, finally freeing up the storage space.
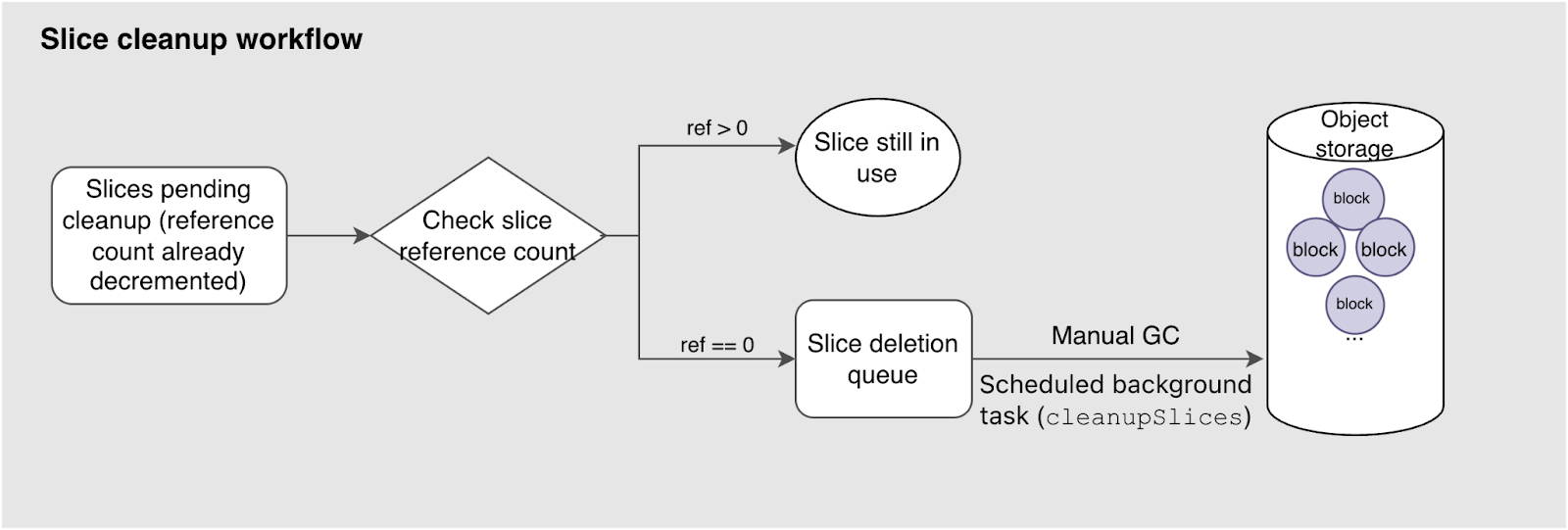
It's important to note that the slice deletion queue itself is also subject to concurrency and capacity limits. You can use the --max-deletes parameter to adjust the number of concurrent threads. This controls how many delete operations happen simultaneously and thus balances resource usage and cleanup speed.
Compaction
The previous sections covered the complete file deletion and reclamation process. However, JuiceFS deals with another type of "hidden garbage" – redundant or useless file fragments. Because files are stored in fixed-size chunks, and each chunk contains multiple slices, frequently overwriting or performing random writes to the same file can leave the slices within certain chunks scattered and non-contiguous. This is known as fragmentation.
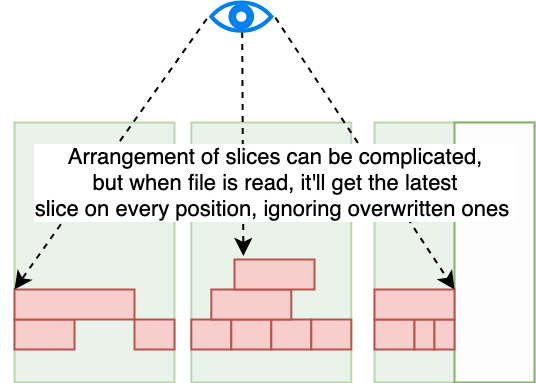
While fragmentation doesn't prevent files from being read correctly, it has bad effects on several performance and resources:
- Read amplification: Reading a single chunk might require putting many dispersed slices together. This increases I/O operation complexity.
- Increased resource usage: More fragments mean more metadata and potentially more object storage space is consumed. This strains the system and reduces overall performance.
To combat fragmentation, JuiceFS provides a compaction feature. It identifies and merges redundant or scattered slices within chunks, reconstructing them into larger, more contiguous data blocks. This significantly reduces the number of fragments and improves storage efficiency. JuiceFS supports two triggering mechanisms:
-
Automatic triggering: During file read/write operations, the system monitors the number of slices in each chunk. When the slice count for a chunk reaches a predefined threshold, the system automatically starts an asynchronous compaction task. This process involves:
1. Applying for a new slice ID at the metadata layer to build the new, contiguous data. 2. Reading the data from the old, scattered slices from object storage and writing it into the new, contiguous block. 3. Decrementing the reference count for the old slices. If the trash feature is enabled, these old slices are marked for delayed processing, handed over to background tasks for reference count updates and eventual cleanup. -
Manual triggering: Users can use the
juicefs compactcommand to proactively scan specified paths and perform concurrent defragmentation. The--threadsparameter controls the number of concurrent threads, allowing you to adjust based on system load to balance performance and resource usage. Check the command document for detailed usage.
# Compact one or multiple paths; concurrency can be specified.
juicefs compact /mnt/jfs/pathA /mnt/jfs/pathB --threads 16
# Shorthand
juicefs compact /mnt/jfs/path --p 16
To help users monitor the status of compaction handling, JuiceFS provides metrics viewable via the juicefs status command. For details, see the next section.
GC tools principles and usage
The GC tool
The GC tool in JuiceFS is an auxiliary utility for manual cleanup, supporting modes like check-only (dry-run) and scan-and-clean. Its core principle involves scanning and comparing metadata with the actual contents of the object storage. It identifies and processes objects that are no longer referenced or managed by the metadata, ensuring data consistency and reclaiming underlying space occupied by invalid data.
In certain corner cases or due to operational errors, data segments might exist in the object storage that are detached from JuiceFS' metadata management and create what's known as "object storage leaks." While rare, the GC tool can scan for and remove these. Beyond that, GC can also clean up invalid records within the metadata, such as files or slice information that wasn't fully removed during the standard cleanup process, and can accelerate various stages of the GC process, like manual compaction or manual cleanup of delfile files.
When running, the GC command displays a progress bar. It allows you to monitor the task's status in real time. The status items shown in the progress bar correspond directly to the concepts illustrated in the earlier figures, helping you better understand the GC workflow.
Some users have expressed confusion about the meaning of these status items, especially in contexts like resource billing. Correlating the figures with these status messages can greatly enhance comprehension of the entire GC mechanism's operation.
GC metrics:
- Pending deleted files/data: Number of files / amount of data awaiting deletion.
- Cleaned pending files/data: Number of files / amount of data deleted by this GC run.
- Listed slices: Total number of slices in the file system.
- Trash slices: Slices within the trash.
- Cleaned trash slices/data: Number of trash slices / amount of data cleaned by this GC run.
- Scanned objects: Total objects in object storage.
- Valid objects/data: Valid objects / amount of data in object storage.
- Compacted objects/data: Objects / amount of data after being processed by compaction.
- Leaked objects/data: Leaked objects / amount of data.
- Skipped objects/data: Objects / amount of data skipped during this GC run.
Status metrics
juicefs status displays various status information. Metrics relevant to GC are listed below. These metrics correspond to different stages of the cleanup process and serve as crucial evidence for judging the system's cleanup progress and task status. If you notice certain fragments continuously increasing, or the background processing can't keep up, consider using manual cleanup methods to accelerate the process to prevent system performance degradation.
- Trash files: Files in the trash.
- Pending deleted files: Files marked for deletion.
- To be sliced: Fragmentation tasks pending compaction.
- Trash slices: Hidden slices in the trash (resulting from compaction), potentially usable for recovery.
- Pending deleted slices: Slices with zero reference count, waiting for cleanup.
Operational suggestions
Finally, here are some fundamental yet practical operational suggestions to help manage JuiceFS system resources more efficiently and reduce operational risks in daily use:
- Set an appropriate trash retention period based on your specific application needs, balancing data recoverability against storage cost. For systems with frequent file turnover or high storage cost sensitivity, consider shortening the retention period to minimize space waste.
- It's recommended that operators periodically use tools like
juicefs statusto monitor key cleanup metrics, such as pending deleted files, delayed slice count, and trash space usage. This helps identify potential cleanup lag or resource buildup early. - If automatic background tasks are disabled for your system, schedule regular execution of GC or related cleanup commands to remove invalid residues from metadata and object storage. This prevents long-term performance issues and resource waste.
- Schedule all cleanup tasks to run during off-peak application hours whenever possible to minimize interference with normal read/write operations and ensure overall system stability. By adopting this approach, users can establish a more predictable rhythm for managing the deletion and reclamation lifecycle, achieving ongoing optimization of resource utilization efficiency.
If you have any questions for this article, feel free to join JuiceFS discussions on GitHub and community on Slack.