















BentoML is an open-source development framework and deployment tool for large language model (LLM) AI applications, dedicated to providing developers with the simplest way to build LLM AI applications. Our open-source product has supported the mission-critical AI applications of thousands of enterprises and organizations worldwide.
When we deployed models in a serverless environment, one of the main challenges was slow cold start, especially when deploying LLMs. Due to their large size, these models had long startup and initialization times. In addition, the limited bandwidth of the image registry exacerbated the problem of slow cold starts for large container images. To address this issue, we adopted JuiceFS, an open-source distributed file system.
JuiceFS' POSIX compatibility and data chunking enable us to read data on demand, achieving read performance close to the upper limit of S3. Thus it solved the problem of slow cold starts for large models in a serverless environment. With JuiceFS, our model loading time was reduced from 20+ minutes to just a few minutes.
In this post, we’ll deep dive into our application challenges, why we chose JuiceFS, and how we solved some issues when integrating with JuiceFS.
Introduction to BentoML and Bento's architecture
BentoML is a highly integrated development framework that supports development in a simple and easy-to-use manner. It allows developers to quickly develop LLM AI applications that efficiently use hardware resources with very low learning costs. BentoML also supports models trained by multiple frameworks, including common (machine learning) ML frameworks such as PyTorch and TensorFlow.
Initially, BentoML primarily served traditional AI models, but with the rise of LLMs like GPT, BentoML is also capable of serving LLMs.
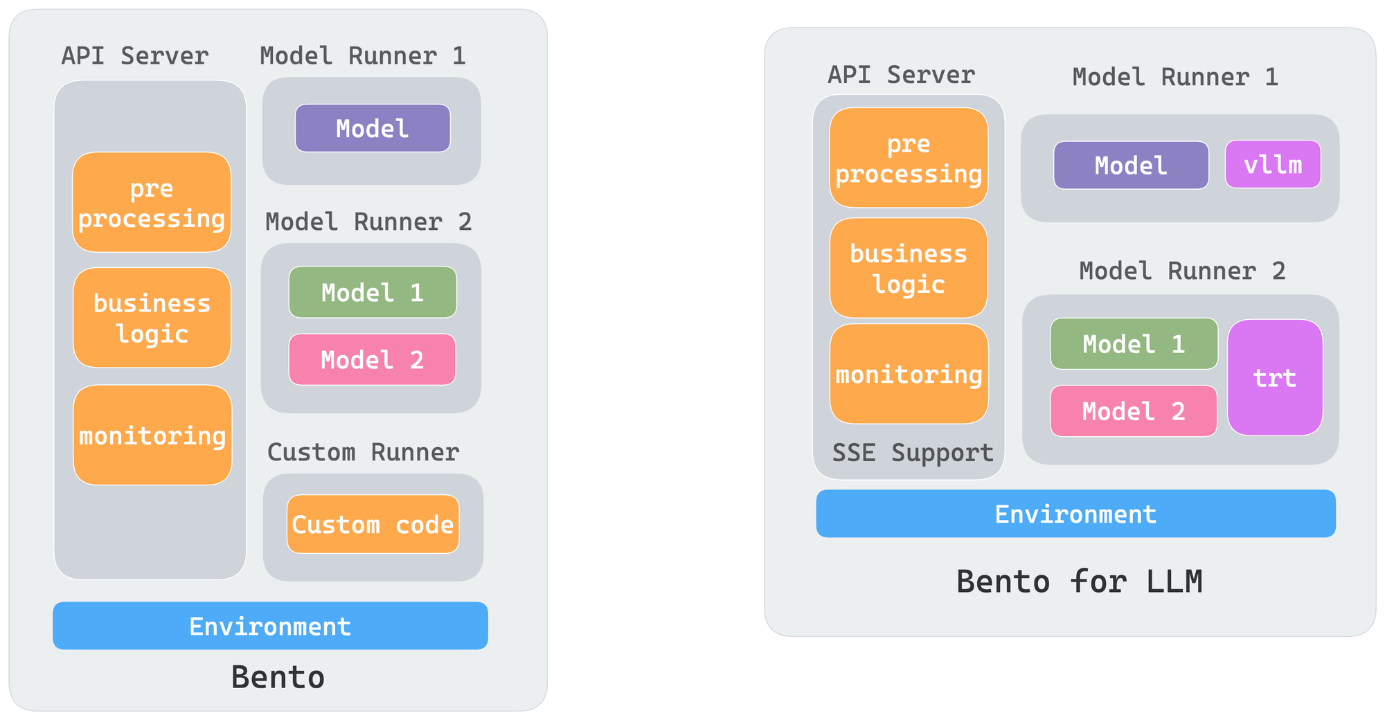
The product generated by BentoML is called the Bento, which plays a role similar to a container image and is the basic unit for deploying AI applications. A Bento can be easily deployed in different environments such as Docker, EC2, AWS Lambda, AWS SageMaker, Kafka, Spark, and Kubernetes.
- A Bento contains application code, model files, and static files. We abstract the concepts of API Server and Runner: The API Server is the entry point for traffic, handling I/O-intensive tasks.
- The Runner performs model inference work, handling GPU/CPU-intensive tasks, allowing tasks with different hardware resource requirements in an AI application to be easily decoupled.
BentoCloud is a platform that allows Bentos to be deployed in the cloud.

As the figure above shows, development tasks are generally divided into three stages:
-
Stage 1: Development stage When using BentoML for AI app development, Bentos are created. At this stage, BentoCloud’s role is the Bento registry.
-
Stage 2: Integration stage To deploy Bentos to the cloud environment, an OCI image (container image) is required. At this stage, the
yatai-image-buildercomponent builds the Bento into OCI images for subsequent applications. -
Stage 3: Deployment stage, the focus of this article One of the key components here is
yatai-serverless. At this stage,yatai-serverlessdeploys OCI images built in the previous stage to the cloud.
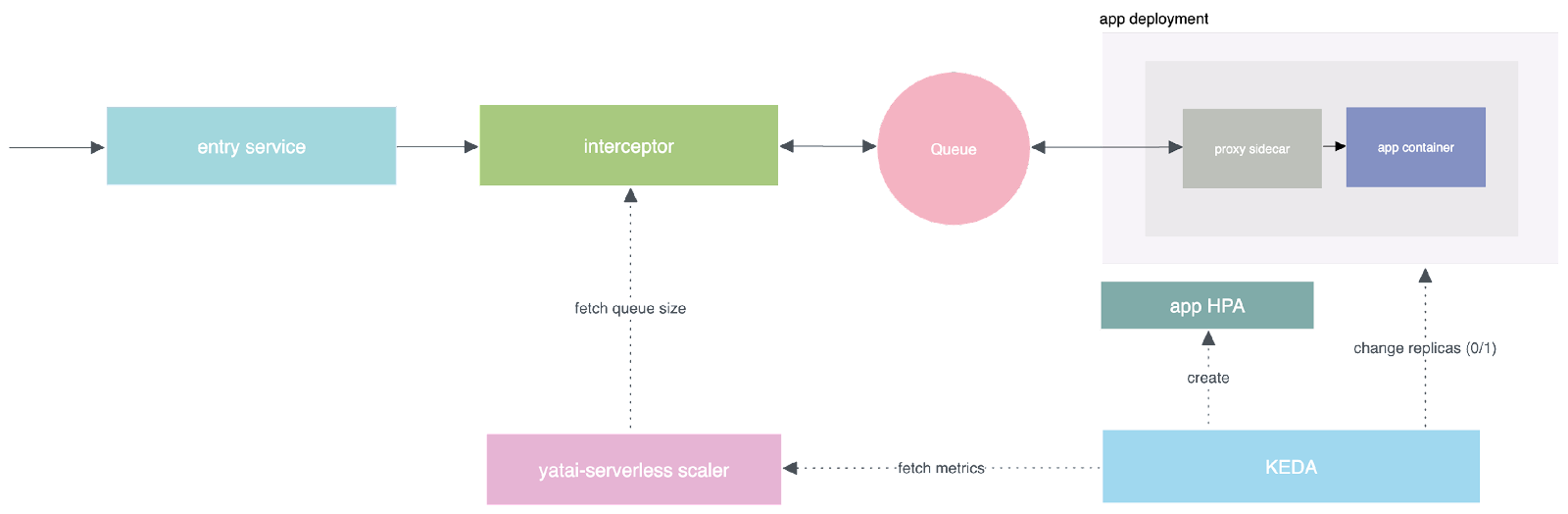
Challenges of deploying LLMs on serverless platforms
Challenge 1: Slow cold starts
For serverless platforms, cold start time is crucial. Adding replicas from scratch when a request arrives may take more than 5 minutes. During this time, some HTTP infrastructure may time out, affecting user experience. Especially for LLMs, their model files are usually large, ranging from tens to dozens of gigabytes in size. This significantly prolongs cold start times due to the time-consuming process of pulling and downloading models during startup.
Challenge 2: Data inconsistency
This is a unique problem in serverless platforms. Our platform solved this problem by modeling Bentos.
Challenge 3: Data security issue
This is one of the main reasons for deploying Bentos to the cloud and one of the core values BentoML provides to users. It’s well known that OpenAI and some other LLMs provide HTTP APIs for users to use. However, because many enterprises or application scenarios have extremely high requirements for data security, they cannot pass sensitive data to third-party platform APIs for processing. They want to deploy LLMs to their own cloud platforms to ensure data security.
Why use JuiceFS?
The figure below shows the architecture we initially adopted, which is to package all model files, including Python code, Python dependencies, and extensions, into a container image, and then run it on Kubernetes.
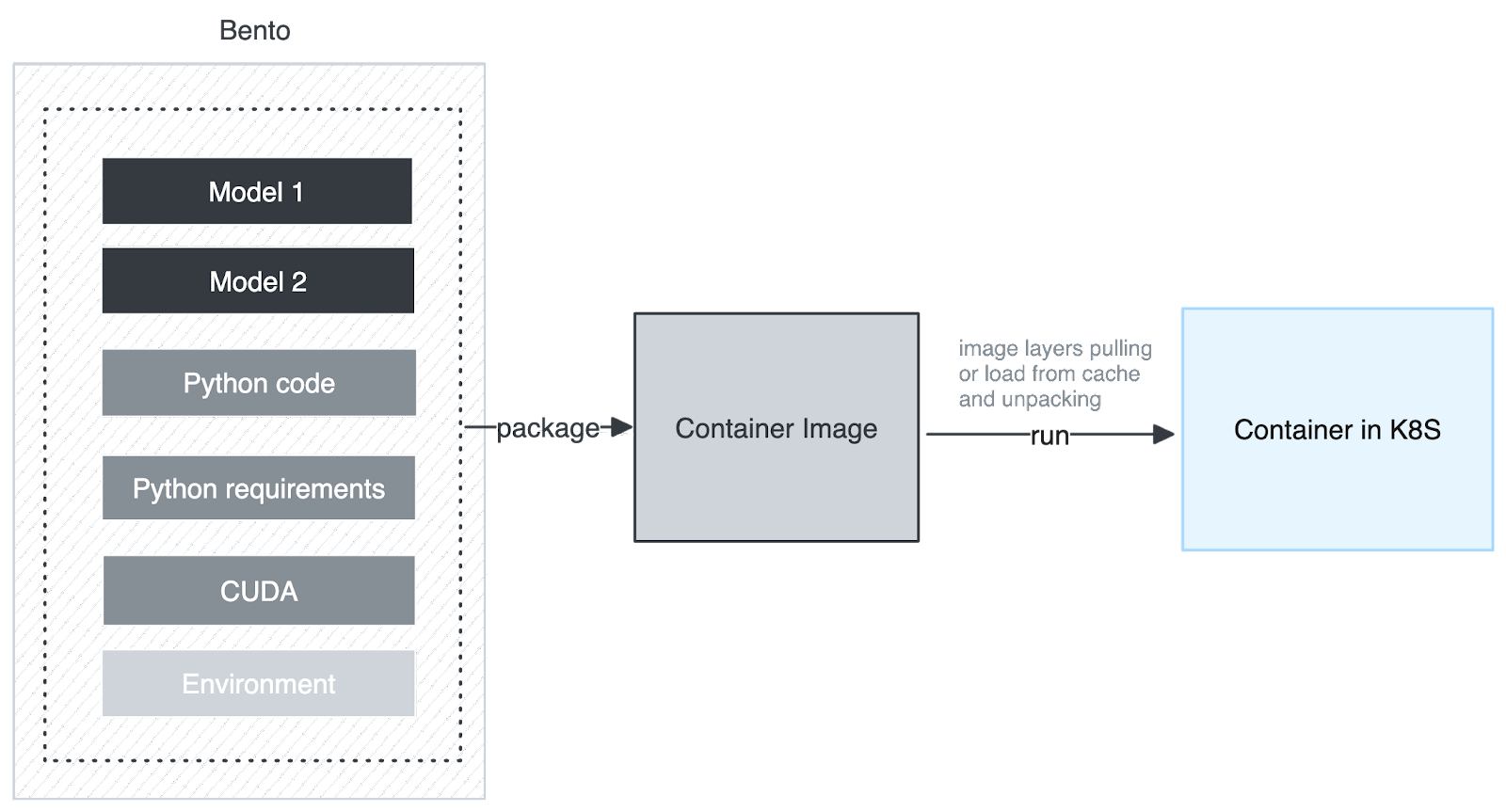
However, this process faced the following challenges:
- A container image consisted of a series of layers, so the smallest download and cache unit of a container image was a layer. Although the layers of the container image were downloaded in parallel when downloading the container image, the layers were unpacked serially. When unpacking to the layer where the model was located, the speed slowed down, and a large amount of CPU time was also consumed.
- When different Bentos used the same model, this architecture wasted multiple pieces of the same space, which were packaged into different images and existed as different layers. This resulted in multiple downloads and unpackings, which was a huge waste of resources. Therefore, this architecture could not share models.
To solve these problems, we chose JuiceFS, because it has the following three advantages:
- It adopts the POSIX protocol, which allows us to read data without adding an additional layer of abstraction.
- It can achieve high throughput, close to the bandwidth of the entire S3 or Google Cloud Storage (GCS).
- It can achieve good model sharing. When we store the model in JuiceFS, different instances can share the same LLM.
How we use JuiceFS
The figure below shows the architecture after we integrated JuiceFS:
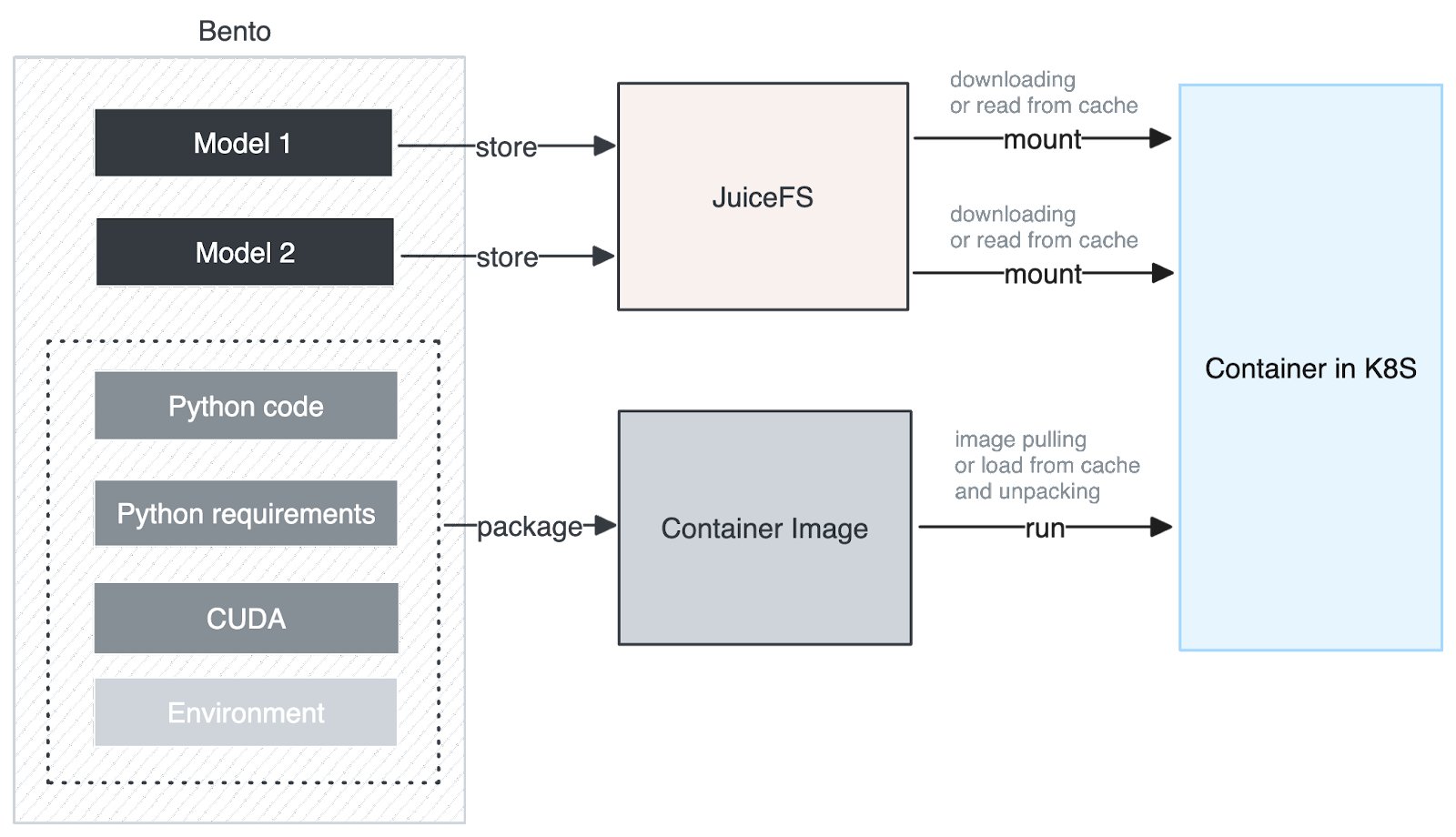
When building a container image, we extract and store the models separately in JuiceFS. The container image only contains the user's Python application code and the dependencies and basic environment required for Python runtime. The benefit of this design is that the model and operation can be downloaded simultaneously, without unpacking the model locally. The unpacking process becomes very fast, and the amount of downloaded data is greatly reduced, significantly improving download performance.
In addition, we further optimized the granularity of downloads and caching. Each model has its own cache granularity, and JuiceFS also splits large files into a series of chunks, downloads, and caches them on a chunk-by-chunk basis. We can use this feature to achieve a stream loading effect similar to large models.
We also fully use Google Kubernetes Engine (GKE)'s image streaming technology. By simultaneously performing model streaming and image streaming data fetching, we have successfully reduced startup times and improved overall performance.
Issues and solutions
Seamless integration
When introducing JuiceFS as a new component, we must seamlessly integrate it with existing components. This is a common challenge encountered when introducing new components to any mature platform. To better integrate with JuiceFS, we adopted AWS MemoryDB to replace our self-managed Redis, thereby reducing the complexity of the architecture.
Impact of introducing a new component on app logic
Introducing JuiceFS may lead to changes in application logic. Previously, the Bento container image contained the complete model, but now the Bento container image no longer carries the model. In the deployment of the yatai-serverless platform, we must ensure that these two different images are compatible with each other in terms of application logic at the code level. To achieve this, we use different labels to distinguish different versions of Bentos, and then ensure forward compatibility in the code logic.
JuiceFS download speed issue
During testing JuiceFS, the speed of downloading models using JuiceFS was very slow, even slower than downloading directly from the image. With assistance from the JuiceFS team, we found that our boot disk was a network disk, so we had been using a network disk as the cache disk for JuiceFS. This led to a strange phenomenon: the speed was faster when the cache was missed, but once the cache was hit, it became slower.
To address this issue, we added a local NVME SSD to our GKE environment and used this SSD as the cache disk for JuiceFS.
What’s next
In the future, we’ll delve into more observability work to ensure that the entire architecture remains in good working order and obtain sufficient metrics for better optimization of configurations to minimize the recurrence of similar issues.
We hope to make efficient use of JuiceFS' built-in caching capabilities. For example, by pre-planting models into JuiceFS, it means that in the application cluster, the model cache can be warmed up in the nodes in advance. This will further improve the performance of caching and cold start times.
We hope this post is helpful to you, and if you have any further questions, feel free to join JuiceFS discussions on GitHub and their community on Slack.