















Beike (NYSE: BEKE) is the leading integrated online and offline platform for housing transactions and services in China. We are a pioneer in building infrastructure and standards to reinvent how service providers and housing customers efficiently navigate and complete housing transactions.
The computing resources, especially GPUs, of Beike's machine learning platform primarily relied on public cloud services and were distributed across different regions. To enable storage to flexibly follow computing resources, the storage system must be highly flexible, supporting cross-region data access and migration while ensuring continuity and efficiency of computing tasks. In addition, as data volumes grew, the pressure on metadata management was also increasing.
Last year, our machine learning platform team restructured our storage system and chose a solution based on JuiceFS, a cloud-native distributed file system. Currently, JuiceFS serves as the underlying storage for the entire machine learning platform. It improved our adaptability to hybrid multi-cloud architectures and significantly enhanced data processing efficiency.
The storage platform now supports multiple scenarios. For example, the model loading time has been reduced from 10+ minutes to less than 30 seconds, marking a 20-fold speed improvement. In addition, we’ve developed multi-AZ (availability zone) distributed caching and mirroring features based on JuiceFS.
In this article, we’ll deep dive into our AI infrastructure evolution, the reasons for choosing JuiceFS, our underlying storage design based on JuiceFS, applying JuiceFS in our AI model repository, and our future plans.
Evolution of our AI infrastructure
The evolution of Beike's AI infrastructure has progressed from standalone to multi-server multi-GPU, then to platform-based, and ultimately to hybrid-cloud.
In the early days, our machine learning required only a single GPU machine with a local hard drive for optimization. However, as the demand for engineering automation increased and the scale expanded, this bare metal approach could no longer support efficient computing scheduling. Consequently, architectures emerged that catered to single data center or single cluster setups to meet the needs of automation. During this phase, we introduced Kubernetes clusters and network attached storage (NAS) shared storage to handle training tasks by mounting them onto machines.
With the emergence of foundation models, the scale of models increased dramatically, leading to a rise in computing demands. Obtaining computing resources was challenging and public cloud became the primary source of computing power. When coordinating GPU resources on public cloud platforms, users may face geographical restrictions. This made companies, including Beike, to adjust AI infrastructure architecture.
Currently, our team manages two platforms: the hybrid cloud KCS container service and the AIStudio machine learning platform. Both are built on large hybrid cloud platforms using container technology. The container platform relies on self-built IDCs, covering multiple data centers and integrating various public cloud services across regions.
The evolution of Beike's infrastructure has progressed from bare metal delivery to single Kubernetes cluster delivery, and then to multi-cluster, multi-data center delivery, ultimately achieving a federal delivery model that enables cross-regional resource management.
During our platform evolution, the infrastructure layer has undergone the following changes:
Decoupled compute and storage: In practical scenarios, when data was located in City A but training tasks were in City B, mounting the data volume from City A would result in inefficiency due to network latency. Thus, shortening the distance between compute and storage to improve data access efficiency was a key aspect of optimizing infrastructure architecture.
Storage following compute: Given the tight computing resources, we must consider how to make storage closer to computing power. As obtaining GPU resources became more challenging, the traditional strategy of "compute following storage" may need to shift to "storage following compute." This required us to flexibly configure storage resources based on the actual geographical location of computing tasks to ensure efficient coordination between the two. Cross-region data management challenges: Our storage and compute had a long distance. To shorten this distance, the most straightforward but inefficient method was data copying. This meant transferring data from one location to another. When spanning significant distances, efficiency issues were particularly obvious. For example, a recent data migration involving 20 TB took 11 days, primarily due to handling numerous small files. This level of efficiency was unacceptable for current high-efficiency data processing needs, particularly in AI training.
Separation of storage and compute: Given the upper limit of single-disk storage capacity, we needed to adopt an architecture that separated storage from compute to ensure sufficient overall storage capacity. This architecture not only meets growing storage capacity needs but also enhances system flexibility and scalability.
Evolution of file system architecture: The development of file systems became a critical challenge, evolving from traditional local disks to shared storage systems like network file systems, and now to the open-source multi-node file system Beike adopted. These changes have driven innovations in data storage methods while introducing new issues.
Why we chose CubeFS and JuiceFS
Considering the development trends of infrastructure and the specific needs within Beike, we needed to ensure that the storage layer could meet the following challenges:
-
Support for multi-region hybrid-cloud architectures: The storage solution must support multi-region hybrid-cloud architectures to meet the data storage needs of different regions.
-
Storage capacity for tens to hundreds of billions of small files: Currently, our file system data volume has reached 14 PB, with nearly 5 billion files. With the rapid development of AI, a large amount of historical data was cleaned and converted into trainable and structured data. Our weekly data growth rate accounted for one-tenth of the total number of files. This meant nearly 500 million new small files were added weekly. This trend was expected to continue throughout the year, posing a severe challenge to our storage system. Therefore, our system must support the storage of tens to hundreds of billions of small files.
-
Storage performance: Facing the demand for widely distributed file storage, especially in AI applications with extremely high performance requirements, enhancing storage system performance to meet the growing data storage and access needs was a pressing issue.
-
Cost-effectiveness and low maintenance: We aimed to reduce costs and maintenance requirements, minimizing reliance on third-party components. We hoped to improve performance while keeping costs within an acceptable range.
Given Beike's specific scenarios, we conducted in-depth research on CubeFS and JuiceFS and applied them to different scenarios. Model training scenarios have very high requirements for I/O throughput and IOPS. Within IDC, we primarily use CubeFS all-flash storage clusters to build file systems. Currently, CubeFS has a certain application scale within Beike.
For complex data processing scenarios that span data centers, regions, or geographical areas, we chose JuiceFS. For example, during model training, we typically process raw data, perform data cleaning tasks, and then generate intermediate or training data. In addition, this data needs to be migrated between multiple locations. Our flexible architecture based on JuiceFS designed a file system that supports cross-region hybrid-cloud architectures to meet the rapid development of our AI infrastructure.
JuiceFS uses public-cloud object storage, offering low cost and virtually unlimited storage capacity. This maximized the advantages of cloud storage. Its performance mainly relies on object storage and metadata engines. The choice of metadata engine can meet various scenarios, particularly in handling large numbers of small files. JuiceFS successfully addressed the issues we encountered in non-single data center model training scenarios, such as data set cleaning, synchronization, and capacity limitations. It effectively fills the gap in our ecosystem for a cross-data center, highly scalable file system.
Underlying storage design based on JuiceFS
Metadata engine architecture design
JuiceFS uses a metadata and data separation architecture. We considered three options for the metadata engine:
-
Redis is well-known for its high performance. However, due to our zero-tolerance against data loss, especially in contexts involving large volumes of training data, we quickly ruled out Redis. Moreover, considering the challenges of supporting large amounts of files and implementing cross-DC synchronization, the scalability of Redis clusters and limitations of its synchronization capabilities were major reasons for us to abandon it.
-
TiKV and OceanBase were evaluated for their synchronization capabilities.
- We considered developing a proprietary metadata engine.
Ultimately, we opted for TiKV and OceanBase for several compelling reasons:
-
Stability: Stability is crucial for our current state at Beike. Both TiKV and OceanBase have mature operational systems in the open-source community. Especially in achieving cross-region data synchronization, they provide mature solutions. In contrast, completely independent development would not only have a long development cycle but might also hinder rapid project deployment, especially given the rapid developments in the AI field.
-
Performance: We conducted performance tests on these two metadata engines. The results showed that there was little difference in performance between them.
- Other factors: In many scenarios, I/O performance limitations are a common issue. Metadata may be just one part of the reason, with other factors like dedicated bandwidth and object storage also influencing performance. Taking these factors into account, we ultimately chose OceanBase as our final metadata engine.
After careful consideration, we chose an economical and efficient strategy: using Tencent Cloud as the primary public cloud provider and using its internal network synchronization capability to achieve data synchronization between cities. We utilized Tencent Cloud's MySQL service and its internal network synchronization mechanism to effectively address cross-region synchronization latency and achieve a write performance of approximately 20,000 entries per second, with latency maintained at the second level.
In our metadata engine architecture, write operations first occur in our primary data center. Subsequently, the system distributes data to various data centers, ensuring the consistency and real-time nature of metadata. This strategy effectively enhanced the efficiency of data processing and distribution, providing stable and reliable support for our application.
Multi-AZ distributed cache acceleration
When we used JuiceFS, our main task was to synchronize metadata and actual data in object storage. While JuiceFS Enterprise Edition offered a distributed cache solution, we used the community edition, which had limitations in cross-region synchronization and data acceleration. Therefore, to meet the fast data synchronization requirements between cities, we developed a proprietary distributed cache acceleration system.
This system is essentially an object storage proxy system, with a custom protocol layer and a persistence layer fully reliant on object storage services provided by cloud service providers. By building a series of caching acceleration capabilities, we achieved performance comparable to accessing cloud object storage services with local NVMe-based object storage services like MinIO. This system also supports multi-write replication. When data is written to a city, it can simultaneously be written to other cities. Combined with JuiceFS' standalone cache acceleration feature, this further enhances data access speed.
Architecture design
This distributed cache acceleration system adopts a design similar to JuiceFS S3 Gateway. It established an S3 gateway for data distribution and synchronization replication tasks. While data synchronization is not real time, for large file synchronization, the delay is typically controlled within minutes.
However, thanks to JuiceFS' file chunk feature and our caching strategy, we achieve near-instantaneous data synchronization. Once data is written to a city, it can almost immediately be synchronized to other cities. Our distributed system includes two core components:
kos-proxyserves as an S3 protocol proxy, providing authentication, control plane functionalities, similar to stateless services like MinIO Gateway.kos-cachestores and distributes object storage files sent out, with its cache dimension based on bucket + file objects. When objects are too large, the system automatically splits them into multiple file blocks for storage. For example, in a Kubernetes cluster, we can deploykos-cacheon each node to ensure that object storage data is distributed across multiple cache nodes in the current data center, ensuring the fastest access speed. In the best case, we can even directly retrieve the required data from local cache, greatly improving access efficiency and response speed.
Performance improvement
Regarding storage performance improvement, due to current hardware limitations, we mainly optimize data synchronization mechanisms to enhance storage efficiency and ensure faster cross-region data synchronization.
Although our distributed cache acceleration tests can serve as references, they lack representativeness in actual cross-region deployments. This limitation arises because the testing environment is restricted to IDC internals, without covering actual cross-region deployment scenarios. Significant bandwidth differences across regions often lead to bandwidth drops ranging from tens to hundreds of megabits. Therefore, current test results are irrelevant for cross-region deployments.
However, in Tencent Cloud's cross-cloud access tests, our distributed cache acceleration solution achieved about a 25% performance improvement compared to local IDC access performance.
While this improvement is significant, the system still has bottlenecks. Especially in handling large numbers of small files, performance degradation is particularly severe. The root cause lies in our system currently not integrating metadata systems but relying on local disks for metadata storage. In addition, due to widespread adoption of the S3 protocol within the company, many components reliant on the S3 protocol are based on this distributed cache acceleration system. In practical applications, we've successfully enhanced query performance through this system. For example, previously querying 14 days of data would hit a performance bottleneck; now we can easily query data for 30 or even 60 days.
In summary, while our distributed cache acceleration system performs well within local IDCs, further optimization is needed for cross-region deployments. We're exploring integrated solutions for metadata systems to further enhance system performance and meet various application scenario requirements.
Mirror file system
When performing cross-region data replication, users first create a dataset (JuiceFS volume) in City A. This dataset essentially acts as a JuiceFS volume that can be mounted in this city, with automatic initialization at the underlying layer. Next, users need to create a mirror file system in City B and ensure its association with the volume in City A. Our system automatically completes all necessary configurations. It enables users to write data in City A and data is automatically synchronized to City B. In addition, the mirror file system configuration is flexible, allowing users to configure multiple mirror locations.
However, we encountered a challenge in practical applications. The mirror file system must be set to read-only mode. This setting not only applies to JuiceFS but also involves appropriate configurations for metadata and S3 permissions. Such settings ensure data security by preventing inadvertent write operations that could lead to unpredictable scenarios in the synchronization mechanism.
Therefore, we’ve decided to productize this process primarily to mitigate unpredictable factors during interactions, particularly to prevent dual-write issues arising from simultaneous writes in both locations. Through this productized solution, we aim to provide users with a more stable and reliable data synchronization service.
Currently, we’re promoting this internal file system product platform. One of its core functionalities is data synchronization between two file systems. While these functionalities operate at the technical infrastructure level, they are crucial as they enable efficient synchronization and unlock various innovative application scenarios.
The initial optimization focus of this file system platform is on the immediacy of data synchronization. It allows synchronization as data is being written. This contrasts sharply with traditional AI workflows where data production, cleansing, replication, and training steps are time-consuming. Inefficient data replication due to inadequate infrastructure capabilities, such as limited bandwidth, often slows down the entire workflow. Our file system optimizes these links, significantly reducing data replication time and accelerating data entry into the training phase.
Furthermore, leveraging the capabilities of this file system, we’ve implemented scenarios for data warming up. When dealing with large datasets and not all data requires synchronization between both ends, users can selectively warm up cleansed or targeted data. This feature facilitates rapid distribution of data from one region to another, speeding up specific tasks like training.
In summary, the development of this internal file system product platform has enhanced the overall efficiency of our infrastructure, reduced data replication times, and enabled users to efficiently accomplish various tasks.
Using JuiceFS in our AI model repository
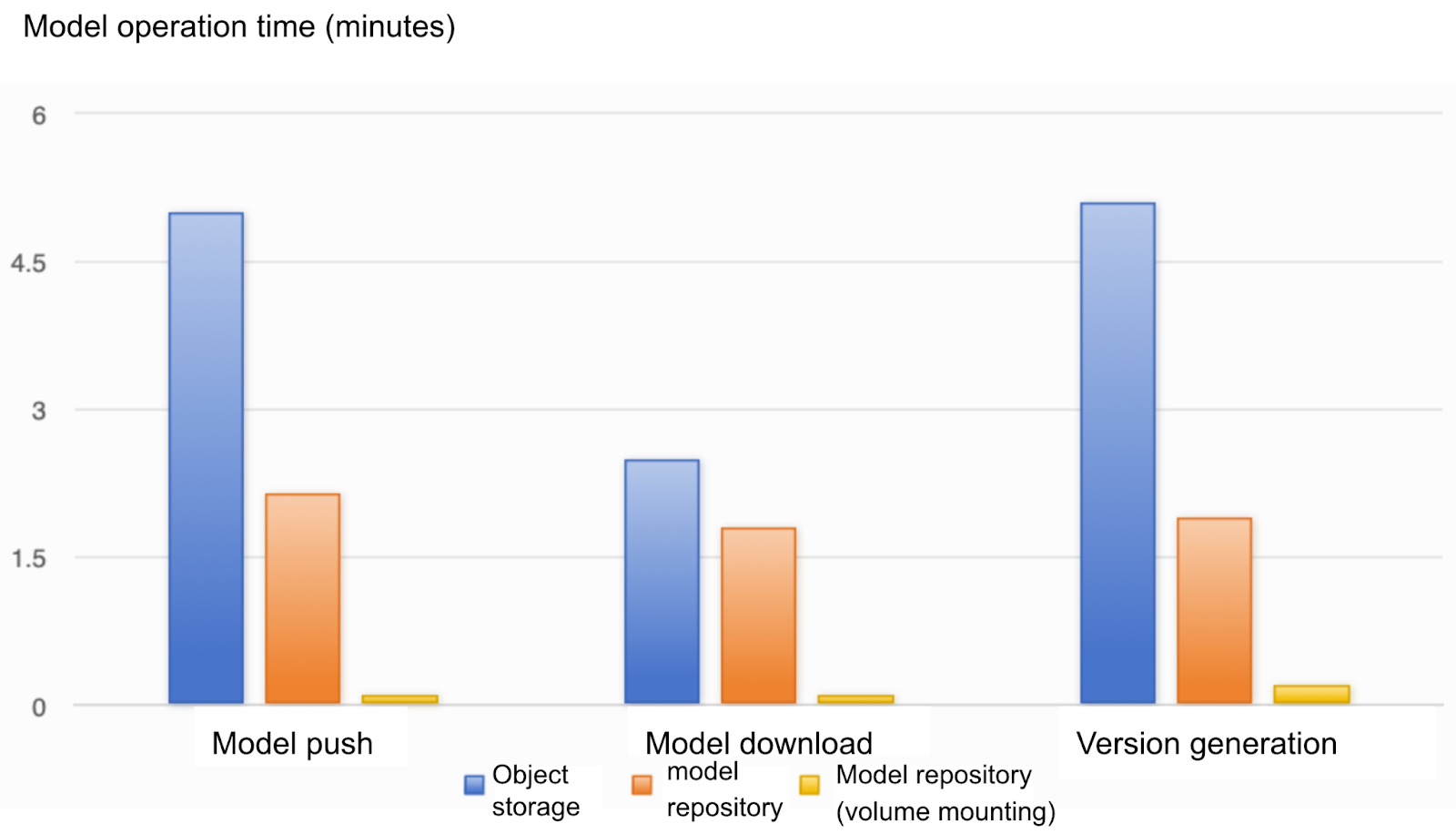
With the advent of the era of foundation models, the size of models continues to increase. The largest model we currently handle exceeds 130 GB. Here, we focus on a simple scenario: the inference phase after model training. During this phase, we need to deploy a lot of services, like a microservices architecture. It may require running over 100 replicas to handle inference tasks.
For such large models, distributing them directly to the development cluster poses significant challenges. Taking S3 as an example of a model repository, pulling such large models to multiple replicas simultaneously could strain bandwidth resources severely. It may potentially lead to S3 service crashes and affect other online operations. Therefore, the high bandwidth consumption caused by large models became a pressing issue for us.
To address this issue, we adopted three principles to optimize the model management and distribution process.
-
Striving to avoid physical replication, which means avoiding directly pulling large models from the central repository to all replicas. Instead, we considered distributing models internally within the data center to reduce reliance on external bandwidth, though this approach may bring a long distribution cycle.
-
Avoiding centralized designs. Traditional centralized storage systems face bandwidth limitations when handling large models. Therefore, we seeked more distributed solutions to lessen dependency on central storage.
-
Leveraging existing technologies for reuse within the company. Beike started early in building machine learning platforms. This enabled us to utilize mature technologies and frameworks to optimize model management and distribution. For example, we’ve successfully integrated technologies like JuiceFS into model storage and management to further enhance system efficiency and stability.
Based on JuiceFS architecture, we designed an AI model repository solution. The core ideas of this solution include several key components:
- Model deployment and management: We provide principles based on JuiceFS volumes and model service control planes. In addition, a command-line tool for model repositories like Docker allows users to deploy and manage models through this tool.
-
Model service control: We focus on authentication, metadata, and other management functionalities. The models are stored in JuiceFS volumes. Similar to mirrors requiring tags for version identification, we use JuiceFS' networking capabilities to manage model versions through metadata replication rather than actual data replication.
-
Model pulling: We offer two deployment methods:
- Mounting JuiceFS volumes into Pods in Kubernetes environments using PersistentVolumes (PVs) and PersistentVolumeClaims (PVCs) to automatically mount model files. It’s suitable for data-intensive scenarios.
- Remote pulling, where models are pulled directly onto bare metals. Here, leveraging metadata and accelerated file system technologies ensures efficient and complete downloads, just like downloading within an intranet. In addition, with caching acceleration within data centers, this method minimally impacts bandwidth compared to traditional direct pulls from object storage.
What’s next
Currently, we’re facing a pressing and pragmatic challenge: developing enterprise-level control capabilities for JuiceFS. JuiceFS demonstrates technical flexibility in use, but it also brings uncontrollable factors, especially in large-scale deployments.
To address this issue, we plan to introduce a series of rules and rate-limiting mechanisms to handle potential resource overconsumption scenarios, such as concurrent client writes to the same JuiceFS volume. This not only requires enhancing control over JuiceFS but also represents a crucial direction for our future development.
Specifically, we’ll approach this from three aspects:
- Enhancing operational efficiency: Ensuring JuiceFS' use within the company is more efficient through JuiceFS Community Edition’s smooth upgrades.
- Increasing observability: This extends beyond monitoring JuiceFS to enhance the entire system architecture's observability.
- Strengthening management features: This includes dynamically deploying rate-limiting rules and configuring dynamic adjustments.
When we addressed AI challenges, we observed a significant trend: the transformation in data production methods. Currently, large amounts of data are directly stored in various file systems such as CubeFS and JuiceFS, while upper-layer data processing solutions have not yet established unified standards. For example, the emergence of technologies like multimodal data fusion, direct data writing to file systems, and region-based exploration using vectorized data reflects this trend.
To address this transformation, we propose a visionary concept: using AI capabilities to enhance file system data processing, integrating data processing with AI seamlessly. In recent work, we’ve explicitly prioritized solving storage performance issues, particularly in integrating remote direct memory access (RDMA) technology. We aim to advance this exploration through collaborative community efforts.
If you have any questions for this article, feel free to join JuiceFS discussions on GitHub and their community on Slack.