















Founded in 2023 at Tsinghua University, Gongjiyun provides compute platforms and Model as a Service (MaaS) for artificial intelligence generated content (AIGC) enterprises and research institutions. We aim to alleviate the mismatch between elastic compute demand and supply. By aggregating idle IDC resources and edge resources, the platform offers containerized services, delivering rapidly schedulable compute for volatile workloads such as AI inference, video rendering, data processing, and data synthesis.
In cross-cloud elastic inference scenarios, compute tasks can be scheduled to different regions, cloud environments, and clusters, but model files and application data are large and cannot be migrated as quickly as compute resources. Especially in online inference, the model repository is read‑heavy and frequently accessed – storage access performance directly affects service startup, elastic scaling, and request latency.
To address this, we built an object storage acceleration solution on top of JuiceFS, integrating users’ existing object storage into elastic inference clusters. Through a unified namespace, metadata import, FUSE mount, distributed cache, and data warm-up, it improves access efficiency for model repositories across clouds and clusters. In a case study with a leading text‑to‑image model community, the solution supports a tens‑of‑TB model repository, dynamic loading of checkpoints and low-rank adaptations (LoRAs), and elastic scaling of hundreds of GPUs at peak, while keeping additional latency within the customer’s acceptance range.
In this post, we'll walk through why storage — not compute — is the real bottleneck in cross-cloud elastic inference, how we evaluated and chose JuiceFS, and the step-by-step optimizations that brought latency from +10s down to under 2s in production.
Elastic demand is widespread, but supply is hard to match
As AI applications grow rapidly, compute demand continues to increase, but resource usage patterns differ across scenarios. Compared to training, which has stable resource needs, AI inference, data processing, and data synthesis are often more volatile: office applications may see higher traffic during the day, entertainment apps during evenings or weekends, and project‑based data processing may consume large amounts of compute in short bursts then idle. For small teams or exploratory applications, elastic compute also helps them better evaluate the relationship between per‑request cost and application value.
On the supply side, compute infrastructure is capital‑intensive. Resource providers are not incapable of offering elastic services, but they prefer long‑term dedicated leases to recover costs and reduce risk. As a result, low price, stability, and elasticity are difficult to achieve together:
- Dedicated leases are low‑cost and stable but lack elasticity.
- Spot resources are cheap and elastic but uncertain.
- On‑demand resources are elastic and stable but expensive.
In China, this contradiction is further reflected by a market dominated by dedicated leases, with elastic supply accounting for a small share.
We aim to resolve this mismatch between elastic demand and supply. By aggregating idle IDC and edge resources, the platform offers containerized services, providing rapidly schedulable compute for AI inference, video rendering, data processing, and data synthesis. At lower resource costs, we help users quickly spin up tasks during peaks, schedule them across clusters, and handle elastic demand, while enabling resource providers to improve utilization and monetize idle capacity beyond dedicated leases.
Compute can be scheduled: How does storage keep up?
As elastic compute platforms evolve, compute resource scheduling is easy. Container images can be synchronized across clusters via registries and distribution networks, tasks can be launched in different resource pools by schedulers, and traffic can be distributed via unified ingress and traffic management.
But model and data files are typically large, making cross‑cloud, cross‑cluster migration costly and slow, unable to match the sub‑second startup and release of compute. Therefore, in cross‑cloud elastic inference architectures, the real limitation on system elasticity is often not compute scheduling, but the efficiency of data and model distribution.
Different application scenarios have different storage requirements:
-
Model training, development, and debugging: These involve complex read‑write needs, including code repositories, model files, experiment results, and intermediate state. They also require high environment stability; users cannot tolerate state loss from frequent host switching. Thus, the platform typically provides long‑term stable compute resources and runtime environments, and storage needs can be met by existing stable storage systems.
-
Data processing: This can be split further. If a single processing job has high application value and can cover cross‑cloud network transfer costs, you can build a pipeline that continuously pulls data from S3 or other object storage, processes it in the compute cluster, and writes back streaming. The system does not need large local storage. If the data scale is larger or per‑job value is low, local storage acts as a one‑time cache. Data flows through and does not need to be persisted.
What is truly more challenging is the online inference scenario. Online inference services cannot tolerate downtime. However, the resources used by an elastic computing platform may come from idle resource pools. These resources could be preempted. Once resources in a certain data center or cluster become unavailable, the platform must be able to migrate tasks to other providers or other clusters in time. This means not only computing tasks must be migrated. Model files and related storage access capabilities must also be migrated at the same time
Online inference has higher requirements for service continuity and cross-cluster migration capabilities, but its storage access pattern is also more clear. Compared to training, development, and debugging scenarios, inference workloads are typically read heavy. The core needs focus on efficient model loading, reading model weights, and accessing the model repository. For large models and online applications, model loading speed directly affects service startup time, elastic scaling efficiency, and request response stability. Therefore, inference scenarios are not suitable for simply adopting traditional read-write hybrid storage architectures. Instead, they are better suited for specialized optimizations around model distribution, read only access, and cache acceleration.
In addition, an elastic computing platform usually does not host a user's complete application system. The user's primary cloud account, application database, model management system, and even some fixed computing resources often already exist in other clouds or on premises. For the platform to integrate with the user's application, it must be compatible with the user's existing model repository and model management processes. It cannot require the user to fully migrate the entire system.
Therefore, to support cross-cloud elastic inference, we need more than just compute scheduling capabilities. We need a cross-cloud high-performance storage and model distribution solution tailored for model inference scenarios. This solution must support hosting a large model repository and high-performance reading, it must adapt to the user's existing model management system. And it must provide stable data access capabilities when resources are migrated across clouds and clusters.
Why JuiceFS: Unified cross-cloud access, strongly consistent metadata, and high-performance cache
Facing cross-cloud elastic inference scenarios, the storage system needs to meet several conditions at the same time:
-
It must provide a unified access point across different clouds and clusters. It must support shared read-write access and unified metadata management.
-
It must be compatible with the user's existing object storage and model repository to avoid data migration.
-
It needs low operational complexity and good read performance.
When evaluating storage options, we considered Ceph:
-
Ceph is mature. It’s suitable for building unified storage within a single data center or a stable resource domain.
-
However, in cross cloud elastic inference scenarios, Ceph requires high network stability and operational skills. The overall integration cost is higher. So we did not choose it.
We also evaluated Alluxio. However, in a multi-cloud environment, multiple clusters need to access the same underlying object storage data concurrently. The workload is not purely read only; there are also occasional writes. This scenario requires strong data consistency. Therefore, Alluxio was not chosen for production.
We finally chose JuiceFS mainly because:
-
It uses object storage as the database.
-
It provides a unified namespace and consistent file system view through an independent metadata service. This allows multiple clusters to access the same model data as a file system.
-
This architecture is suitable for cross-cloud and cross-cluster model distribution and shared reading.
-
It’s also compatible with the user's existing object storage and model repository, reducing data migration and application integration costs.
The decision to further adopt JuiceFS Enterprise Edition was mainly due to its distributed caching capabilities and managed metadata service. In this scenario, the value of JuiceFS is not just providing a file system interface. It combines object storage, unified namespace, metadata management, and cache acceleration into a storage access layer that is better suited for cross-cloud elastic inference.
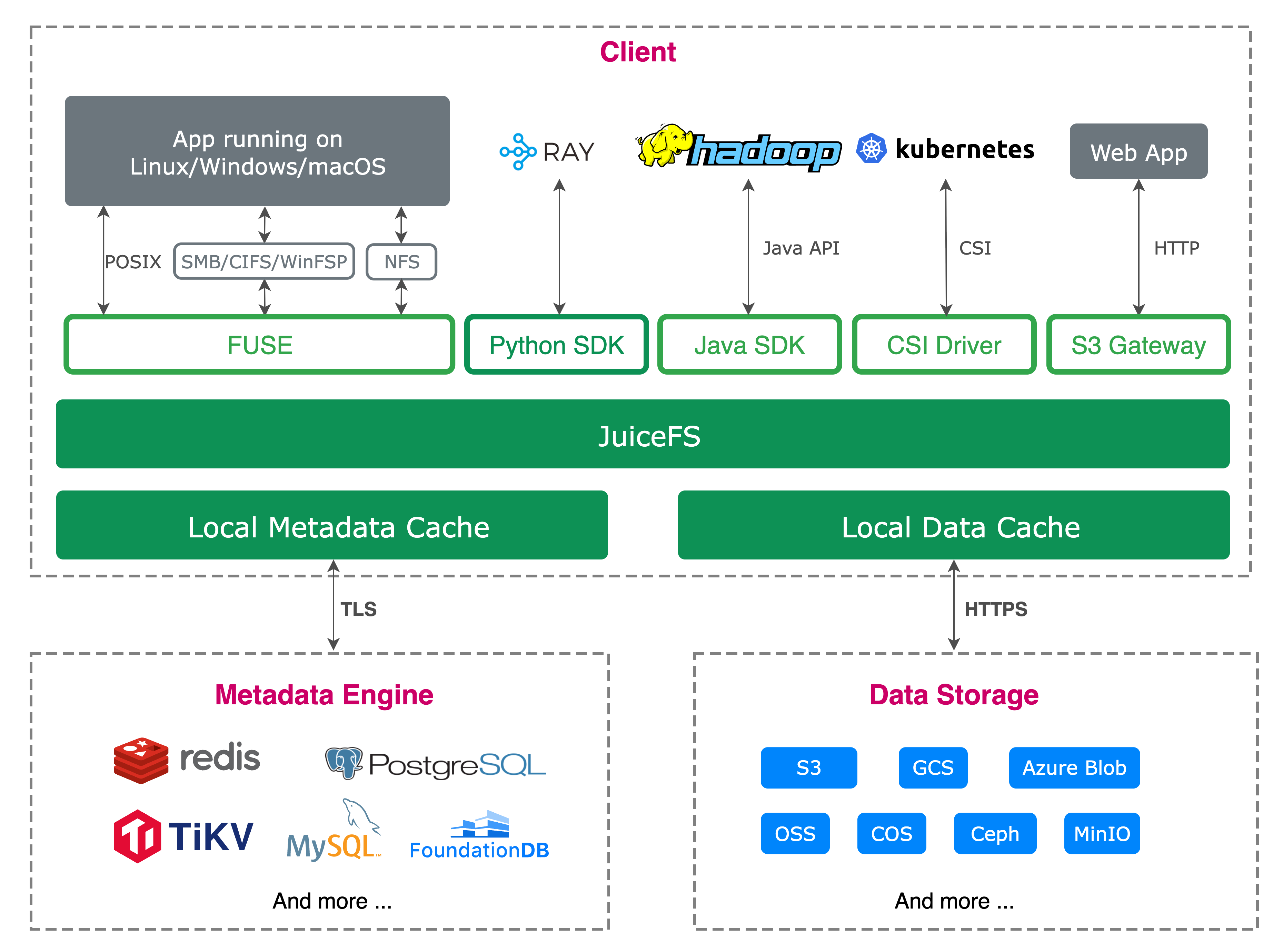
Practical: Object storage acceleration based on JuiceFS
Based on JuiceFS, the platform encapsulates an object storage acceleration product. This product connects the user's existing object storage to the elastic inference cluster. It provides the storage as a high-performance file system for the application. The overall process is as follows.
-
Create a file system. The user provides object storage access credentials, for example, AK/SK for S3-compatible storage. The credential permissions can be configured as read only or read-write based on application needs. The platform creates a corresponding JuiceFS file system based on that object storage.
-
Import metadata. The platform uses the JuiceFS import feature to scan the metadata of files in object storage. Then, it imports that metadata into the JuiceFS metadata service. In this way, the model files originally stored by the user in object storage can be accessed as file system directories in JuiceFS.
-
Create a cache group. Within each cluster that may host workloads, the platform sets up a JuiceFS cache group. This forms a distributed cache group. Before running a task, the platform can warm-up model files. It caches hot data in the target cluster in advance. This reduces the time needed to pull data from remote object storage when the inference service starts.
-
Mount to application Pods. When the user's application runs, the platform uses the FUSE client to mount the JuiceFS file system into the application Pod. For the application, model files appear as local file system paths. Therefore, the original model reading logic usually does not need modification.
-
Enable node local cache. Besides the cluster level cache group, the node where the FUSE client runs can also provide local cache. This improves repeated read and model loading performance. It further reduces direct access to remote object storage.
This object storage acceleration product essentially productizes the JuiceFS metadata import, distributed cache, data warm-up, and FUSE mounting process. It allows the user's existing object storage to serve cross-cloud inference tasks in a way that feels closer to a local file system.
In addition, the JuiceFS cache group is independent from the file system access point. This characteristic, on one hand, adds management complexity on the platform side, because the platform needs to manage the relationships among the file system, cache groups, mount points, and task scheduling. On the other hand, it provides a foundation for cache isolation, independent scheduling, and fine-grained management based on clusters, users, or application scenarios in the future.
Production case study: A leading text-to-image model community
Scenario, challenges, and acceptance criteria
One of the most representative cases in this object storage acceleration solution involves a leading Chinese text-to-image model community hosting tens of terabytes of model data, including large checkpoint base models and a larger number of smaller LoRA models. In practice, inference jobs typically load a checkpoint first, then load one or more LoRA models to perform combined inference.
The company already operated compute infrastructure at scale — several thousand GPUs — but its workload, serving creative design and production use cases, exhibited significant variability. Overall average utilization was below 50%, yet during morning and afternoon peak hours on weekdays, load could reach 140% of normal capacity, degrading the user experience. The customer therefore needed a highly elastic compute supply.
We provided a high-elasticity resource model: compute support at the scale of hundreds of GPUs was available only during weekday peak hours — 10:00–12:00 AM and 2:00–6:00 PM — with resources scaling to zero at all other times.
This meant the platform needed to provision hundreds of GPUs within a window of minutes, while consuming zero resources outside peak hours. For the customer, this model delivers large-scale compute during peak periods while avoiding payment for idle capacity. For the platform, it enables more efficient utilization and monetization of idle compute resources.
The technical challenges were significant:
-
A model repository of this scale cannot simply be replicated to every elastic cluster.
-
Inference services do not load all models once at startup. Model reads and switches happen continuously as user requests arrive, resulting in high access frequency. Therefore, the object storage acceleration solution needed to support not just large-scale model repository access, but stable read performance under continuous dynamic loading.
The customer's performance requirements were also strict. During acceptance testing, a portion of production traffic was routed to the elastic cluster. The requirement was that both the median and mean inference latency of the elastic cluster must stay within 2 seconds of the customer's own cluster. Given that individual inference jobs take on the order of tens of seconds, this requirement left virtually no room for additional latency introduced by the storage layer. In the first few rounds of testing, both median and mean inference latency on the elastic cluster exceeded the customer's own cluster by approximately 10 seconds — failing the acceptance criteria.
Performance optimization: Reducing additional latency on the elastic cluster
Optimization began with the median. A high median indicates that a significant proportion of requests are experiencing performance degradation, not just a small number of outliers inflating the tail. JuiceFS monitoring revealed that the cluster's cache hit rate was not reaching the expected level. In the current architecture, a cache miss requires a round trip over the public internet to the customer's object storage on Alibaba Cloud. This significantly increases model loading time and then affects inference request latency.
To solve this, the platform used the isolation capability of the JuiceFS cache group. It assigned dedicated cache nodes to this customer, reserved enough cache space, and warmed up the core model data. After warming up, the access path for core models achieved nearly 100% cache hit rate. This effectively avoided the performance loss from cross public network backfilling.
The second factor affecting the median was metadata access latency. Because the platform uses a unified cross-cluster architecture, the metadata service is accessed over the public internet, for example, via JuiceFS Cloud Service or a deployment on a remote host, and this latency affects overall model read performance.
The platform took two measures to address this issue:
-
Enabling JuiceFS' open cache to keep metadata in local memory as much as possible. Since this workload is predominantly read-only, caching is an effective way to reduce metadata access overhead.
-
Tuning the cluster's network rate-limiting policy. While the platform cannot directly control network equipment in edge data centers, it can apply node-level rate limiting to prevent any single node from saturating the available bandwidth, improving overall network stability. After these optimizations, cluster-wide performance improved meaningfully and the median metric gradually reached the customer's requirement.
Once the median met the target, the mean still showed a gap. This indicated that long-tail requests remained, with a small number of requests taking significantly longer than normal and pulling up the overall average. Further analysis traced this to node-level local cache — specifically, the FUSE cache quota. With limited cache capacity, the elastic cluster experienced more frequent cache evictions than the customer's own cluster, causing some requests to reload model data from scratch and increasing mean inference latency. The platform addressed this by increasing the FUSE local cache quota in the production environment, reducing eviction frequency, improving tail latency, and ultimately bringing the mean metric within acceptance. The system passed validation and has been running stably since.
Multi-tenant cache management
After the single-tenant case was validated, the solution entered multi-tenant operation. As different tenants began time-sharing the same elastic nodes, a new issue emerged: cache contention between tenants.
In the elastic resource model, FUSE clients do not actively clear node cache on exit. This is a reasonable design in single-tenant scenarios, where cached data from previous jobs can be reused by subsequent jobs to improve hit rates. However, in multi-tenant scenarios, one tenant's data can occupy node cache for extended periods. This leaves insufficient cache capacity for the next tenant, who is then forced to fall back to object storage, causing a noticeable performance drop.
To address this, we deployed an independent daemon process on each node that performs a global cache garbage collection (GC) pass before the application FUSE client starts. The eviction strategy references the JuiceFS FUSE client implementation, using a 2-random policy to balance collection efficiency and performance overhead. Coordination across nodes is handled via Kubernetes distributed locks: only the client that acquires the lock executes GC, preventing multiple clients from running cache collection simultaneously and creating excessive network and I/O pressure.
This mechanism effectively mitigates the problem of historical jobs occupying cache resources in multi-tenant scenarios, allowing different tenants sharing elastic resources to maintain consistent cache performance.
Conclusion
For elastic compute to reliably serve production traffic, compute scheduling alone is not enough. Model data and hot data must remain stably accessible across clouds and clusters.
Built on JuiceFS, we’ve combined object storage, unified namespace, metadata management, distributed caching, and FUSE mounting into an object storage acceleration solution purpose-built for elastic inference. This is not simply about mounting object storage as a file system. It’s about building a data access layer around the access patterns of model inference: one that supports warm-up, caching, isolation, and management.
This represents Gongjiyun's current progress in elastic compute and cross-cloud storage acceleration. As AI inference scenarios continue to evolve, model distribution, cache management, and multi-cluster data access will continue to surface new engineering challenges. We look forward to exchanging ideas with developers, AI application teams, and infrastructure practitioners, and to exploring more stable and efficient data access solutions for elastic compute environments.
If you have any questions for this article, feel free to join JuiceFS discussions on GitHub and community on Discord.