















Xingchen Zhengtu Technology Co., Ltd. is a startup focused on AI search and multi‑modal artificial intelligence generated content (AIGC) applications for e‑commerce. Our products include:
- Gensmo, which focuses on fashion and provides virtual try‑on, style recommendations, and product search.
- ZooClaw, which offers AI agent services for a wider range of daily and work scenarios.
In this article, we’ll share our thinking and experience in unified storage selection, architecture design, and performance tuning. We’ve been running JuiceFS in production for more than a year. It manages over 100 million files. Our application runs across Oracle Cloud, DigitalOcean, and Google Cloud Platform (GCP). JuiceFS has become the unified storage layer supporting model training, inference, data processing, and online agents.
Unified storage requirements and design approach
Four scenarios, four I/O profiles
So far, we have four main storage scenarios that support Gensmo and ZooClaw.
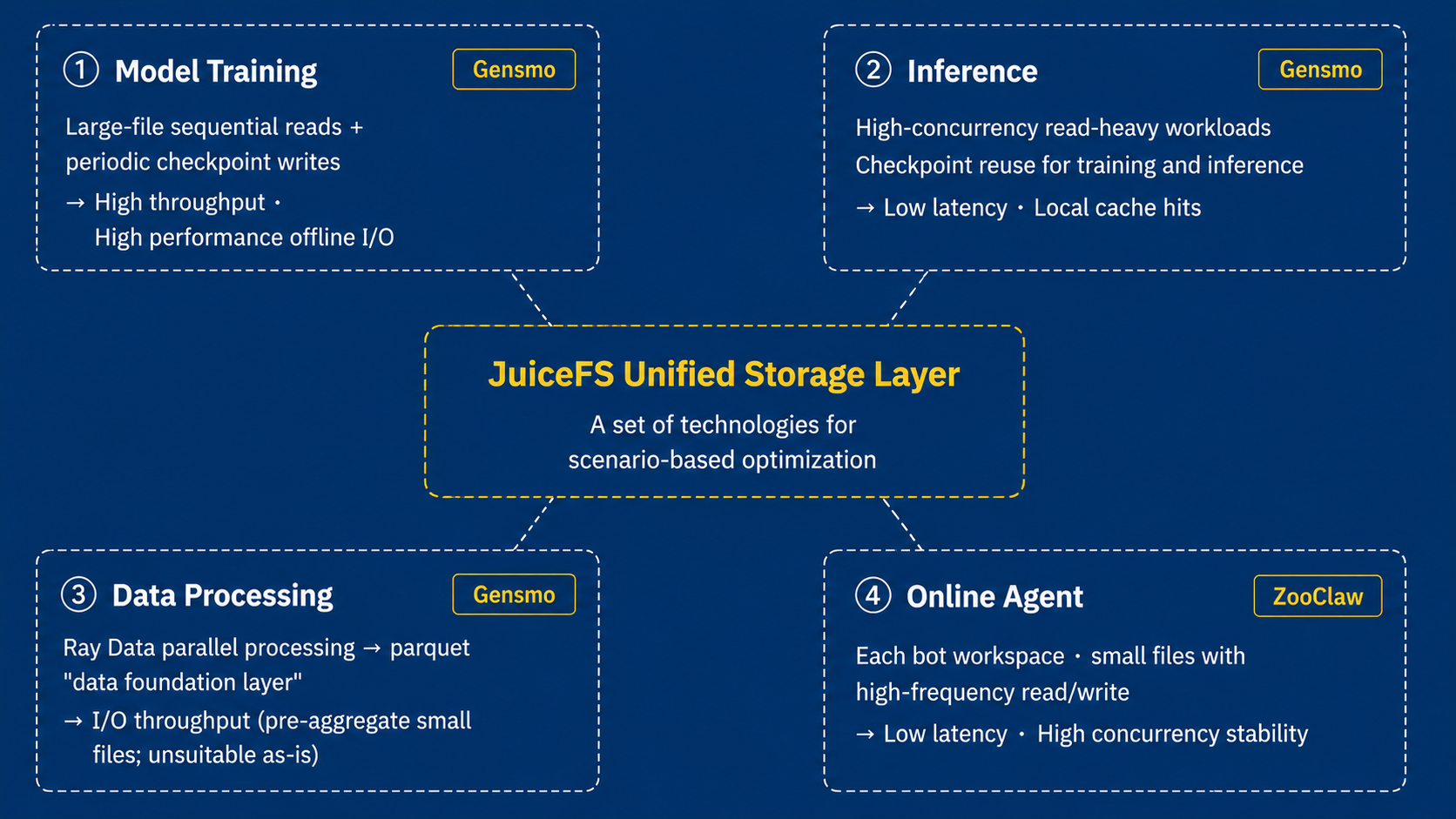
Scenario 1: Model training
We build our own models, including Gensmo's Try‑on model and video generation models. They show try‑on results, 360‑degree model actions, or special effects to B2B and B2C customers. Model training involves large‑file sequential writes and checkpoint saving. Storage requirements: high capacity and high‑performance sequential I/O.
Scenario 2: Model inference
Inference services primarily need high‑concurrency sequential reads. Data is loaded into local cache to increase hit rates.
Scenario 3: Data processing
We crawl product, clothing, and review data from overseas independent e‑commerce sites. This data is used for model training and application operations analysis. This scenario involves many small files (a few hundred kilobytes per image). High IOPS and concurrency are challenges.
To optimize data processing, we use Ray Data to process datasets in parallel and consolidate large volumes of small files into reusable Parquet datasets ranging from tens to hundreds of gigabytes. These datasets serve as a shared data foundation that can be reused across downstream workloads such as embedding generation, retrieval, recommendation, training, and inference. This greatly reduces pressure on the file system and serves both training and inference needs.
Scenario 4: Online agents
Online agents are different from the offline scenarios above. There are still many small files, but these files are generated by online services. Each agent only reads and writes its own data. No cross‑agent distributed processing is required. The storage system must support high concurrency and fast response. It does not need cross‑agent data coordination.
In summary, these four scenarios have two types of storage requirements:
- Offline training, inference, and data processing need high throughput, high concurrency, and caching.
- Online agents care more about low latency, data isolation, and stability.
After clarifying these application needs, a natural question arises: do we need a multi‑cloud architecture? From the very beginning of platform construction, our answer was yes.
Cloud neutrality is not a concept; it’s bargaining power
The goal of cloud neutrality is not technical purity. It’s to meet the core needs of the infrastructure team: keeping compute resources and workloads portable, and maintaining bargaining power with different cloud providers.
For overseas business, if compute and storage are locked into a single cloud provider for a long time, the ability to flexibly adjust compute resources becomes limited as the application grows or prices change. This is especially true in AI, where GPU resource prices and availability fluctuate greatly. A resource that is cheap today may become expensive or scarce later. The compute scale needed after application growth may also exceed what the original cloud provider can offer.
Therefore, we want to decouple the storage layer from any specific cloud vendor. Data should stay cloud‑neutral. This way, training, inference, or online agent workloads can move to a cloud that better meets cost and performance requirements. There is no need to copy or reconfigure data repeatedly.
POSIX: The foundation of a unified storage experience
Another critical question in platform construction was: how do we give our engineering team a consistent operational experience across multiple clouds and multiple object storage backends?
For a single application scenario, using object storage directly is enough. But when training, inference, data processing, and online agents share the same data system, the development and operations cost of different object storage interfaces grows quickly. Therefore, we wanted a unified abstraction on top of the underlying storage. POSIX file system semantics are the best fit for this.
With JuiceFS, we map underlying object storage (whether it’s GCS, S3, or R2) into a POSIX file system and mount it as a local path. From local development to production, the engineering team always sees the same file system interface and access path. They don't need to care about which cloud or which object storage holds the data.
In short, an ideal cloud storage experience lets engineers not feel the multi‑cloud environment at all. They always see a local path. This was a major reason we later chose JuiceFS.
Selection: From GCS Fuse and S3 Fuse to JuiceFS
Because offline and online scenarios have very different needs, our storage selection took two different paths.
Offline: Choosing JuiceFS from the start
For offline scenarios, we faced a multi‑cloud environment and high-throughput requirements. Therefore, before building the system, our team evaluated mainstream solutions and compared them against our critical needs:
- Self‑built parallel file systems: Highest performance, but high cost, hardware‑locked, limited cross‑cloud capability.
- Cloud‑managed parallel file systems: Convenient, but locks you into a single cloud, still expensive.
- Plain FUSE: Low cost, but insufficient POSIX semantics and performance.
- Cache orchestration layers: Needs underlying storage and adds operational complexity.
| Solution | Cloud-neutral | POSIX semantics | High throughput | Distributed cache | Cost/Operations |
|---|---|---|---|---|---|
| Self-built parallel file system (for example, Lustre) | ❌ Hardware-dependent | ✅ | ✅✅ | Partial | High cost, operationally intensive |
| Cloud‑managed parallel file system (for example, Filestore) | ❌ Locked to a single cloud | ✅ | ✅ | ✅ | High cost, lower operational overhead |
| Object storage + FUSE (S3FS / GCS Fuse) | ⚠️ Cloud-dependent | ❌ | ❌ | ❌ | Low cost, lightweight operations |
| Cache orchestration layer (Alluxio/Fluid) | ✅ | ✅ | ✅ | ✅ | Requires an underlying storage layer, operationally complex |
| JuiceFS | ✅ Backend of your choice | ✅ Full | ✅ | ✅ Built-in | Object storage cost with CSI integration |
Compared with the alternatives, JuiceFS was the only solution that simultaneously met our core requirements: cloud neutrality, full POSIX compatibility, built-in distributed caching, and object storage as the backend. Every other option fell short in at least one of these areas. As a result, for our offline workloads, choosing JuiceFS was a straightforward decision from the very beginning.
Agent: Migrating from GCS Fuse to JuiceFS
Our early infrastructure was primarily deployed on Google Cloud, where Google Cloud Storage (GCS) was mounted into GKE Pods using GCS Fuse. In practice, however, we found that this architecture could not meet the reliability, performance, and cloud-neutrality requirements of our online agent workloads.
The biggest problem was data loss under SIGKILL. GCS Fuse uses an asynchronous writeback mechanism. After an application's write call returns success, data may still sit in a local buffer and not be truly written to GCS. If a Pod is terminated by an OOM kill or a SIGKILL signal, data that appears to have been written successfully may be permanently lost. In an agent workload, this directly causes session data loss.
The second issue was inadequate small-file performance and incomplete POSIX semantics. An agent's working directory typically contains numerous small files with frequent append operations. GCS Fuse introduces high latency for operations such as open and stat, while providing incomplete support for POSIX features such as rename, flock, and symlink. As a result, it falls short of the stability requirements for online services.
The third issue was cloud lock-in and limited stability under high concurrency. GCS Fuse is tightly coupled to the GCP ecosystem, making it incompatible with our cloud-neutral infrastructure strategy. In addition, its stability under highly concurrent agent workloads proved insufficient.
These limitations ultimately led us to migrate our online agent workloads to JuiceFS.
JuiceFS addresses the data loss problem through its write path and independent metadata engine. It separates data from metadata: data chunks are first uploaded to object storage, and only after the corresponding metadata is atomically committed to the independent metadata engine is the write considered successful. In other words, a successful write truly means the data has been durably persisted, so a SIGKILL cannot cause the loss of already acknowledged data.
More fundamentally, GCS Fuse exposes object storage through a file system interface, whereas JuiceFS builds a true file system on top of object storage. Its independent metadata engine, together with full POSIX compatibility, cloud neutrality, built-in distributed caching, and a mature ecosystem of tools, makes JuiceFS a much better fit for online agent workloads that demand reliability, consistency, and high-concurrency access.
Today, our online agent platform runs stably in production. JuiceFS has become the unified storage foundation for multiple workloads across the company.
A new architecture: Deploying JuiceFS across multiple clouds
Offline workloads: Compute mobility across clouds with unified metadata + R2
To meet the requirements of cloud neutrality, compute mobility, and high throughput for offline workloads, we designed the following architecture:
We chose Cloudflare R2 as the underlying object storage backend. Because R2 is independent of any cloud provider and does not charge for egress traffic, it’s well suited for high-throughput training workloads spanning multiple clouds. By comparison, while services such as GCS and Amazon S3 offer low storage costs, their egress fees can be substantial, significantly increasing the cost of offline training. For example, storing 1 TB of data in GCS costs roughly $20 per month, while egress charges can range from $20 to $140.
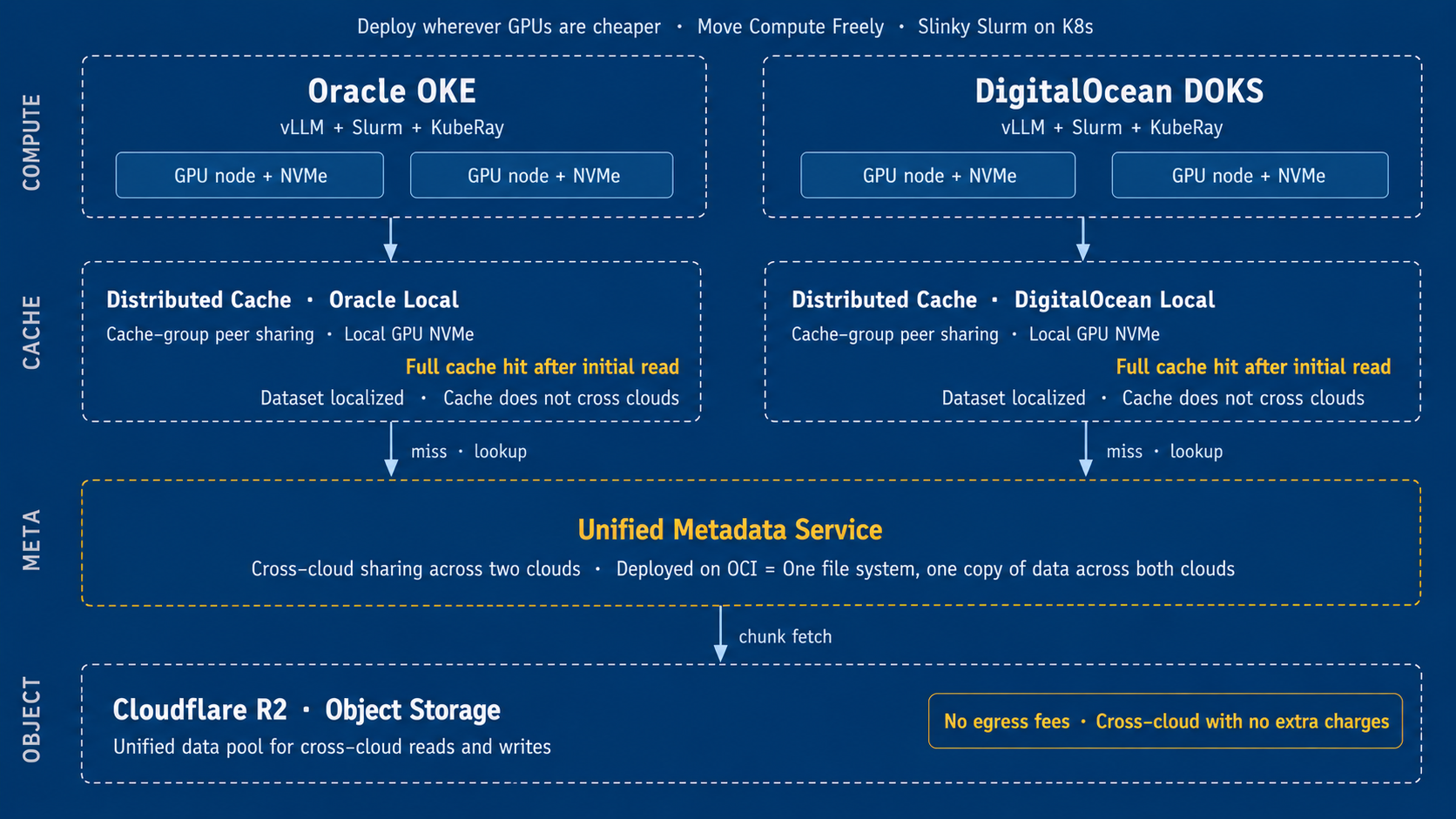
On top of R2, we deployed JuiceFS Enterprise Edition to provide a unified file system across multiple clouds. Whether compute resources are running on Oracle Cloud or DigitalOcean, training, inference, and data processing jobs all access the same file system through a consistent namespace. This allows engineers to work without worrying about the underlying cloud infrastructure.
Our compute layer consists of H100 GPUs on Oracle Cloud and H200 GPUs on DigitalOcean, running a unified training and inference platform based on Slurm and KubeRay. Each GPU node contributes its local NVMe SSD to JuiceFS' distributed cache, forming a shared cache pool across the cluster. Datasets are fetched from R2 on first access, while subsequent reads are served almost entirely from the distributed cache, effectively masking the latency of cross-cloud data access.
The entire infrastructure is managed as code using Terraform. Networks, storage, training jobs, Ray clusters, and inference services can all be provisioned automatically. As long as a cloud provider supports Kubernetes, compute resources and workloads can be deployed seamlessly, enabling rapid cross-cloud scaling and flexible resource allocation.
Online workloads: Prioritizing low latency with in-cloud metadata
For online agent workloads, using ZooClaw as an example, our primary objective is to provide a unified storage foundation for a large number of agents while supporting centralized management, directory isolation, and usage-based billing. Unlike offline workloads, the online environment prioritizes low latency, efficient small-file writes, and high-concurrency access. Cross-cloud storage paths inevitably introduce additional I/O latency, making them unsuitable for latency-sensitive online services. Therefore, we keep the object storage, metadata service, and application Pods within the same cloud whenever possible.
Our current online deployment runs entirely on GCP. GCS serves as the object storage backend, while the metadata layer is provided by an independent three-node Raft cluster deployed within a private GCP VPC. This keeps object storage, metadata service, and application Pods within the same cloud. It reduces access latency and improves IOPS for small‑file write‑intensive scenarios.
On Kubernetes, we mount a single RWX PersistentVolumeClaim (PVC) through JuiceFS CSI. Each bot Pod accesses its own isolated directory through a dedicated subPath, while access is restricted by environment-specific tokens, providing file system-level isolation. From each agent's perspective, it sees only its own local working directory. From the platform's perspective, however, all data resides in a single unified storage system, simplifying centralized management and billing.
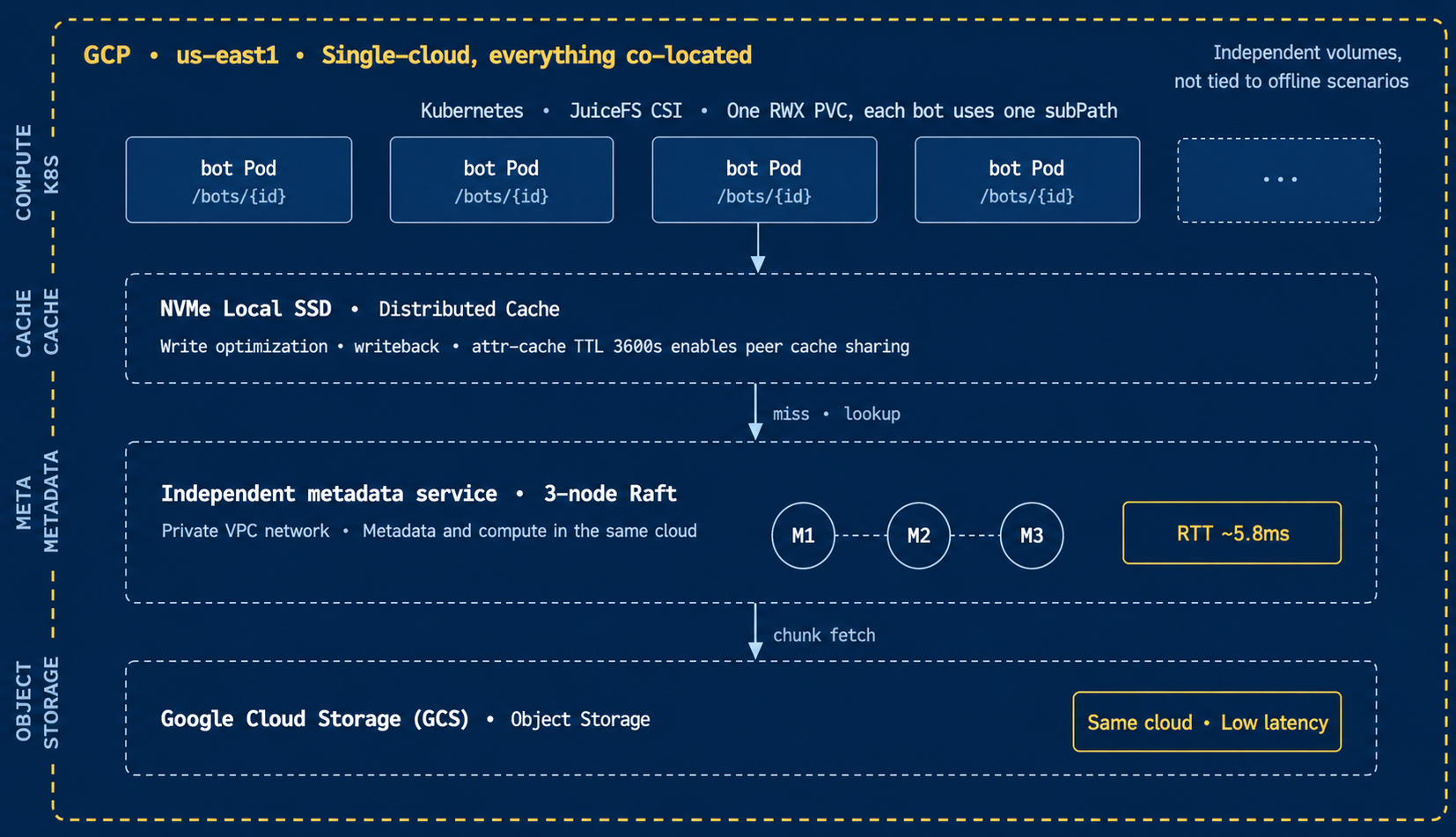
If GCP resources or costs become unsuitable in the future, this architecture can still be migrated. We use Terraform and Kubernetes orchestration. We can spin up the same compute and storage structure on another cloud and then synchronize the metadata and data over. Online agent workloads can naturally be switched bot by bot, user by user, or tenant by tenant. There is no need for a one‑time full migration.
Looking back at both deployment models, their objectives are fundamentally different. Offline workloads emphasize cross-cloud data sharing, compute mobility, and high throughput, while online agent workloads prioritize low latency and high concurrency, without sacrificing the flexibility to migrate when needed. Rather than adopting a one-size-fits-all backend, we tailored the JuiceFS deployment to the requirements of each workload. This approach preserves a unified data management model and developer experience while allowing each scenario to use the most appropriate metadata and object storage architecture.
Optimization practice: Distributed cache, writeback, and S3 Gateway
After establishing a unified storage architecture, we continued to optimize performance and fine-tune access strategies for different workloads.
One cache, two optimization strategies
Distributed caching is one of the most important capabilities of JuiceFS, directly affecting IOPS, throughput, and access latency. Although both our offline and online deployments rely on distributed caching, their goals and optimization strategies differ significantly.
For offline workloads, the primary objective is to support high-throughput training and data processing while enabling cross-cloud data sharing and compute mobility. To achieve this, we cache as much data from Cloudflare R2 as possible on local storage. Training, inference, and data processing jobs run on H100 and H200 GPU nodes equipped with NVMe SSDs. Each node contributes roughly 50 TB of local cache, allowing a cluster of more than a dozen nodes to provide several hundred terabytes of distributed cache capacity.
The first access to a dataset requires fetching data from R2, which is slow. Once the initial read completes, however, subsequent training, data processing, and inference workloads are served almost entirely from the distributed cache, delivering I/O performance close to that of local NVMe storage. Since offline workloads write large checkpoint and model weight files—often hundreds of gigabytes or even several terabytes in size—data integrity is critical. Therefore, we typically leave writeback disabled to ensure that writes are durably persisted before being acknowledged.
For online agent workloads, the priorities are low-latency, high-concurrency access to small files while maintaining data isolation for each agent. Here, the cache is primarily used to accelerate small-file writes and access. Each agent Pod mounts the same RWX PVC and accesses its own isolated directory using a dedicated subPath. The cache expiration time is set to 3,600 seconds to maximize cache hits for frequently accessed files.
Because each agent typically accesses only its own directory, the cache strategy does not require strong cross‑agent consistency. Data is only eventually consistent with object storage during necessary offline analysis or operations debugging.
In online scenarios, to further improve small file write and high concurrency performance, we can use writeback together with caching. Writeback trades a controlled amount of data safety risk for higher write throughput. This means that for multiple agents running on the same node, if one agent fails during writing, only that single agent's output, such as a presentation, an image, or a temporary document, is affected. That data can be regenerated. With writeback, online agents get a significant performance boost for high‑concurrency small file writes, while the overall system remains stable and data isolation is preserved.
One copy of data, multiple interfaces
In our architecture, JuiceFS S3 Gateway serves as the data distribution layer, exposing data stored in JuiceFS through a standard S3-compatible interface.
In agent workloads, whether the data consists of configuration files or generated artifacts such as presentations, images, or videos, everything is ultimately stored in the same JuiceFS file system. However, these files often need to be shared with external users through URLs, making POSIX mounts unsuitable for external access.
To address this, we expose the same data directly through JuiceFS S3 Gateway. Internal services continue to access files through the POSIX interface, while external applications retrieve exactly the same data through standard S3 or HTTP APIs, eliminating the need for duplicate copies.
To further improve security and performance, we place Cloudflare Workers and a CDN in front of the S3 Gateway. Incoming requests first pass through a worker for path validation and access control before being forwarded to the gateway. CDN edge caching and ETag validation further reduce origin fetches.
This design provides two major benefits:
- Multiple layers of isolation ensure data security, including JuiceFS directory isolation, S3 Gateway access controls, and code-level validation implemented in Cloudflare workers.
- CDN caching reduces cross-region access latency and significantly improves download performance for large files such as videos and images. For users around the world, this means that even when the data resides in a GCP region in the eastern United States, content can still be served efficiently from the nearest CDN edge location.
From an architectural perspective, internal training, inference, and agent services access data through the POSIX file system, while external distribution is handled through the S3 Gateway. A single copy of the data can support multiple access methods without any additional replication.
Performance results
Offline workloads: ~4× higher sequential write throughput, 7–8 GB/s cached read performance
For our offline workloads, we conducted benchmark tests on sequential read and write performance. The results before and after optimization are summarized below.
- For sequential writes, a single process achieved approximately 700 MB/s when writing model outputs or checkpoints. By leveraging parallel writes across multiple processes and multiple nodes, throughput exceeded 1 GB/s, providing sufficient performance for large-scale training workloads.
- For sequential reads, after aggregating numerous small files into larger files during data processing and loading them into the distributed cache, cached sequential read throughput reached 6.7–7.8 GB/s, approaching the performance of local NVMe storage. Inference workloads can also load checkpoints directly from the local cache, eliminating the need to copy data across nodes.
| Benchmark (JuiceFS on R2, offline) | Baseline | Optimized (distributed cache + tuning) |
|---|---|---|
| Sequential writes (large blocks) | ~231 MB/s | ~714 MB/s |
| Sequential writes (20–50 GB datasets) | ~256–265 MB/s | 840 MB/s–1.1 GB/s |
| Sequential reads (cache hit) | — | 6.7–7.8 GB/s |
| Sequential reads (cold read from R2) | — | ~427 MB/s |
Beyond performance improvements, distributed caching also streamlined our engineering workflows. Training, inference, and data processing all share the same file path, eliminating the need to copy checkpoints between nodes or services. Newly generated model weights can be loaded directly by inference services, reducing data movement while shortening the path from model training to deployment.
Online workloads: ~42× faster small-file writes and ~85% higher large-file throughput
Our initial deployment placed the metadata service on OCI while using Cloudflare R2 as the object storage backend. Since the online services ran on GCP, every metadata request had to traverse the public Internet, resulting in a metadata round-trip time (RTT) of approximately 12.7 ms. Small-file throughput was limited to around 24 files/s, and occasional 30-second PUT timeouts from R2 could even affect bot stability.
We introduced two major optimizations.
- We enabled writeback and tuned the cache TTL, improving large-file write throughput by approximately 85%.
- We migrated both the metadata service and object storage into GCP. The metadata layer now runs as a three-node Raft cluster within a private VPC, while the object storage backend was migrated to GCS and paired with local NVMe caching.
After these optimizations, metadata RTT dropped to approximately 5.8 ms, while small-file throughput increased to around 1,000 files/s, representing an overall performance improvement of roughly 42×.
Conclusion
After more than a year of production use, JuiceFS has become the core storage layer of Xingchen Zhengtu Technology's infrastructure. Today, it reliably supports more than 100 million files across three cloud providers and multiple application scenarios. More importantly, it has unified the storage architecture for training, inference, data processing, and online agent workloads.
For a startup serving a global market, infrastructure must be both flexible and easy to operate so that engineering efforts can remain focused on product innovation. Our unified storage platform provides a consistent interface for applications and developers, while allowing the underlying infrastructure to be optimized for different workloads. Offline workloads prioritize compute mobility and cost optimization, whereas online workloads focus on low latency and high concurrency while retaining the flexibility to migrate when necessary.
This design keeps a consistent upper‑layer experience, while making compute cost negotiable and resources portable. It sets a solid foundation for future expansion to more clouds and regions.
If you have any questions for this article, feel free to join JuiceFS discussions on GitHub and community on Discord.