















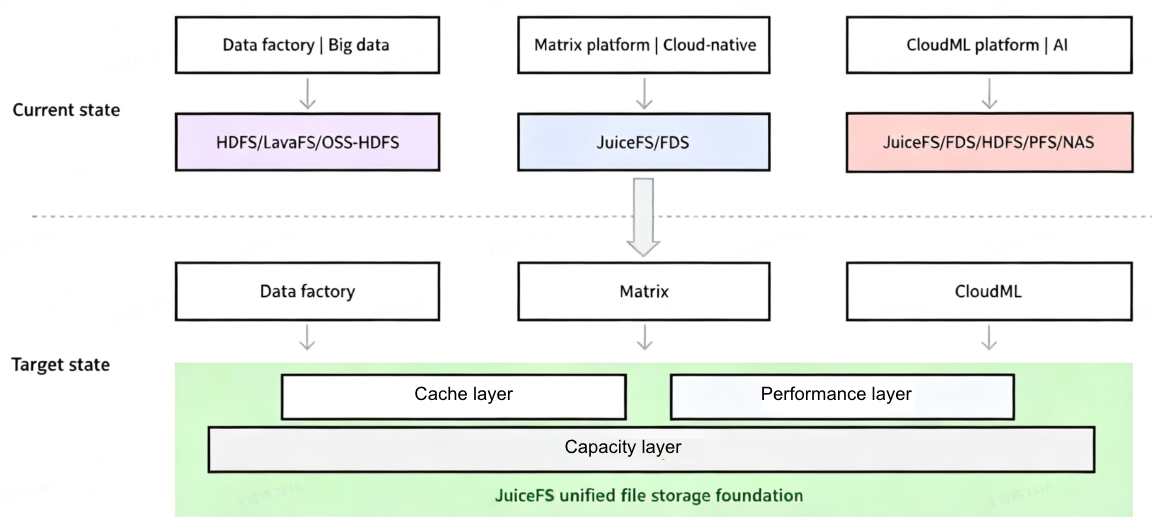
Xiaomi is one of the world's leading smartphone companies. Since 2021, its storage team has been building a file storage platform based on JuiceFS, initially providing file storage capabilities for cloud‑native and some application scenarios. After Xiaomi announced its comprehensive AI strategy in 2024, issues with the previous heterogeneous storage system became more evident in areas such as technology selection, data flow, and development/operations. Leveraging multi‑protocol access, elastic scalability, multi‑cloud adaptability, and high performance, the team decided to build a unified file storage foundation centered on JuiceFS to support big data, cloud‑native, and AI workloads.
To achieve this goal, the platform further developed core capabilities, including a capacity layer, a performance layer, and a cache layer. These reduce the complexity of multi‑system access and data movement while balancing large‑scale storage with high‑performance access. Over the past two years, with the rapid growth of generative AI and autonomous driving, the platform has supported typical scenarios such as large‑model training, autonomous driving training, inference acceleration, and big‑data cloud migration. Today, the platform can handle hundreds of billions of files and EB‑scale storage, covering the entire AI storage chain from raw data and training data to model file distribution.
Storage architecture challenges under the AI strategy
Before 2023, Xiaomi, like most companies, had built multiple storage systems for different application scenarios. In the big data area, the data platform was mainly based on HDFS; AI workloads, before the rise of large language models, relied primarily on high‑performance file storage services on the cloud, such as Parallel File System (PFS) and Network Attached Storage (NAS).
During this period, we also began to introduce JuiceFS and built an internal self‑developed File Storage Service (FDS), using components like JuiceFS CSI Driver to provide file storage for cloud‑native and some application scenarios. As application needs evolved, these storage systems grew independently. This led to a complex heterogeneous storage landscape.
In 2024, after Xiaomi announced its comprehensive AI strategy, the shortcomings of the previous storage system became more pronounced in areas such as technology selection, access, data flow, and development/operations.
These challenges included:
- High selection and access costs: With many storage systems and inconsistent capabilities, application teams had to understand and adapt to each one, raising the barrier to entry.
- Low data flow efficiency: The lack of a unified access method across systems led to frequent cross‑system data copying. This hurt development efficiency.
- Scattered development and operations efforts: Multiple systems were maintained and evolved independently, making it difficult to focus resources on the mission-critical infrastructure required for the AI strategy.
To address these issues, we conducted in‑depth internal discussions and architectural adjustments in 2024, and began redesigning a unified storage architecture for AI, big data, and cloud‑native scenarios.
Building a unified file foundation with JuiceFS
Selection rationale: Multi‑protocol support, elasticity, multi‑cloud, high Performance
JuiceFS is a distributed file system that natively supports multi‑protocol access, elastic scaling, and high‑performance reads/writes. This makes it a perfect fit for both native AI and big data storage needs.
In the cloud-native field, we’ve been using JuiceFS since 2021, continuously conducting internal development and iterative optimization. At the same time, we maintain close collaboration with the JuiceFS open-source community to jointly drive technology evolution and real-world adoption.
In AI scenarios, model training and inference rely heavily on POSIX semantics, which aligns naturally with JuiceFS capabilities. Meanwhile, in the big data area, we were already promoting HDFS replacement during cloud migration, a practice with many mature industry examples, so adapting the HDFS protocol was also feasible.
Considering multi-protocol support, elastic scalability, multi-cloud adaptability, and high-performance read/write, we ultimately chose JuiceFS as the core component of our unified file storage foundation. This solved the problems of complex data flow, high access costs, and scattered operations caused by using different file systems across multiple platforms and application units.
Storage layer capability construction
Our core goal is to build a unified file storage layer on top of JuiceFS, providing large capacity, high performance, and standardized access interfaces to uniformly support the three core application scenarios: big data, cloud-native, and AI.
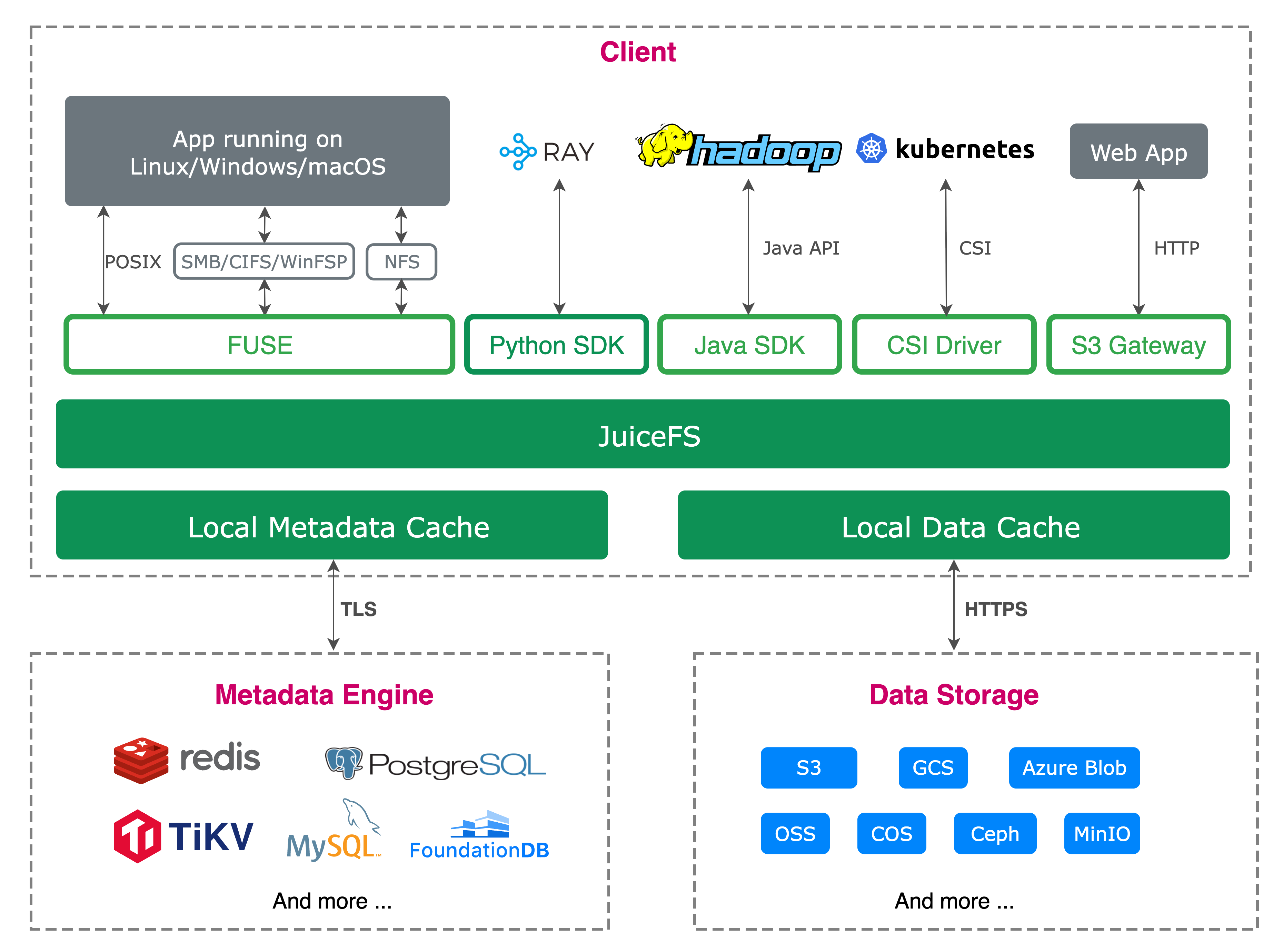
On the client side, we fully leverage JuiceFS’ multi-protocol capabilities, offering access methods including POSIX, Hadoop SDK, Python SDK, and S3 Gateway. They’re all already in use internally.
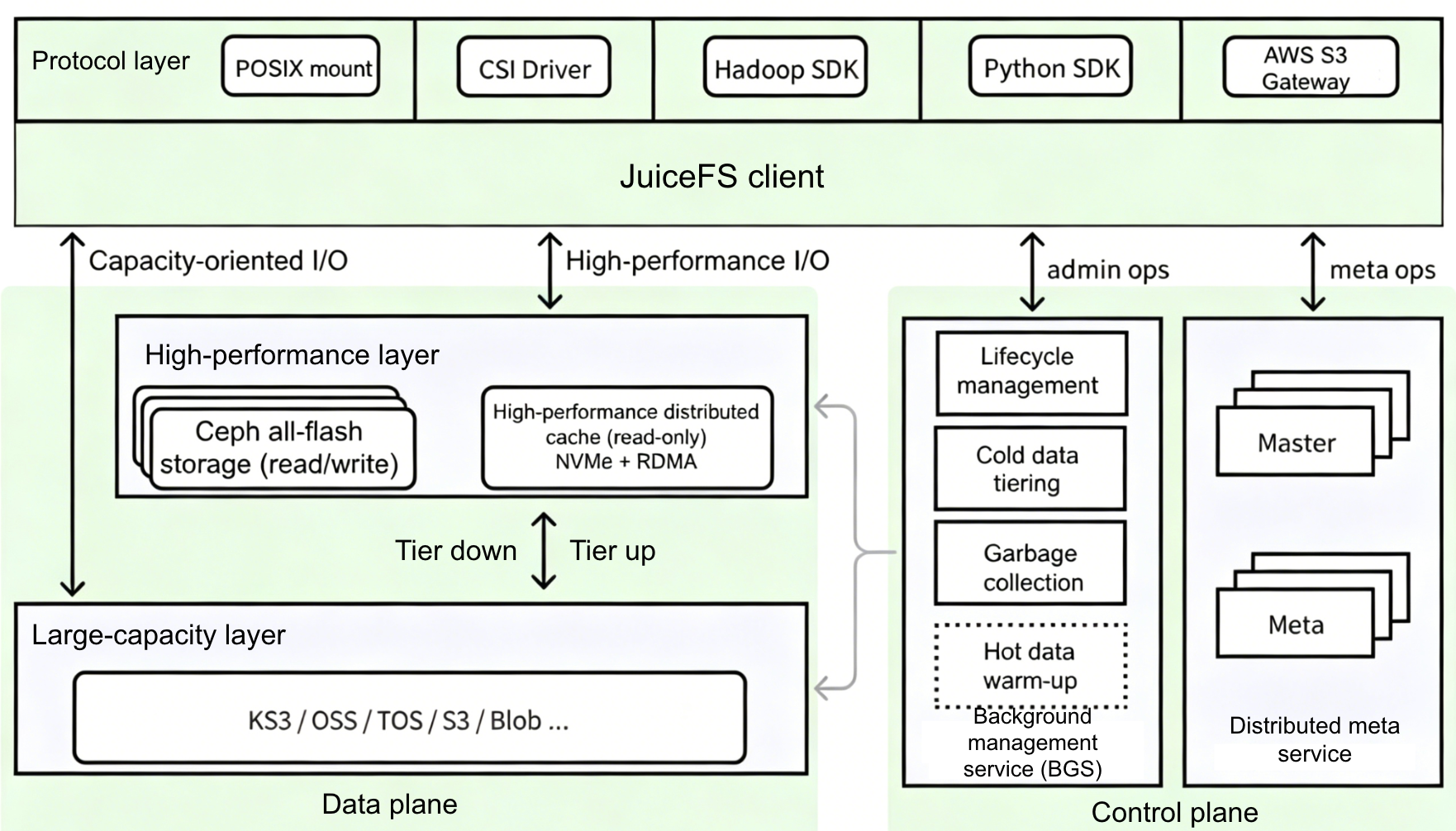
On the data plane, the architecture consists of three layers:
- Capacity layer: Built on public cloud object storage, designed for EB‑scale storage, supporting multi-cloud deployments across different strategic data centers and multiple cloud providers.
- Performance layer: Large‑scale tuning based on Ceph and all‑flash nodes, designed for AI training and other scenarios with high throughput and low latency requirements.
- Cache layer: Given the “write once, read many, seldom modify” characteristic of AI training datasets, we developed a high‑performance distributed cache system based on NVMe and RDMA to reduce repeated read costs and improve training data access efficiency.
On the control plane, we made custom enhancements to the Community Edition:
- For metadata, we built a distributed metadata service based on the Raft protocol to integrate with internal infrastructure systems and support multi-system access, improving reliability and scalability.
- For backend management, we built a unified management service responsible for data lifecycle management, tiered storage, garbage collection, and warm-up of hot data from the capacity layer to the performance or cache layers.
Through these efforts, JuiceFS has gradually become the unified file storage foundation at Xiaomi, supporting both large‑scale capacity storage and high‑performance access for AI training. The architecture is now running in production and provides the high throughput required for large model training.
Our practices
During the construction of the unified file storage foundation, JuiceFS has gradually covered Xiaomi’s mission-critical application scenarios, including big data, cloud-native, and AI:
- In terms of scale, the solution can support EB‑level storage and hundreds of billions of files.
- In terms of capability, the coordinated design of the capacity, performance, and cache layers balances large‑scale storage with high performance.
Below we describe two typical scenarios: big data cloud migration and the AI storage pipeline.
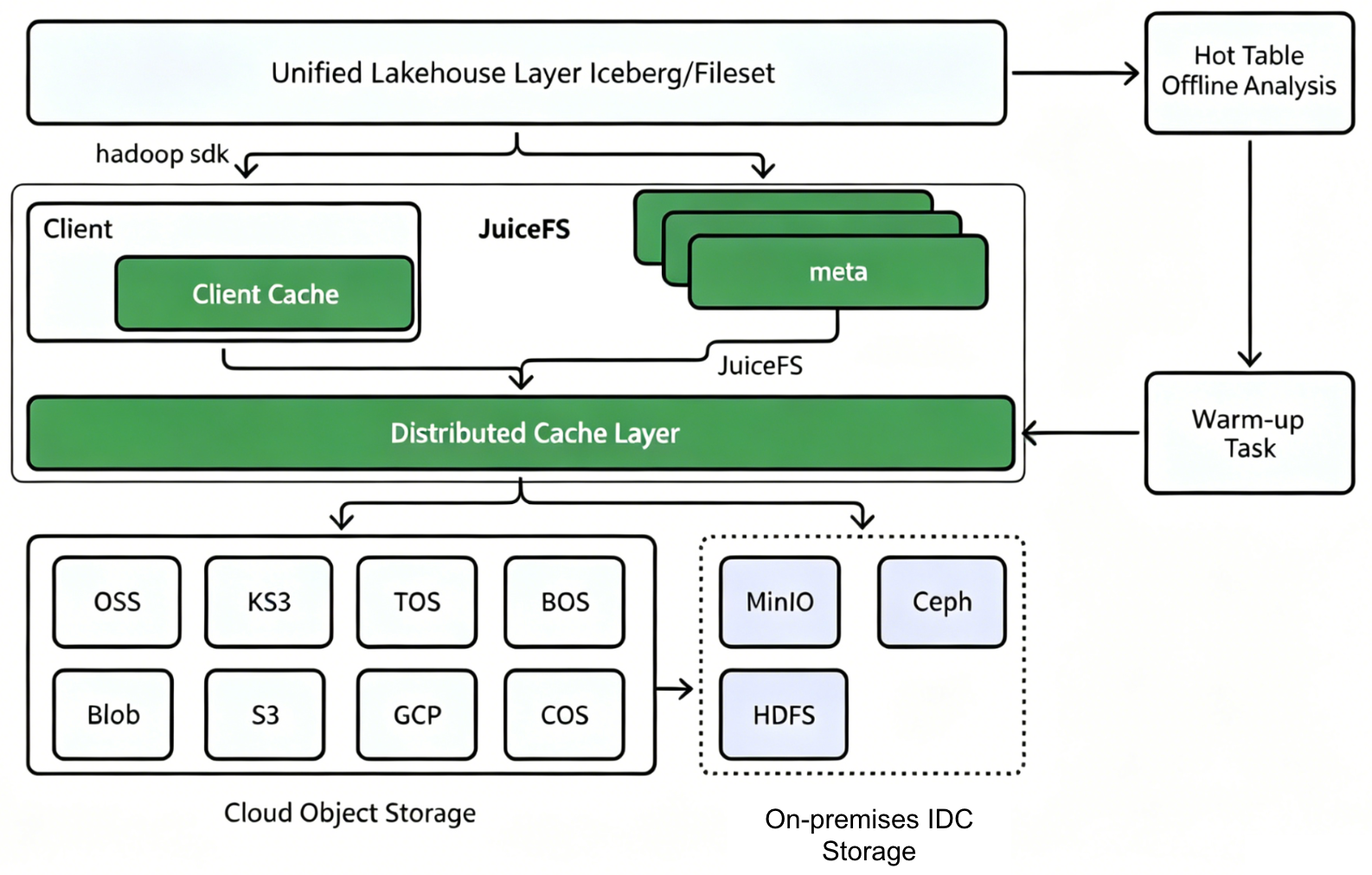
Big data cloud migration and unified lakehouse storage
In its early days, our big data system was mainly built on the Hadoop ecosystem, where HDFS used a previous‑generation coupled architecture. Over time, this architecture showed problems such as performance fluctuations, complex operations, and high total cost. In contrast, cloud storage offers significant advantages in elastic scaling, resource utilization, and cost control. Therefore, starting in 2021, we systematically began migrating big data to the cloud.
From cold data to the lakehouse layer
Our big data cloud migration went through three stages:
- Cold data migration: We first migrated cold data from HDFS to cloud storage, a process lasting over two years.
- Lakehouse layer migration: We self‑developed a unified lakehouse file system, promoting the evolution from coupled to decoupled storage and compute.
- Unified storage foundation based on JuiceFS: After selecting JuiceFS, we migrated the entire lakehouse layer to JuiceFS.
Lakehouse construction can leverage Iceberg’s native support for object storage access (like OSS or S3). However, our application spans multiple regions globally using several cloud vendors. Adapting to each vendor individually would incur high access and maintenance costs.
Thus, we chose JuiceFS to uniformly access different cloud storage. Upper‑layer services simply switch the backend storage address via the SDK to adapt to access in different cloud environments, greatly reducing multi‑cloud complexity.
For data migration, our self‑developed data‑factory platform supports transparently switching a table’s underlying storage to the new architecture and gradually migrates existing data to the cloud in the background, with little or no impact on application. Moreover, JuiceFS supports multi-cloud and on‑premises deployment. If future cost or strategic considerations require switching to self‑built storage, data can be smoothly migrated back via JuiceFS. This preserves architectural flexibility.
Hot table cache acceleration for compute efficiency
After data was in the cloud, we further analyzed access patterns of the lakehouse layer. For daily reporting and analysis tasks, computation is usually concentrated on day‑level or week‑level hot data, not requiring frequent full scans. Therefore, the performance focus for the lakehouse layer was not simply improving full‑scan throughput but rather increasing hot data access efficiency and task execution stability.
Based on this, we built a hot table warm-up capability in cooperation with the lakehouse layer. The system identifies hot tables and their hot partitions based on daily access statistics, and preloads related data into the cache layer before task execution via a warm-up interface. For periodic reporting tasks that must be completed by 8 AM, hot data is warmed up before computation. This reduces remote reads and repeated access.
Through offline and online testing, after hot table caching, compute efficiency improved by about 10-20%, with reductions in both computation time and resource consumption. The cache size has reached PB level, with average throughput around 200 GB/s. The cache layer also reduces cross‑cloud bandwidth pressure and cloud storage API call costs: by improving the hot data hit rate, repeated cross-cloud reads can be reduced, thereby lowering bandwidth consumption and access costs.
Benefits for big data
Benefits for our big data application include:
- Performance: After switching to JuiceFS, sequential read/write performance improved significantly, more than doubling in some scenarios. Overall task duration decreased by about 10–30%.
- Cost: By Xiaomi's internal cost metrics, the unified storage architecture has greatly lowered storage costs – about 70% in China and 90% in overseas regions. The overseas legacy solution, which used HDFS with three replicas on cloud instances and EBS, had a high replication factor and thus higher costs.
- Stability and operations: Under the previous mixed architecture, many compute tasks easily consumed node resources, raising node load and affecting storage performance. With the decoupled storage‑compute architecture, compute tasks run on dedicated nodes, task durations are more stable, and scaling and management are more flexible.
AI one‑stop storage
AI storage consists of three stages:
- Raw data stage: Storing large volumes of raw data, which undergoes processing (for example, ETL) to produce training datasets, then is fed into high‑performance training environments.
- Training stage: Training tasks require high throughput and low latency to reduce I/O wait time and increase GPU utilization. After training, model files are generated for subsequent inference.
- Inference stage: Model files must be quickly distributed to specific nodes for rapid startup of inference tasks.
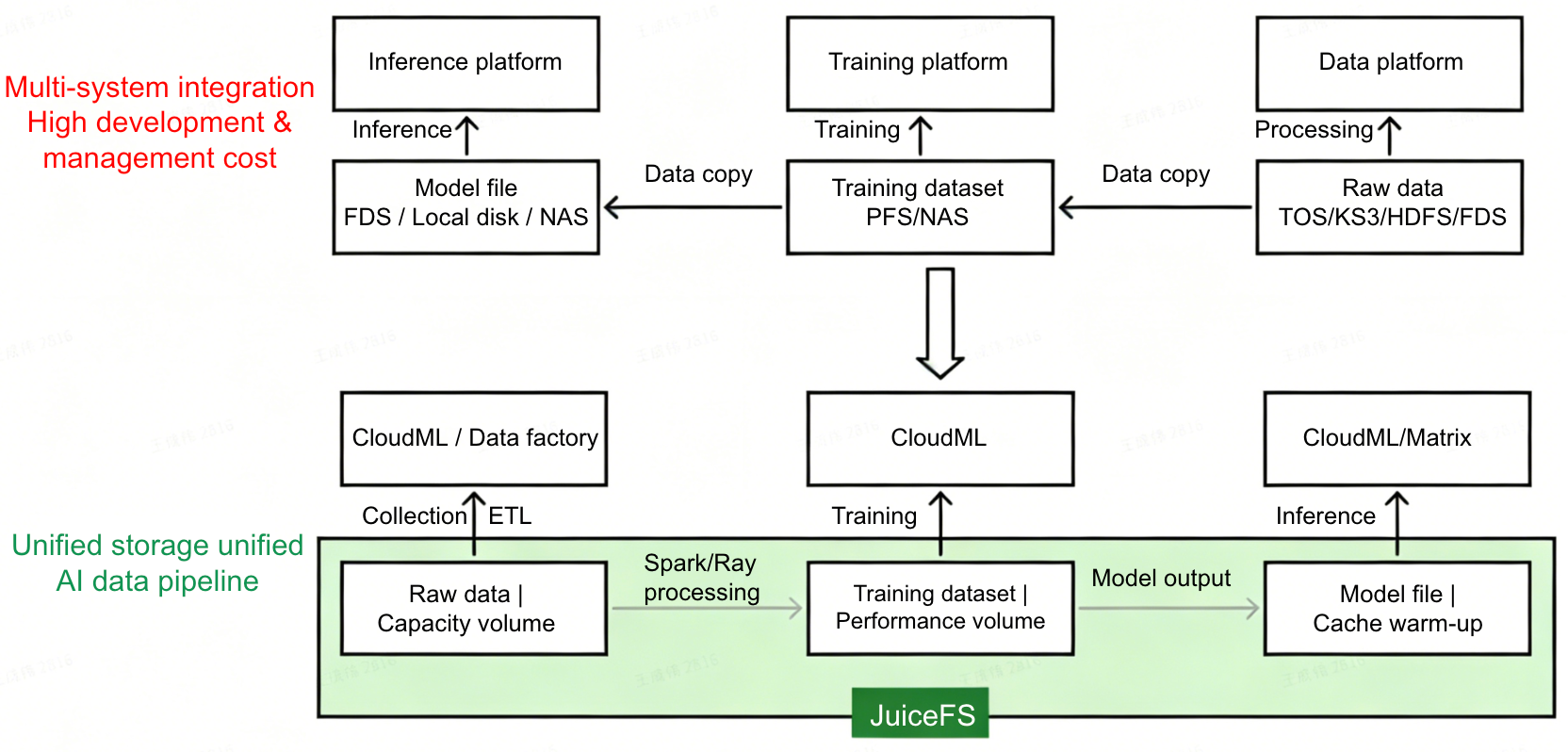
Previously, data flowed among multiple systems, causing inconvenience for both application teams and internal operations. By adopting JuiceFS uniformly, we can meet diverse needs based on different storage tiers.
Requirements and solutions by stage
AI one-stop storage needs to cover three stages: raw data, training data, and model files. The requirements for capacity, performance, cost, and distribution efficiency differ at each stage. The table below compares the application needs for each stage with previous and current solutions.
| Use case | Application requirements | Previous solution | Current solution (JuiceFS) |
|---|---|---|---|
| Raw data | Large capacity, low cost; support high‑concurrency data processing; scale to PB+ | Direct use of object storage; HDFS; other low‑cost storage | Capacity‑oriented JuiceFS: multi‑cloud object storage underlying, shielding vendor differences; EB capacity, hundreds of billions of files; millions of concurrent tasks |
| Training data | High throughput, low latency; reduce I/O wait time; improve GPU utilization | PFS, NAS (good performance but high cost) | Performance‑oriented/cache‑oriented JuiceFS: TB/s throughput, low latency; async checkpoint to reduce I/O wait; cache acceleration |
| Model files | Fast distribution; efficient loading; quick inference startup | P2P distribution; workflow distribution; PFS | Cache‑accelerated JuiceFS: cache improves model loading; up to 16 GB/s sequential load per node; several times faster than local disk or FDS |
High‑performance cache acceleration: improving efficiency and cutting costs
In AI training, training datasets typically have the characteristics of "write once, read many times, and modify very little." This is a typical read-heavy, write-light access pattern, making it suitable for improving data access efficiency through caching.
Take our internal autonomous driving training as an example. Once a dataset version matures, its data volume may continue to grow within the version cycle, but existing data is rarely modified. While the previous high‑performance file storage met training performance requirements, it had some performance redundancy and cost waste for such repetitive reads. Therefore, we began promoting a high‑performance cache acceleration solution based on JuiceFS.
The cache solution offers several advantages:
- Short I/O path: Clients operate on files directly, greatly shortening the I/O path for fast responses.
- Performance optimization: Through RDMA and zero‑copy optimization, performance has significantly improved – throughput more than 20% higher than previous high‑performance storage, with ongoing optimization.
- Cost reduction: The previous PFS‑based storage used replication (though some used EC, replication was more common for stability). With the cache solution, single‑copy storage reduces costs by more than 60%.
- Resource consolidation: For CPU training, GPU nodes typically have NVMe drives (about 10 TB each), which were previously used in scattered ways with low utilization. Now, we consolidate these NVMe resources into a unified cache pool to accelerate nearby GPU training and data processing tasks.
Future plans
Looking ahead, we’ll focus on three directions:
- Continuously improve the stability, performance, and scalability of the unified file storage foundation. As AI application grows rapidly, training, inference, and data processing tasks demand higher throughput, lower latency, and greater reliability. We’ll continue optimizing the underlying architecture and critical paths to enhance service capabilities under large‑scale concurrent access.
- Strengthen lifecycle management for massive data. Current data volumes continue to grow, but management across storage tiers, access frequencies, and retention periods can be further optimized. We’ll refine tiered storage, archiving, warm-up, and cleanup strategies based on data temperature, access patterns, and cost models, reducing unit storage cost and improving resource utilization.
- Enhance data management and analysis capabilities. On top of the unified file storage foundation, we’ll build data management capabilities for application users, helping them better understand data distribution, access behavior, and resource usage, supporting data management, cost optimization, and application decisions.
We look forward to continuous exchanges with industry peers to explore more technical practices. If you have any questions for this article, feel free to join JuiceFS discussions on GitHub and community on Discord.