















Lightillusions is a company specializing in spatial intelligence technology, integrating 3D vision, computer graphics, and generative models to build innovative 3D foundation models. Our company is led by Ping Tan, a professor at the Hong Kong University of Science and Technology (HKUST) and Director of the HKUST-BYD Joint Laboratory.
Unlike 2D models, a single 3D model can be several gigabytes in size, especially complex models like point clouds. When our data volume reached petabyte scales, management and storage became significant challenges. After trying solutions like NFS and GlusterFS, we chose JuiceFS, an open-source high-performance distributed file system, to build a unified storage platform. This platform now serves multiple scenarios, supports cross-platform access including Windows and Linux, manages hundreds of millions of files, improves data processing speed by 200%–250%, enables efficient storage scaling, and greatly simplifies operations and maintenance. This allows us to focus more on core research.
In this article, we’ll break down the unique storage demands of 3D AIGC, share why we selected JuiceFS over CephFS, and walk through the architecture of our JuiceFS-based storage platform.
Storage requirements for 3D AIGC
Our research focuses on perception and generation. In the 3D domain, task complexity is different from image and text processing. This placed higher demands on our AI models, algorithms, and infrastructure.
We illustrate the complexity of 3D data processing through a typical pipeline. On the left side of the diagram below is a 3D model containing texture (top-left) and geometry (bottom-right) information. First, we generate rendered images. Each model has text labels describing its content, geometric features, and texture features, which are tightly coupled with the model. In addition, we process geometry data, such as sampled points and necessary numerical values obtained from data preprocessing, like signed distance fields (SDFs). It's important to note that 3D model file formats are highly diverse, and image formats are also different.
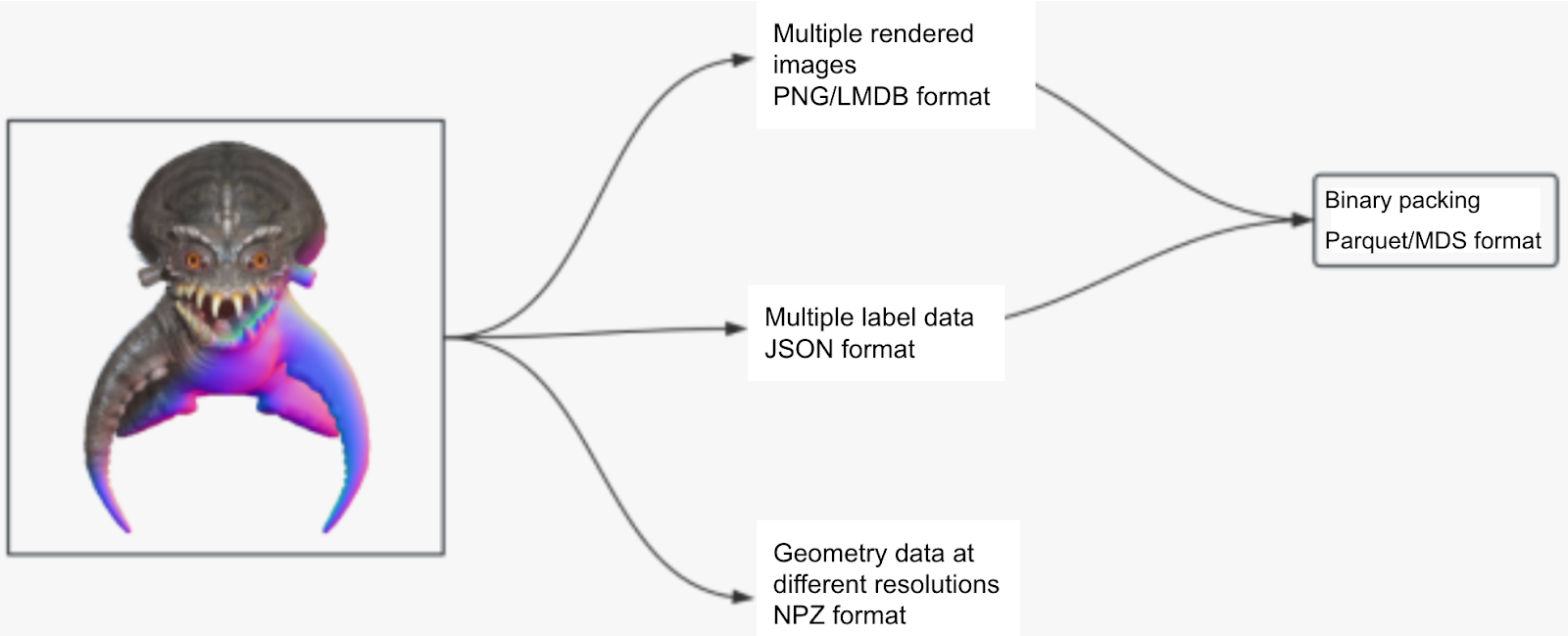
Our work spans language models, image/video models, and 3D models. As data volume grows, so does the storage burden. The main characteristics of data usage in these scenarios are as follows:
- Language models: Data typically consists of a vast number of small files. Although individual text files are small, the total file count can reach millions or even tens of millions as data volume increases. This makes the management of such a large number of files a primary storage challenge.
- Image and video data: High-resolution images and long videos are usually large. A single image can range from hundreds of kilobytes to several megabytes, while video files can reach gigabytes. During preprocessing—such as data augmentation, resolution adjustment, and frame extraction—data volume increases significantly. Especially in video processing, where each video is typically decomposed into a large number of image frames, managing these massive file collections adds considerable complexity.
- 3D models: Individual models, especially complex ones like point clouds, can be several gigabytes in size. 3D data preprocessing is more complex than other data types, involving steps like texture mapping and geometry reconstruction, which consume great computational resources and can increase data volume. Furthermore, 3D models often consist of multiple files, leading to a large total file count. As data grows, managing these files becomes increasingly difficult.
Based on the storage characteristics discussed above, when we chose a storage platform solution, we expected it to meet the following requirements:
- Diverse data formats and cross-node sharing: Different models use different data formats, especially the complexity and cross-platform compatibility issues of 3D models. The storage system must support multiple formats and effectively manage data sharing across nodes and platforms.
- Handling data models of different sizes: Whether it's small files for language models, large-scale image/video data, or large files for 3D models, the storage system must be highly scalable to meet rapidly growing storage demands and handle the storage and access of large-size data efficiently.
- Challenges of cross-cloud and cluster storage: As data volume increases, especially with petabyte-level storage needs for 3D models, cross-cloud and cluster storage issues become more prominent. The storage system must support seamless cross-region, cross-cloud data access and efficient cluster management.
- Easy scaling: The need for scaling is constant, whether for language, image/video, or 3D models, and is particularly high for 3D model storage and processing.
- Simple operations and maintenance: The storage system should provide easy-to-use management interfaces and tools. Especially for 3D model management, operational requirements are higher, making automated management and fault tolerance essential.
Storage solutions: from NFS, GlusterFS, CephFS to JuiceFS
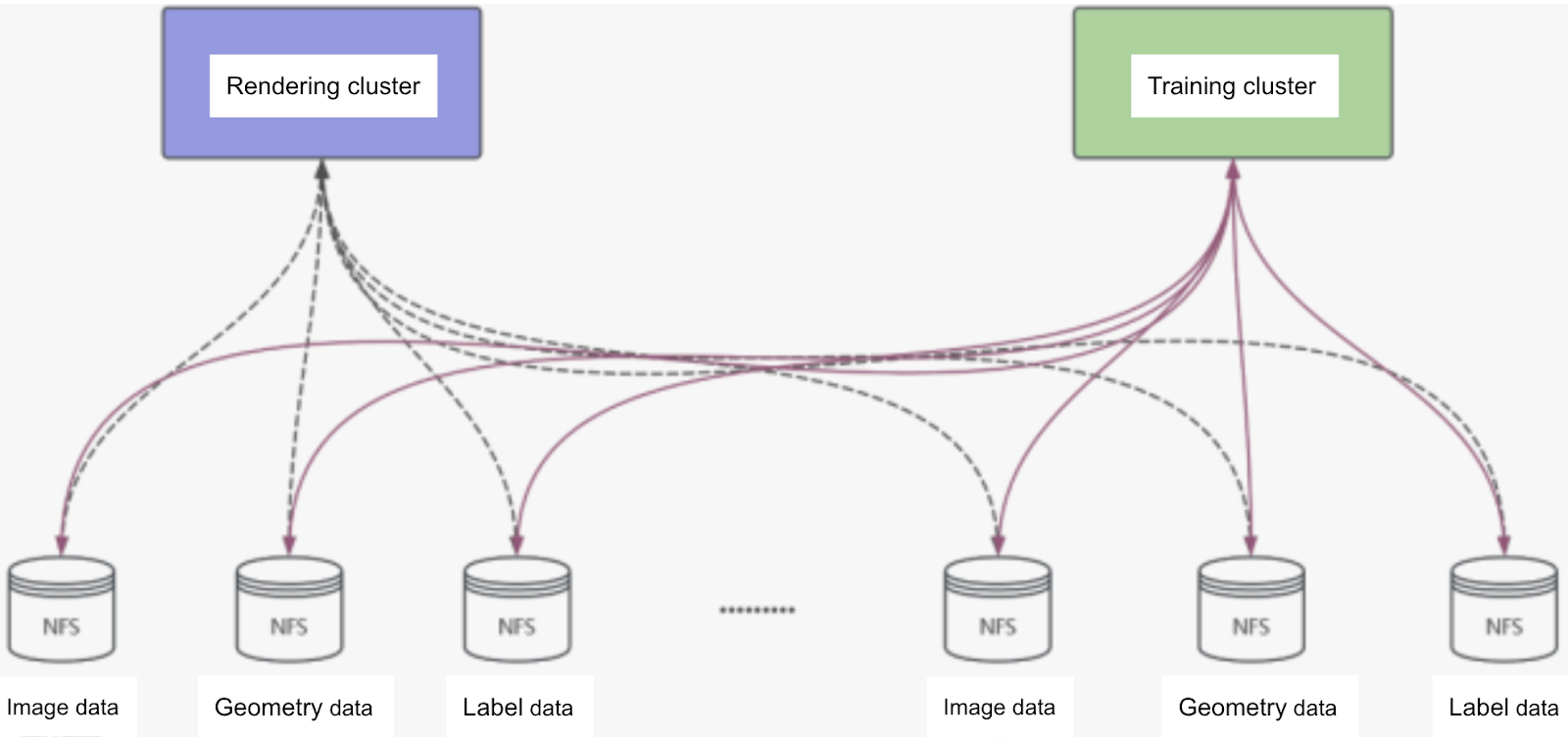
Initial solution: NFS mount
Initially, we tried the simplest solution—using NFS for mounting. However, in practice, we found that the training cluster and rendering cluster required independent clusters for mount operations. Maintaining this setup was very cumbersome. Especially when adding new data, as we needed to write mount points separately for each new dataset. When the data volume reached about 1 million objects, we could no longer sustain this approach and abandoned it.
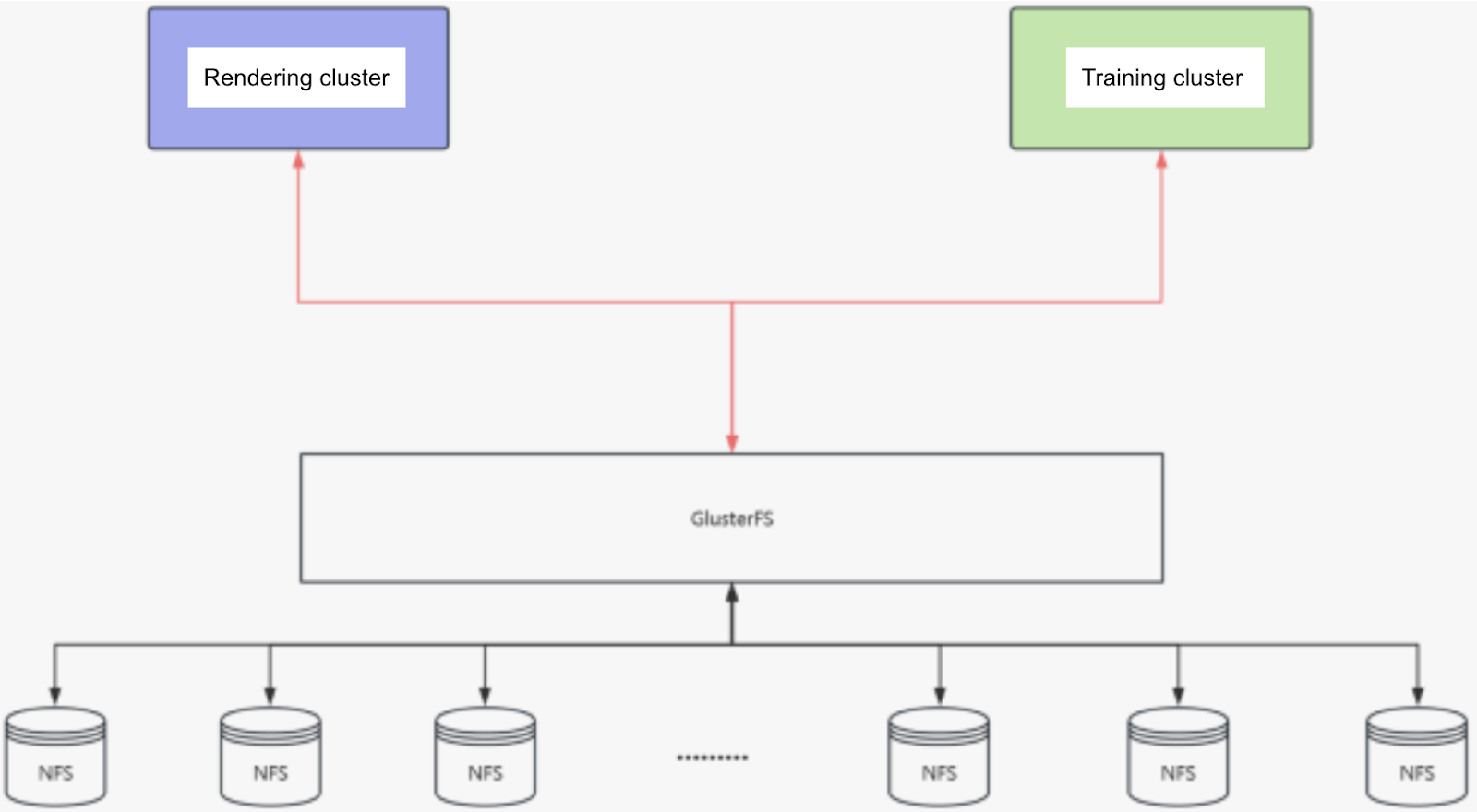
Mid-term solution: GlusterFS
GlusterFS was an easy-to-start-with choice, offering simple installation and configuration, acceptable performance, and no need for multiple mount points—just add new nodes.
While GlusterFS greatly reduced our workload in the early stages, we also discovered issues with its ecosystem:
- Many GlusterFS execution scripts and features required writing custom scheduled tasks. Particularly when adding new storage, it had additional requirements, such as needing to increase nodes by specific multiples.
- Support for operations like cloning and data synchronization was weak. This led us to frequently consult documentation.
- Many operations were unstable. For example, when using tools like fio for speed testing, results were not always reliable.
- A more serious problem was that GlusterFS performance would drastically decline when the number of small files reached a certain scale. For example, one model might generate 100 images. With 10 million models, that would produce 1 billion images. GlusterFS struggled severely with addressing in later stages, especially with an excessive number of small files. This led to significant performance drops and even system crashes.
Final selection: CephFS vs. JuiceFS
As storage demands grew, we decided to use a more sustainable solution. After evaluating various options, we compared CephFS and JuiceFS.
Although Ceph is widely used, through our own practice and reviewing documentation, we found Ceph's operational and management costs to be very high. Especially for a small team like ours, handling such complex operational tasks proved particularly difficult.
JuiceFS had two native features that strongly aligned with our needs:
- The client data cache. For our model training clusters, which are typically equipped with high-performance NVMe storage, fully utilizing client caching could significantly accelerate model training and reduce pressure on the JuiceFS storage backend.
- JuiceFS' S3 compatibility was crucial for us. As we had developed some visualization platforms based on storage for data annotation, organization, and statistics, S3 compatibility allowed us to rapidly develop web interfaces supporting visualization, data statistics, and other features.
The table below compares basic features of CephFS and JuiceFS:
| Comparison basis | CephFS | JuiceFS |
|---|---|---|
| File chunking | ✓ | ✓ |
| Metadata transactions | ✓ | ✓ |
| Strong consistency | ✓ | ✓ |
| Kubernetes CSI Driver | ✓ | ✓ |
| Hadoop-compatible | ✓ | ✓ |
| Data compression | ✓ | ✓ |
| Data encryption | ✓ | ✓ |
| Snapshot | ✓ | ✓ |
| Client data caching | ✕ | ✓ |
| Hadoop data locality | ✕ | ✓ |
| S3-compatible | ✕ | ✓ |
| Quota | Directory level quota | Directory level quota |
| Languages | C++ | Go |
| License | LGPLv2.1 & LGPLv3 | Apache License 2.0 |
Storage platform practice based on JuiceFS
Metadata engine selection and topology
JuiceFS employs a metadata-data separation architecture with several metadata engine options. We first quickly validated the Redis storage solution, which is well-documented by the JuiceFS team. Redis' advantage lies in its lightweight nature; configuration typically takes only a day or half a day, and data migration is smooth. However, when the number of small files exceeded 100 million, Redis' speed and performance significantly declined.
As mentioned earlier, each model might render 100 images. With other miscellaneous files, the number of small files increased dramatically. While we could mitigate the issue by packing small files, performing modifications or visualization on packed data greatly increased complexity. Therefore, we preferred to retain the original small image files for subsequent processing
As the file count grew and soon exceeded Redis' capacity, we decided to migrate the storage system to a combination of TiKV and Kubernetes (K8s). The TiKV-K8s setup provided us with a more highly available metadata storage solution. Furthermore, through benchmarking, we found that although TiKV's performance was slightly lower, the gap was not significant, and its support for small files was better than Redis'. We also consulted JuiceFS engineers and learned that Redis has poor scalability in cluster mode. Therefore, we switched to TiKV.
The table below shows read/write performance test results for different metadata engines:
| Redis-always | Redis-every second | MySQL | PostgreSQL | TiKV | etcd | FoundationDB | |
|---|---|---|---|---|---|---|---|
| Write big files | 730.84 MiB/s | 731.93 MiB/s | 729.00 MiB/s | 744.47 MiB/s | 730.01 MiB/s | 746.07 MiB/s | 744.70 MiB/s |
| Read big files | 923.98 MiB/s | 892.99 MiB/s | 905.93 MiB/s | 895.88 MiB/s | 918.19 MiB/s | 939.63 MiB/s | 948.81 MiB/s |
| Write small files | 95.20 files/s | 109.10 files/s | 82.30 files/s | 86.40 files/s | 101.20 files/s | 95.80 files/s | 94.60 files/s |
| Read small files | 1242.80 files/s | 937.30 files/s | 752.40 files/s | 1857.90 files/s | 681.50 files/s | 1229.10 files/s | 1301.40 files/s |
| Stat files | 12313.80 files/s | 11989.50 files/s | 3583.10 files/s | 7845.80 files/s | 4211.20 files/s | 2836.60 files/s | 3400.00 files/s |
| FUSE operations | 0.41 ms/op | 0.40 ms/op | 0.46 ms/op | 0.44 ms/op | 0.41 ms/op | 0.41 ms/op | 0.44 ms/op |
| Update metadata | 2.45 ms/op | 1.76 ms/op | 2.46 ms/op | 1.78 ms/op | 3.76 ms/op | 3.40 ms/op | 2.87 ms/op |
Latest architecture: JuiceFS+TiKV+SeaweedFS
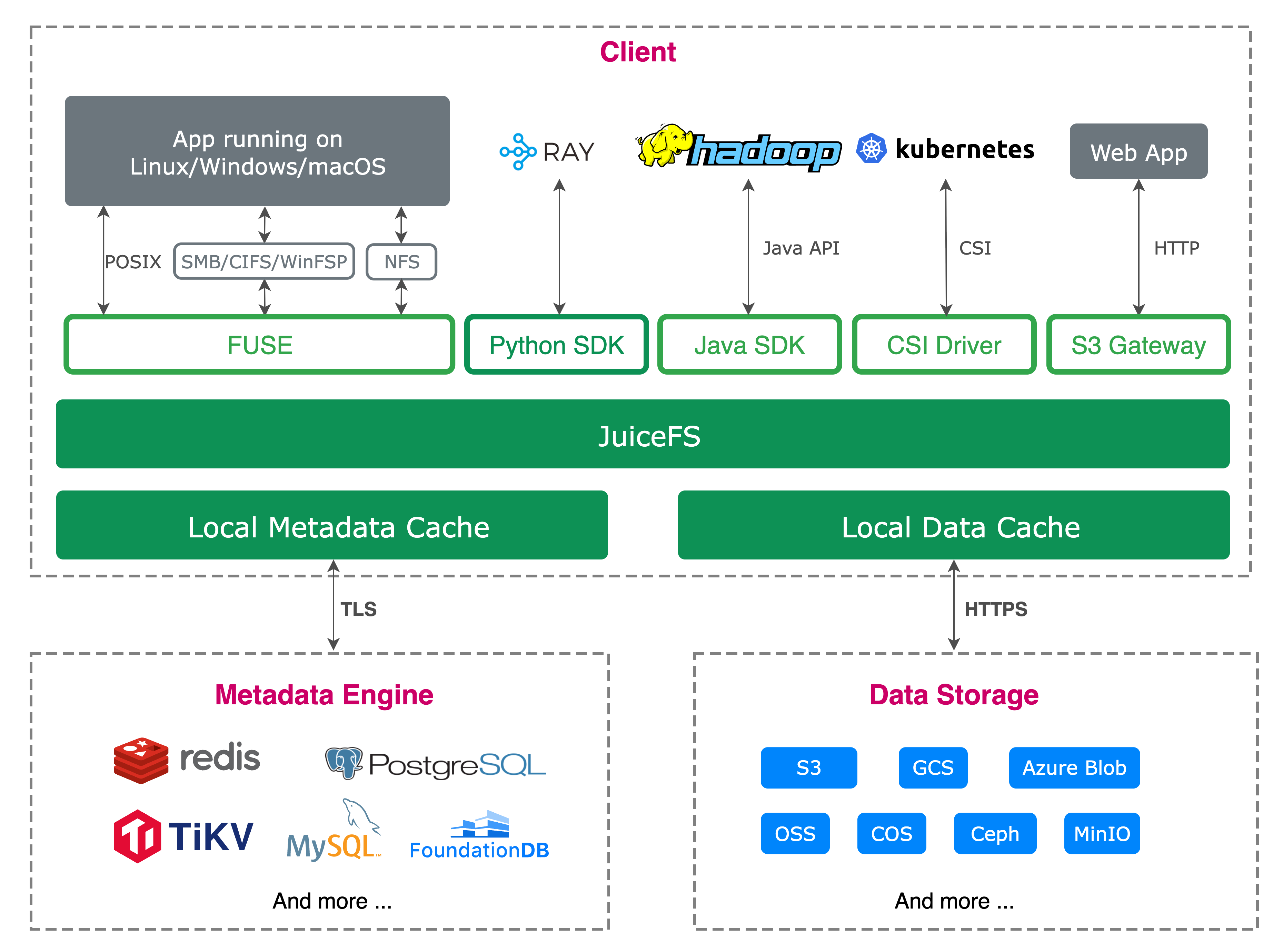
We use JuiceFS to manage the object storage layer. For the metadata storage system, we built it with TiKV and K8s. For object storage, we used SeaweedFS. This allows us to quickly scale storage capacity and provides fast access for both small and large files. In addition, our object storage is distributed across multiple platforms, including local storage and platforms like R2 and Amazon S3. Through JuiceFS, we were able to integrate these different storage systems and provide a unified interface.
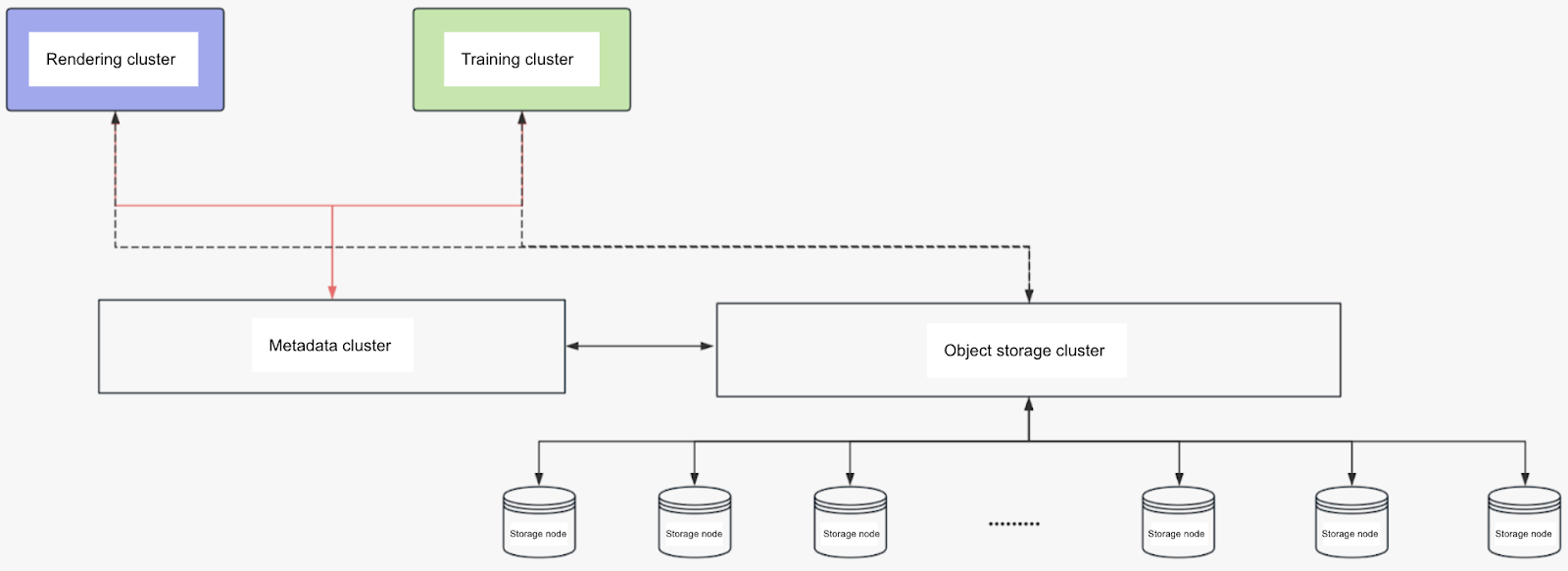
To better manage system resources, we built a resource monitoring platform on K8s. The current system consists of about 60 Linux nodes and several Windows nodes handling rendering and data processing tasks. We monitored read stability, and the results show that even with multiple heterogeneous servers performing simultaneous read operations, the overall system I/O performance remains stable, able to fully utilize the bandwidth resources.
Problems we encountered
During the optimization of the storage solution, we initially tried an erasure code (EC) storage scheme aimed at reducing storage requirements and improving efficiency. However, in large-scale data migration, EC storage computation was slow, and its performance was unsatisfactory in high-throughput and frequent data change scenarios. Especially when combined with SeaweedFS, bottlenecks existed. Based on these issues, we decided to abandon EC storage and switch to a replication-based storage scheme.
We set up independent servers and configured scheduled tasks for large-volume metadata backups. In TiKV, we implemented a redundant replica mechanism, adopting a multi-replica scheme to ensure data integrity. For object storage, we used dual-replica encoding to further enhance data reliability. Although replica storage effectively ensures data redundancy and high availability, storage costs remain high due to processing petabyte-scale data and massive incremental data. In the future, we may consider further optimizing the storage scheme to reduce costs.
In addition, we found that using all-flash servers with JuiceFS did not bring significant performance improvements. The bottleneck mainly appeared in network bandwidth and latency. Therefore, we plan to consider using InfiniBand to connect storage servers and training servers to maximize resource utilization efficiency.
Summary
When using GlusterFS, we could process at most 200,000 models per day. After switching to JuiceFS, the processing capacity increased significantly. Our daily data processing capacity has grown by 2.5 times. Small file throughput also improved notably. The system remained stable even when storage utilization reached 70%. Furthermore, scaling became very convenient, whereas the previous architecture involved troublesome scaling processes.
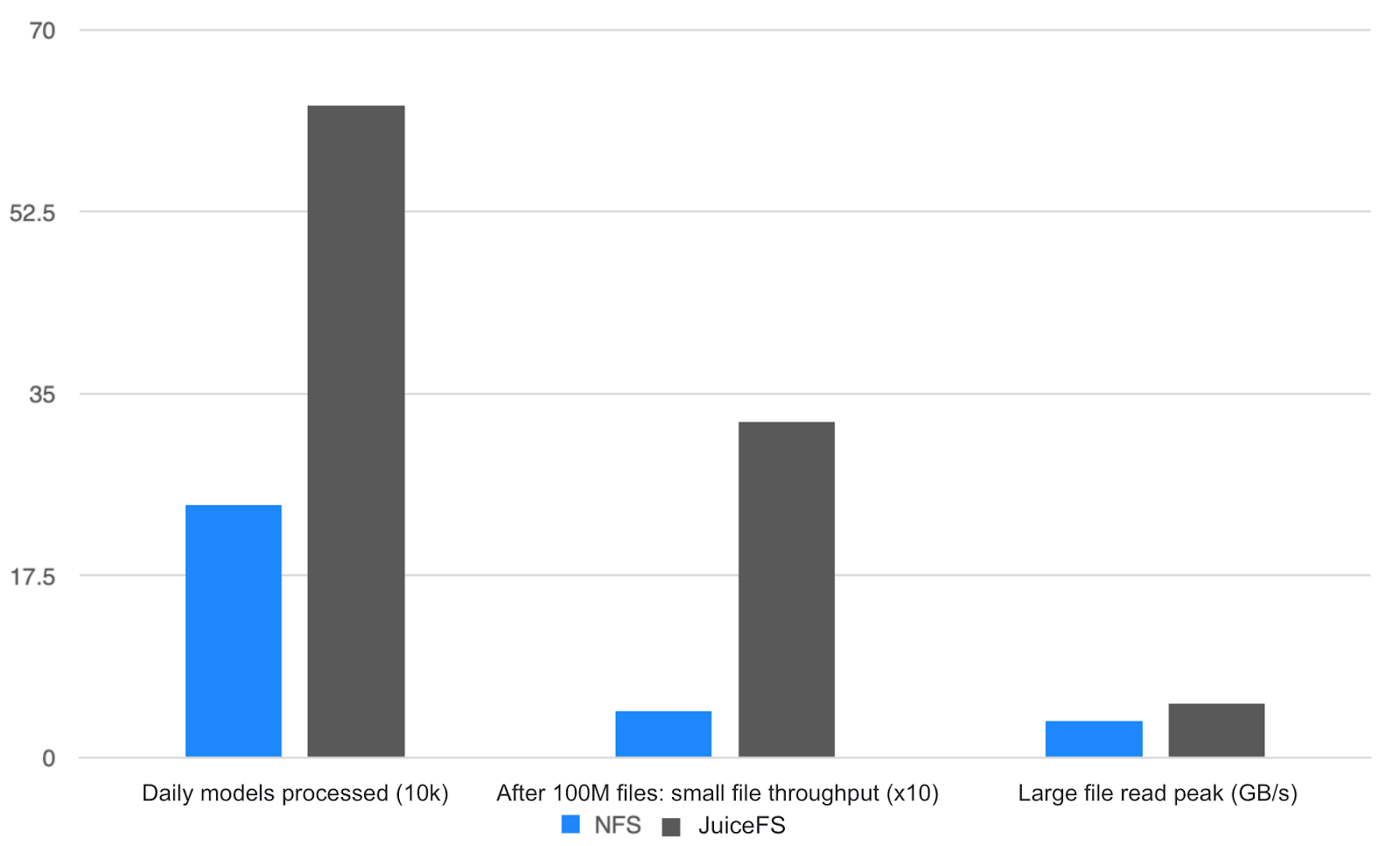
Finally, let's summarize the advantages JuiceFS has demonstrated in 3D generation tasks:
- Small file performance: Small file handling is a critical point, and JuiceFS provides an excellent solution.
- Cross-platform features: Cross-platform support is very important. We found that some data can only be opened in Windows software, so we need to process the same data on both Windows and Linux systems and perform read/write operations on the same mount point. This requirement makes cross-platform features particularly crucial, and JuiceFS' design addresses this well.
- Low operational cost: JuiceFS' operational cost is extremely low. After configuration, only simple testing and node management (for example, discarding certain nodes and monitoring robustness) are needed. We spent about half a year migrating data and have not encountered major issues so far.
- Local cache mechanism: Previously, to use local cache, we needed to manually implement local caching logic in our code. JuiceFS provides a very convenient local caching mechanism, optimizing performance for training scenarios by setting mount parameters.
- Low migration cost: Especially when migrating small files, we found using JuiceFS for metadata and object storage migration to be convenient, saving us a lot of time and effort. In contrast, migrating with other storage systems was very painful.
In summary, JuiceFS performs excellently in large-scale data processing, providing an efficient and stable storage solution. It not only simplifies storage management and scaling but also significantly improves system performance. This allows us to focus more on advancing core tasks. In addition, the JuiceFS tools are very convenient. For example, we used the sync tool for small file migration with extremely high efficiency. Without additional performance optimization, we successfully migrated 500 TB of data, including a massive number of small data and image files. It was done in less than 5 days, exceeding our expectations.
If you have any questions for this article, feel free to join JuiceFS discussions on GitHub and community on Slack.