















coScene pioneers the Chinese AI industry's data scene platform. We simplify R&D and operations for intelligent multimodal scenarios, addressing high-cost, low-efficiency issues in complex data processing for autonomous driving, robotics, IoT, augmented reality, and more.
In the commercial service robot field, monitoring robot performance, conducting regular maintenance, troubleshooting, software updates, and data management generate large amounts of data. Data processing efficiency plays a decisive role in reducing costs and improving work efficiency.
To address storage issues such as performance limitations in object storage, we use JuiceFS, a cloud-native distributed file system. Notably, we’ve applied the clone feature, recently released in JuiceFS Community Edition 1.1, in our data version management, effectively enhancing the simulation training efficiency.
This post will cover what the data closed loop is and how we apply JuiceFS in various scenarios. I’ll also share why we chose JuiceFS over Alluxio in data collection.
What is the data closed loop for robots?
In this article, robots specifically refer to commercial service robots, such as common cleaning robots and food delivery robots. Data closed loop refers to collecting software system operational data from end-users to optimize product functionality and user experience.
The workflow of a robot data closed loop:
- The robot system captures and uploads data related to on-site issues. This data, including sensor data and information on perception, planning, and control, is directly collected for subsequent processing.
- Engineers work on solving on-site issues, with the primary task being the visualization processing of the collected data from the previous step. This requires direct access to the data stored in JuiceFS.
The development iteration phase for problem-solving may involve logic optimization of robot system code or adjustment of algorithm models. At this stage, sensor data is used for annotation and training. Regardless of the type of solution, it must be validated through simulation testing, requiring the implementation of data version management.
Applying JuiceFS in multiple scenarios
Data collection
Robots collect a vast amount of data. For example, one of our customers in daily operation has hundreds of active devices. The duration of each data collection is one minute, and the amount of data generated every minute can reach hundreds of megabytes. Therefore, the daily data increment is several hundred gigabytes.
Object storage’s limitations
Given that this data is often unstructured, it’s well-suited to store raw data directly in object storage. However, object storage has limitations:
- From a design perspective, it automatically partitions based on keys, making it easy to reach query limits (QPS) with continuous prefixes. This limitation is evident in well-known services like Amazon S3.
- If users want to use object storage as a file system through FUSE, it's essential to note that open-source tools like s3fs exhibit mediocre performance and compatibility. For specific feature comparisons, see JuiceFS vs. s3fs.
Therefore, we were looking for a more optimal storage solution that could provide the convenience of object storage while delivering superior performance.
Why we chose JuiceFS over Alluxio
We did not choose Alluxio because of its inadequate compatibility with S3 and FUSE protocols. For example, in the case of the S3 protocol, it supports range access when reading data, similar to efficient operations in a file system. Initially, Alluxio did not support this feature. Although I submitted a pull request to address this issue when I encountered Alluxio in 2020, the community merged it in 2021. Consequently, we decided to abandon Alluxio.
Finally, we opted for JuiceFS, because it has these advantages:
- JuiceFS effectively circumvents some limitations of object storage in its design. For example, querying raw data does not depend on the API provided by object storage but is implemented by automatically dispersing files into object storage.
- JuiceFS has a highly active community, with developers being very responsive to issues. This further motivated us to adopt this tool.
- JuiceFS not only supports various object storage products but is also well-suited for use as a storage layer in a multi-cloud environment. Choosing JuiceFS can effectively reduce the complexity and challenges posed by different storage products.
For details, see JuiceFS vs. Alluxio.
Data visualization
To help you understand the importance of JuiceFS in data visualization, let's briefly introduce the common raw data storage formats in the robot industry. Most systems use file formats such as ROS or MCAP, which record and store data during the actual operation of the robot system.
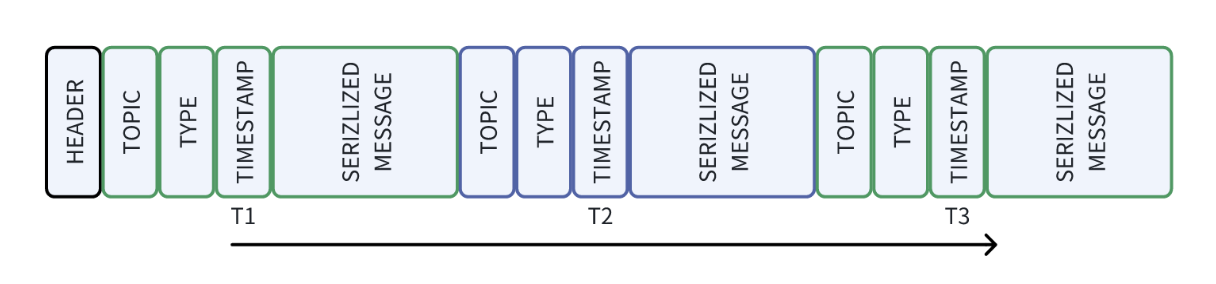
The data collected by our devices is saved in the system in chronological order. The following diagram shows this storage structure:
- HEADER stores metadata of some files.
- TOPICs for different types of sensors, such as laser radar and camera, each corresponding to a TOPIC.
- TYPE defines the data structure of each TOPIC; for example, the data structure for laser radar is typically referred to as a point cloud.
- TIME STAMP records the time when the sensor collects data.
- SERIZLIZED MESSAGE stores the actual collected data.
In the real-world application scenario of data visualization:
- Operators respond to work orders submitted by users.
- After obtaining user authorization, operators send data collection requests to the devices.
- The collected data needs to be quickly accessed and visualized. In this process, JuiceFS' caching feature plays a crucial role. The data is cached simultaneously during writing, making it easy to hit the cache in subsequent access, significantly improving the efficiency of data utilization. This efficient data processing is vital for quickly resolving work orders and enhancing user experience.
Furthermore, JuiceFS demonstrates significant advantages in data processing. Due to the time series characteristics of raw data, a large amount of sequential continuous data needs to be read sequentially during data visualization. JuiceFS provides readahead and prefetch features (see Readahead and Prefetch), allowing computing resources to be more effectively utilized. Specifically, when processing current frame data, JuiceFS automatically pre-reads data for subsequent frames. This mechanism not only improves the efficiency of data processing but also saves computing resources, making the entire data processing workflow more efficient and smooth.
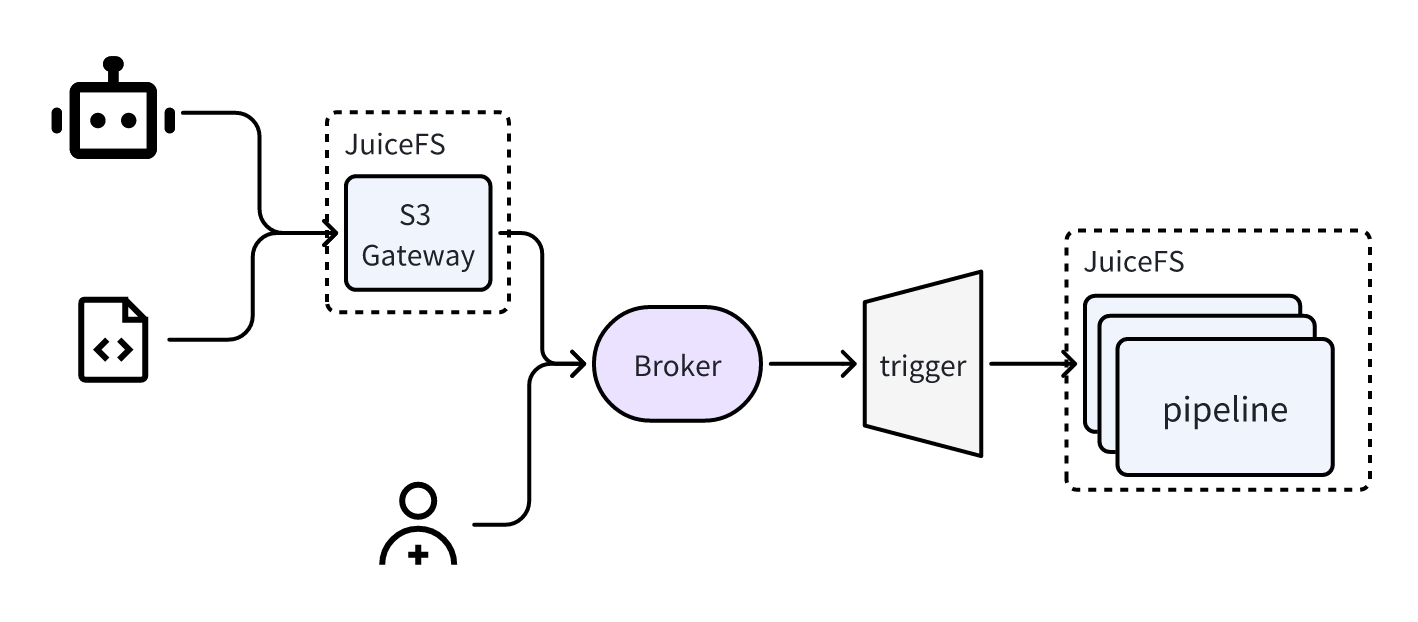
Data pipeline
The diagram below shows our data pipeline process: 1. We upload raw data and software for testing to JuiceFS through the S3 gateway. 2. These processes can be triggered automatically or manually through setting unified events and rules. In our system, in addition to events generated by the S3 gateway, other events from internal systems are also integrated. All pipeline operations are executed in our Kubernetes cluster. If you’re interested in a deeper understanding of using JuiceFS in Kubernetes clusters, see the JuiceFS documentation.
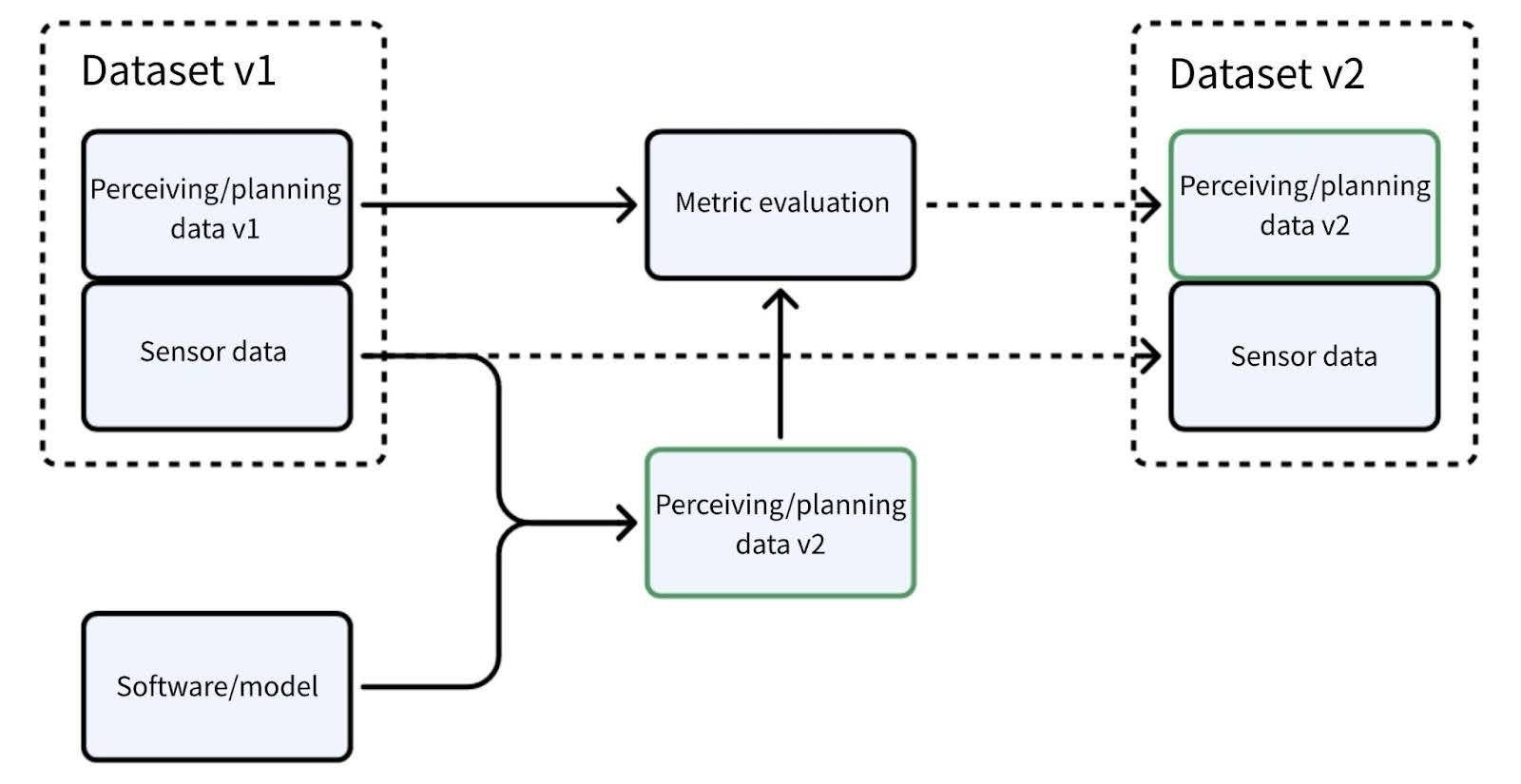
Data versioning
As the figure below shows, when we conduct simulation tests for software or model iterations, we rely on previously collected sensor data. This data is used to compare the results of planning and perception and evaluate them based on specific metrics. The purpose of this process is to determine which result is superior, leading to the generation of a new dataset. This process reflects the application-level data processing and analysis. Through this approach, we can precisely assess the effectiveness of each iteration step, ensuring optimization and enhancement of the final results.
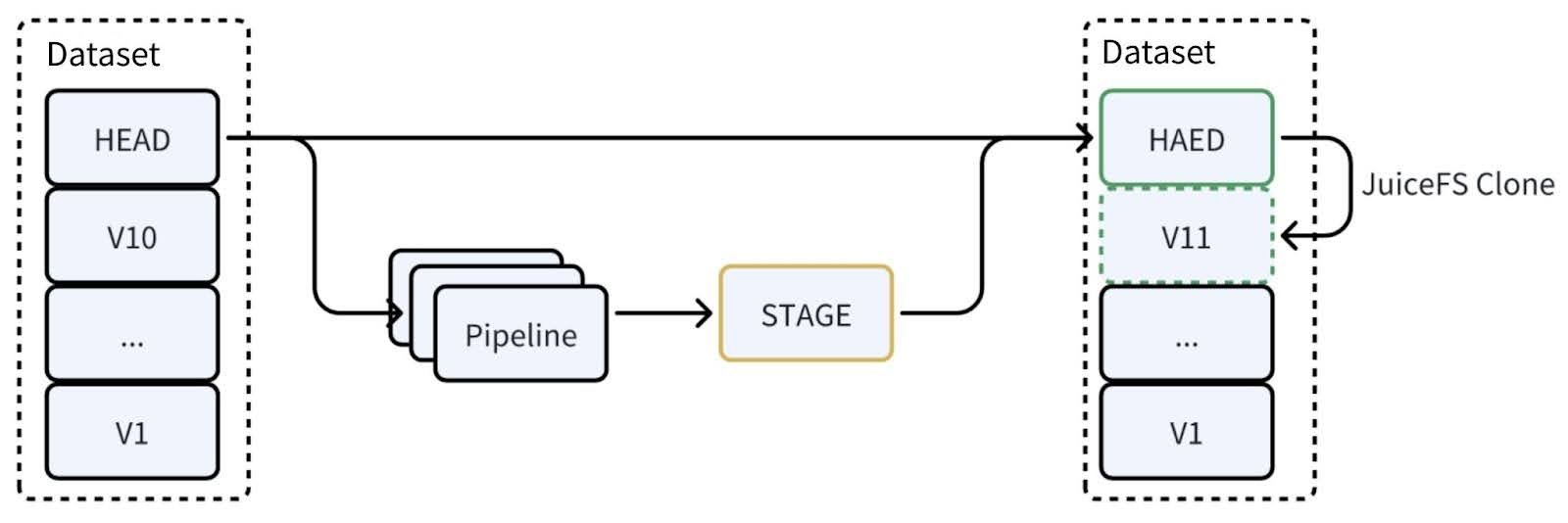
At the operational level, when we run Python:
- The system specifies the mounting of a specific version of the data. For example, in the diagram below, the system mounts the latest HEAD data version.
- We filter out better data from the execution results, forming a new version.
In this process, the management of historical versions relies on JuiceFS' cloning functionality. In the future, if our engineers need to compare or roll back to a specific historical version, they can directly mount the corresponding file version. JuiceFS' cloning feature only creates new metadata without copying the actual storage data, making the entire process highly efficient. This approach not only ensures flexible management of data versions but also significantly reduces storage space requirements, improving operational efficiency.
Typically, a single dataset contains approximately two hundred files, making the completion time for cloning operations within one second. Given that version creation is not a frequent operation, such performance is acceptable.
JuiceFS' cloning feature demonstrates exceptional efficiency when moving or copying datasets, similar to its use in data version management. However, we must note that the cloning feature has certain limitations. It’s more suitable for datasets with many small files and frequent operations. This characteristic makes JuiceFS highly efficient in handling such specific datasets, while considerations about its limiting factors may be necessary in other scenarios.
Finally, we want to express special thanks to the JuiceFS team for bringing us such an outstanding storage system. It greatly advances the development of our data platform and contributes to the success of our business.
If you have any questions or would like to learn more, feel free to join JuiceFS discussions on GitHub and their community on Slack.