















Background
Founded in 2018, Metabit Trading is an AI-Based quantitative trading firm. The core members graduated from Stanford, CMU, Tsinghua, Peking University etc. Currently, the management scale has exceeded RMB 3 billion.
Metabit attaches great importance to the construction of infrastructure platform and has a strong Research Infrastructure team. The team tries to overcome single node development difficulties by embracing cloud computing for more efficient and secure tool chain development.
01 What does quantitative trading research do?
As a quantitative funds established not long ago, we are influenced by two factors when we setting up the infra storage platform:we prefer to use a more modern technology stack like cloud computing since we are a newly established company; At the same time, the characteristics in the machine learning scenarios used in quantitative trading analytics will also influence the choice of technology.
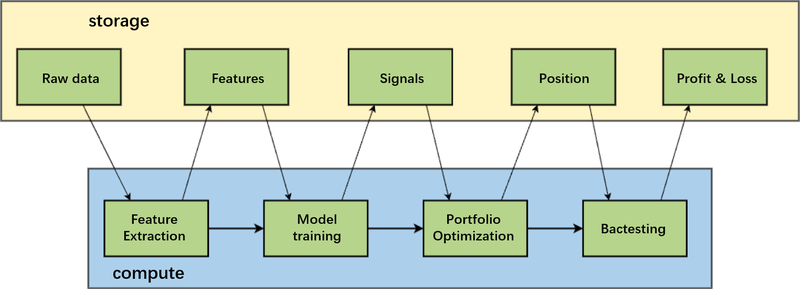
The above figure is a simplified schematic of the research model that is most closely associated with machine learning in our research scenario. First, feature extraction needs to be done on the original data before model training . The signal-to-noise ratio of financial data is particularly low, and if the original data is used directly for training, the resulting model will be very noisy.
The raw data includes not only the market data, i.e. the stock price and trading volume, but also some non-quantitative data, such as research reports, earnings reports, news, social media and other unstructured data, which researchers extract features through a series of transformations and then train AI models.
Model training produces signals, which are predictions on future price trends; the strength of the signals implies the strength of the strategy orientation. The researcher will use this information to optimize the portfolio, which results in a real-time position for trading. This process takes into account information from the horizontal dimension (stocks) for risk control, such as not taking excessive positions in stocks in a certain sector. After the position strategy is formed, the quantitative researcher will simulate the order, and then get the profit and loss information corresponding to the real-time position, so as to understand the performance of the strategy's return.
Task Characteristics of quantitative research
Quantitative trading research generates a lot of unexpected tasks, the data volume is highly flexible. In the course of quantitative research, researchers experiment to validate their ideas. With the emergence of new ideas, the computing platform then generates a large number of bursty tasks, so we have a high demand for the elastic scaling capability of computing.
Quantitative Trading research tasks are diversified. As can be seen from the above example, the whole process covers a very large number of different computational tasks, such as:
- feature extraction, computations on time-series data.
- model training, the classical machine learning scenario of model training.
- Portfolio optimization, tasks that would involve optimization problems.
- Trading Strategy backtesting, reading in the data of the market, and then simulating the performance of the strategy to get the performance of the corresponding positions.
The variety of tasks in the whole process is very diverse, and the computational requirements are also very different.
Research content needs to be protected and segregated by modules. The content of quantitative research is important IP (intellectual property). To protect it, the platform abstracts each strategy segment into modules that contain standard inputs and outputs and evaluation methods. For example, for the study of models, inputs are standardized eigenvalues, while outputs are signals and models. By isolating the modules from each other, the platform can effectively protect the IP. When constructing the storage platform, it needs to be designed accordingly for this need of modularity.
Data Features of quantitative Research
The input of a large number of tasks comes from the same data, such as the backtesting mentioned above, where researchers need to do a lot of backtesting on historical strategies, using different parameters to test the same positions and observe their performance; or feature extraction, where there is often a combination of some basic features and new features, where a large amount of data comes from the same data source.
Take A-share stocks as an example: 10 years of A-share market's minute K-line history quotes, 5000/2 stocks * 240 minutes * 250 days * 10 years * 8 bytes * 20 columns = 240GB, the overall 10-year data volume is about 240G.
If we use more granular data, the data volume will be larger, generally speaking the raw data will not exceed the 100TB range. In the era of big data, this is not a particularly large amount of data, but when a large number of computing tasks go to access this data at the same time, this scenario will have some requirements for data storage.
In addition, the quantitative investment research process is accompanied by a large number of unexpected tasks, and the research team wants to store the results of these tasks, thus generating a large amount of archive data, but these data are accessed infrequently.
Based on the above characteristics, it is difficult to meet our computing needs if we use the traditional self-hosted data center approach, so moving the computing to the cloud computing platform is a relatively appropriate technology choice for us.
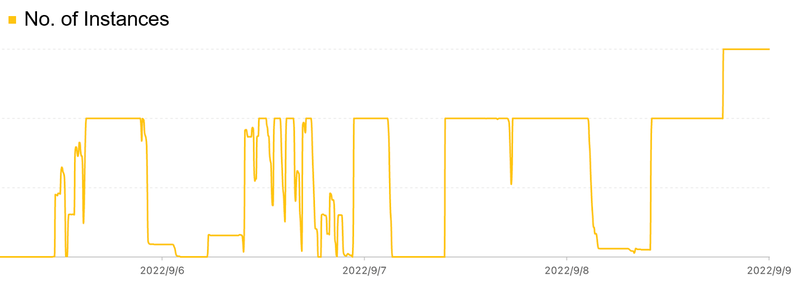
First, there are many bursty tasks and very high resilience. The figure above shows the recent running instance data of one of our clusters. You can see that the whole cluster is full several times, but at the same time, the scale of the whole computing cluster will also scale to 0 at times. There is a strong correlation between the computational tasks of quantitative institutions and the progress of researchers' research and development, and the gap between peaks and valleys can be very large, which is also a characteristic of offline research tasks.
Second, the "technology explosion", it is difficult to accurately predict when the demand for computing power will arise. The "technology explosion" is a concept from the science fiction novel "Three Bodies", which means that our research model and the demand for computing power will progress by leaps and bounds, and it is difficult to accurately predict the change in computing power demand. The actual and estimated usage of our research in the beginning of 2020 is very small, but when the research team comes up with some new ideas of research methods, there will be a sudden and very large demand for arithmetic capability at some moment. And capacity planning is a very important thing if the data centers are selfed hosted.
Third, the modern AI ecology is almost on the cloud-native platform. We have made a lot of innovative technical attempts, including the now very popular MLOps, which connects the whole set of pipelines together to do the machine learning training pipeline; now a lot of distributed training task support is oriented to cloud-native to do a lot of development work, which also makes it a natural choice for us to put the whole computing task on the cloud.
02 Storage Requirements of Quantitative Trading Research Platform
Based on the above business and computing requirements, it is relatively easy to derive the requirements for our storage platform.
- Separation of storage and computing. As mentioned above there will be a big burst of computing tasks and the amount of computation will reach very high levels suddenly. However the amount of hot data does not grow that fast, which means we need to go for storage and computation separation.
- Provides high throughput access to hot data, such as ticker data. Hundreds of tasks accessing data at the same time requires very high throughput.
- Provide low-cost storage for cold data. quantitative research requires large amounts of archive data.
- POSIX compatibility to adapt diverse file types/requirements. We have a lot of different computing tasks, and the requirements for file types are very diverse, such as CSV, Parquet, etc. Some research scenarios also have more flexible custom development requirements, which means that we cannot strictly restrict the file storage method, so POSIX compatibility is a very critical consideration for storage platform.
- IP protection: data sharing and isolation. We need to supply isolation capacity not only to computing tasks but also some data; at the same time for public data such as stock quotes ,we need to support researchers to access them easily.
- Various task scheduling in cloud platform. This is one of the basic requirements. Thus the storage platform needs to work well with Kubernetes.
- Modularity i.e. intermediate result storage/transfer. The modularity of computational tasks leads to the need for intermediate result storage and transmission. As a simple example, a relatively large amount of feature data is generated during the feature computation, which is immediately used on the nodes being trained, and we need an intermediate storage medium for caching.
03 Storage Solution Selection
Non-POSIX Compatible Solutions
Initially, we tried a lot of object storage solutions, which are non-POSIX solutions. Object storage has great scalability and its cost is very low, but there are obvious problems with object storage. The biggest problem is the lack of POSIX compatibility. The use of object storage is quite different from the file system, so if object storage is directly used as an interface for researchers, it will be very difficult for them.
On top of that, many cloud vendors have request limits on their object storage. For example, Alibaba Cloud will limit the OSS bandwidth for the entire account. This is usually acceptable for common scenarios, but bursty tasks can generate very large bandwidth requirements in an instant, and it is difficult to support such scenarios using object storage alone.
The other option is HDFS, on which we have not done much testing. First of all, the technology stack we use does not have a strong dependency on Hadoop; at the same time, the support of HDFS for AI training products is not particularly outstanding, and HDFS does not have full POSIX compatibility, which will have some limitations for our scenarios.
POSIX-compatible solutions on the cloud
The business characteristics mentioned above dictate a strong need for POSIX compatibility, and the technology platform is based on the public cloud, so we determined the scope of storage selection as: POSIX-compatible on the cloud.
Cloud vendors offer some solutions, such as Alibaba Cloud's NAS, AWS EFS, etc. Another category is the CPFS solution like Alibaba Cloud and Amazon FSx for Lustre. The throughput of these two types of file systems is tied to capacity, and when the capacity is larger, the throughput will be larger, which is directly related to the nature of NAS storage. Such solution is not suitable for small amounts of hot data. It requires additional optimization to achieve better performance. CPFS or Extreme NAS on Alibaba Cloud is friendly to low-latency reads, but the disadvantage is its high costs. .
We did a comparison of the prices displayed on their websites. The cost of various high-performance NAS products is about $1500-2000/TB/month, and the overall cost of JuiceFS is much lower because the underlying storage of JuiceFS is object storage.
The cost of JuiceFS is divided into several parts: the storage cost of object storage; the cost of JuiceFS cloud services; and the cost of SSD caching. Taken together, the overall cost of JuiceFS is much lower than the cost of NAS and other solutions.
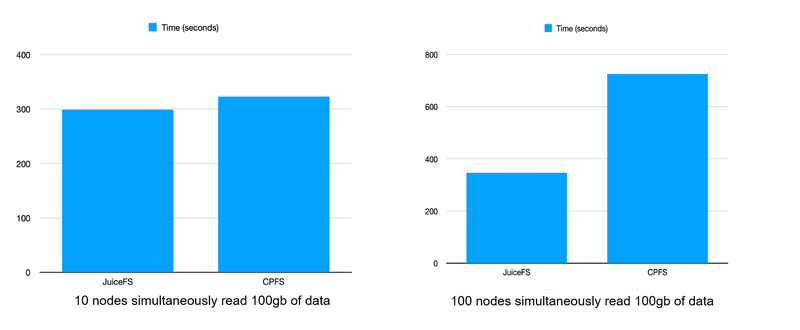
In terms of throughput, we did some tests early on, and when the number of nodes was relatively small, there was no big difference in read performance between CPFS and JuiceF directly. However, when the number of nodes becomes larger, the overall read time is lengthened because of the bandwidth limitation of NAS-like file systems. while JuiceFS can easily support it without much overhead as long as the cache clusters are well deployed.
In addition to cost and throughput, JuiceFS supports the features mentioned above Full POSIX, permission control, Qos, and Kubernetes relatively well.
It is worth mentioning the cache clustering capability of JuiceFS, which enables flexible cache acceleration. In the beginning, we used compute nodes for local caching, which is a pretty common practice. After the separation of storage and compute, we wanted to have some data localized on the compute nodes, and JuiceFS supports this feature relatively well, with a very good support for space occupation, percentage limits,etc.
We deployed a dedicated JuiceFS cache cluster to serve hot data. Data is manually warmed up before use: we found that the resource utilization varies greatly from one computing cluster to another. There are some large bandwidth nodes in the cluster, which are mostly used for single-node computing, which means that the network and disk resources of these nodes are not fully utilized . So we deploy JuiceFS Client on these nodes and convert them to a high bandwidth dedicated JuiceFS cache cluster to take advantage of the idle resources.
Currently , JuiceFS is used in the following production scenarios.
- File systems for computational tasks, which are applied to hot data input.
- Log/artifact output.
- Pipeline data transfer: After data features are generated, they need to be transferred to the model training, and the training process will also have the need for data transfer, and Fluid + JuiceFS Runtime is used as an intermediate cache cluster.
In the future, we will continue to explore cloud-native and AI technologies for more efficient and secure tool development and infra platform construction.