















Author
Yangbin Li, the architect in DP Technology and the former head of the Cloud Computing Department in Meicai, has many years of work experience in the Internet industry. Yangbin joined DP Technology at the beginning of 2022, focusing on the implementing HPC over cloud.
Background
DPTechnology, founded in 2018, is dedicated to using artificial intelligence and molecular simulation algorithms to create a next-generation micro-scale industrial design and simulation platform for research of fundamental biomedicine, energy, materials, and information science and engineering.
What is AI for Science?
There have been two major paradigms for scientific research - the Keplerian paradigm and the Newtonian paradigm. The former one is the data-driven approach, which extracts the scientific discoveries through data collection and data analysis. It is very effective for finding facts, but less effective for explaining the mechanisms behind the facts.
The Newtonian paradigm, based on first principle, aims at understanding at the most fundamental level. It belongs to the model-driven approach, which is relatively accurate compared to the data-driven. Still, the Newton paradigm is not commonly used in practice because of the large amount of calculation.
AI for Science (AI4S) is an innovative technology that combines both two paradigms and adopts modern AI and machine learning technologies for science discovery.
Drug design and material development are two main businesses in DPTechnology. One major subject in drug design is protein structure prediction, and the main work in material development is to discover new materials and study their physicochemical properties. Both works are essentially the study of the interaction and motion trajectory of microscopic particles, in which, however, it is difficult to adopt the first principle because of the Curse of Dimensionality. The innovative AI4S is specially designed to overcome this problem by combining AI and a series of physical equations, attempting to achieve a balance between accuracy and efficiency.
Challenge of hybrid cloud architecture
Why hybrid cloud architecture
DPTechnology, as a start-up, has chosen the hybrid cloud architecture for the following reasons.
- Need for computing power. AI4S is primarily used in supercomputing, and it requires high performance and computational power. Some universities and institutes have their own supercomputer, e.g., Milkyway-2. In 2014, the Milky Way series was ranked No. 1 in the Top500 lists (a Global High Performance Computing ranking).
The above screenshot shows the computation takes 5 days with 128 A100 CPUs.
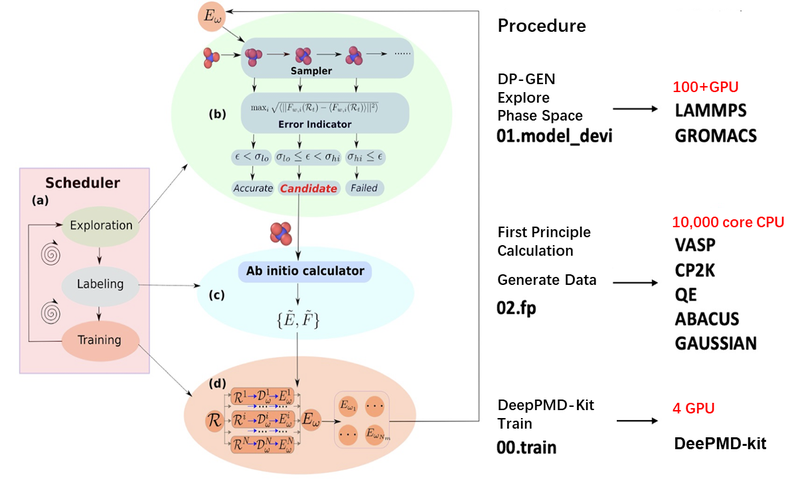
The following scheme shows a workflow of model training, which is divided into three steps. These steps are quite different in the need for resources: Steps 1 and 3 have high requirements for GPU, while Step 2 needs a high-performance CPU with more than 10,000 cores.
This example also exhibits one characteristic of AI4S: the difference in requirements for resources at different stages for the same task is relatively big.
- Customer’s demands. Some customers are users of AWS, Alibaba Cloud, or other supercomputing platforms before using DP Technology products. These customers expect to reuse their existing resources as much as possible to improve the efficiency of resource utilization.
- Resource availability. Platforms provide computing resources for the AI4S users. Due to the large demand for resources, these users may need to use the preemptive and tidal resources at some point, showing demands for high availability and abundance of resources.
In general, the hybrid cloud architecture would be a good choice in terms of the above concerns.
Challenges
Still, there are also a few challenges of leveraging the hybrid cloud architecture in the production environment, which are mainly derived from the following differences between the hybrid cloud and supercomputing architecture.
- Fundamental facilities. The fundamental facilities of the public cloud are relatively open. You will get the root account once a virtual machine is assigned to you, in which resources are isolated in the underlying virtualized environment. You can use the machine as your own without influencing other cloud users. In comparison, the fundamental facilities of HPC are relatively close. HPC has a shared environment, and users are logically isolated from each other. It is fairly easy to use resources on the HPC platform but difficult to own the privilege to control resources. You cannot install software on a supercomputer as you want as the software may conflict with other users’ software installed on that supercomputer.
- Runtime environment. When running a service on the public cloud, the OSs and software that the application depends on are packed into a mirror image, which is allocated directly later in use. This approach can prevent runtime differences. However, HPC relies on module tools to manage environment variables, and thus software needs to be added via the module.
- Consistency of user experience, which is directly caused by the above two differences. How to mitigate the consistency difference so that users have a consistent experience in the viewing of logs and monitoring is also a challenge to the architecture.
Exploring the convergence of cloud and HPC
- Containerization
Podman and Singularity are two main container technologies used in supercomputing, and they have become more and more popular in recent years. Docker is not practical to use since it needs to start a daemon on the host and requires a root account.
- Slurm on Kubernetes
Slurm is widely used for resource management by supercomputers. Slurm was installed on physical machines in the early times. However, with the growing need for resource elasticity, we hope Slurm can be directly installed in Kubernetes so that resources can be allocated based on Kubernetes and Slurm can then be installed on the allocated pod.
- Virtual Kubelet
Virtual Kubelet is an implementation that masquerades as a kubelet. It has been used for elastic resources in AWS and Alibaba Cloud, equivalent to bridging some computing resources to be used by Kubernetes. Asimilar method has been being explored on supercomputers, attempting to let Kubernetes clusters use supercomputer resources through Virtual Kubelet.
Storage Challenge
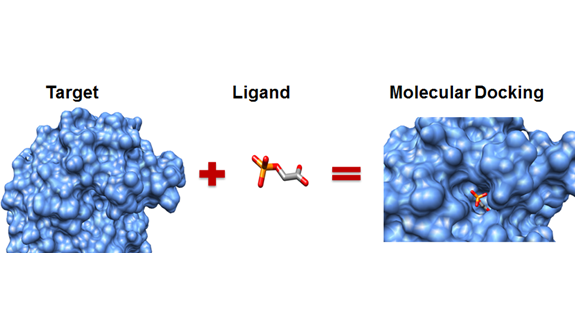
Here we take a storage use case in DPTechnology as an example.In drug design, molecular docking has great value in application.It is the process of mutual identification between two or more molecules, with the aim of finding the best binding mode between a drug molecule and a deadly target. The data requirements for a molecular docking process are as follows: about 600 million small files are generated, with 2.3T before compression and 1.5T after compression, with a single file size of about 4k.
If the files are small, it will be more difficult to process the data. For example, when dealing with many small files on Linux, it will firstly have the limitation of inode number, and secondly, the reading speed will not be good when there are more small files.
Storage requirements
Based on the above scenario, we summarize several storage requirements as follows.
- The diversity of files. The storage platform needs to support files in different sizes.
- Unified storage layer. Python is widely used in AI services, and Python services are usually POSIX compatible. Frequently downloading data from S3 or OSS during storage will affect user experience.
- Versatility. Public cloud solutions need to be applied to not only one cloud but also supercomputer and offline clusters.
- Data tiers. The data in this use case has a hot and cold characteristic. The data used during a calculating process is regarded as hot data, which will turn to cold data when the calculation finishes. The read and operations to cold data are much less frequent than to hot data.
- Security. It is hoped that the storage solution has some business isolation, quota, authorization and recycle bin after deletion to ensure the security of data.
Solution selection & JuiceFS test
After comparing different solutions, JuiceFS turns out to be the best solution in terms of the following aspects.
- Function satisfaction. It is essential that the solution can meet all the above-mentioned storage requirements.
- Tech stack. It should match the one currently used in DPTechnology.
- Operability. Operation and maintenance of the selected solution should be as easy as possible to reduce the cost when problems arise.
- Community activity. Active community means that emerged problems can be viewed and solved rapidly, which is one of the big considerations while selecting solutions.
We also did some tests for comparing different solutions, mainly focusing on:
- POSIX compatibility. This feature is a must for the solution to this scenario.
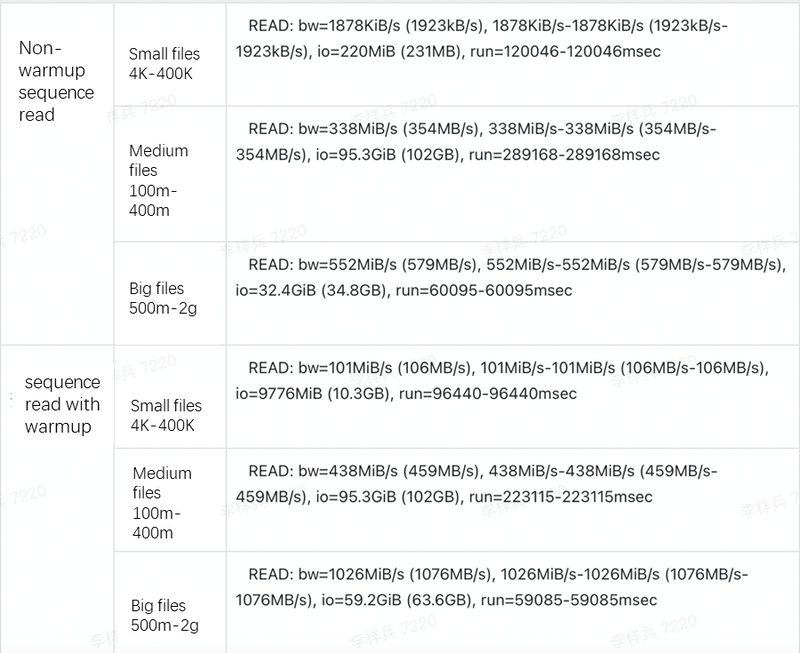
- Benchmark tests of performance. The test results are shown in the table below.
- Kubernetes CSI mounting. Some services are scheduled through Kubernetes, and accordingly we expect Kubernetes-friendly storage.
- PoC verification. There are many test scenarios, including scenarios with small files, large files, and sequential read, all of which can then be divided into using warm-up and not using warm-up.
It is worth mentioning that JuiceFS has a warm up feature. As the computing task replies GPU resources with a high cost, warming up the data locally before computing can highly reduce the cost.
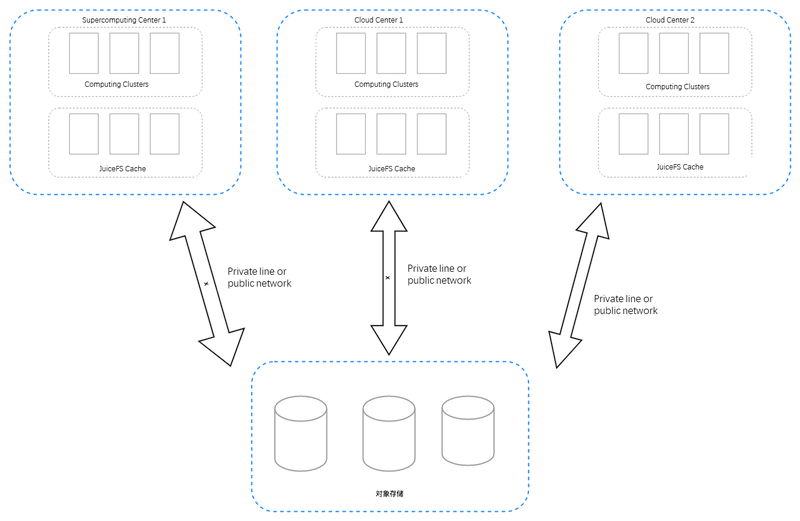
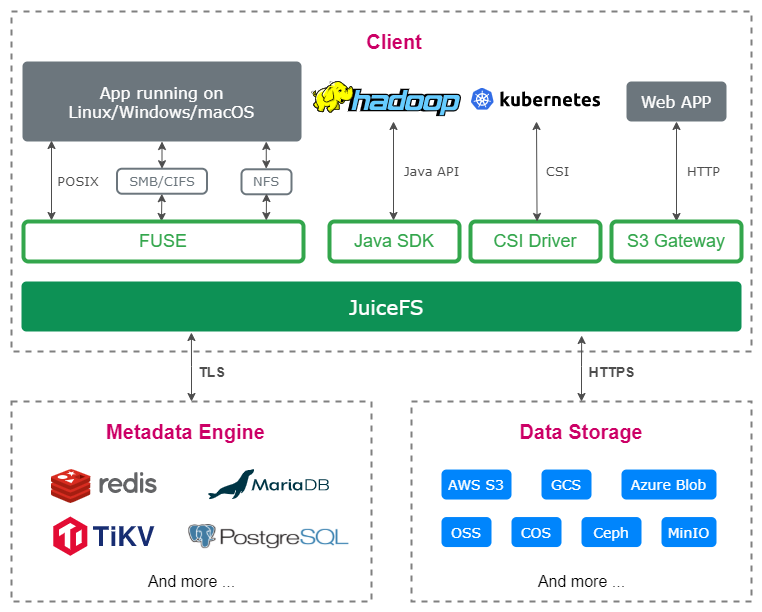
The above scheme is the storage architecture of DPTechnology. The underlying layer is a unified storage based on object storage, in which the data is then distributed to computing centers in various places. Both HPC and cloud servers have a cache cluster. The data from the unified storage will be stored in a cache cluster close to the computing cluster once the computing task starts, and thus the computing process only needs to communicate with local storage clusters.
JuiceFS can cache data locally, and the old data will expire automatically. Without JuiceFS, cache expiration needs to be implemented manually, which is usually tedious and can be costly.
DPTechnology currently uses JuiceFS Community Edition, with Redis as the metadata engine and SSD as the data cache.
04 Summary and outlook
The cloud and HPC convergence technology is trending. Today, many public clouds provide supercomputing services, so-called high-performance computing (HPC) services or clusters. Cloud-based supercomputing makes HPC resources easier to be utilized for everyone through virtualization and cloud-native technology.
When leveraging cloud and HPC convergence technology, containerization and runtime consistency is a key. If the cloud uses container but HPC uses another solution, you may encounter that some services run perfectly on the cloud but do not work in HPC.
Additionally, unifying storage is a challenge. It is relatively easy to schedule computing from a public cloud to a supercomputing platform. In comparison, scheduling storage is fairly difficult, which derives from:
- The difficulty of transferring data from one place to another place. It is of particular challenge to a large amount of data.
- Selection of networks for data transfer. The data transfer speed is directly associated with the network used.
- Data reference. It is essential to keep the path and structure of the data consistent before and after transferring.
- Data integration. For instance, if the whole computation is divided into 5 steps, and the first 2 steps are performed on the cloud while the last 3 steps are on the supercomputer, then the integration of data, logs, and monitoring needs to be included in storage scheduling.
Lastly, the separation of storage and computing is inevitable. In the early time, the storage and computing power was bounded, with the local disk mounted on the machine, and storage cannot be scheduled after the computing task has been scheduled.