















The rapid development in the field of large language model (LLM) applications is driving continuous exploration and advancement in fundamental technology. File storage services have become a crucial part of AI infrastructure.
Over the past 18 months, the JuiceFS team has engaged in discussions and collaborations with major model teams such as MiniMax and 01.AI. We’ve supported training tasks for thousands of GPU cards in production environments for multiple customers.
In this article, we’ll share some of the challenges that LLMs face in the storage domain and JuiceFS’ experience in dealing with these scenarios. We hope this post is helpful to related enterprises.
Balancing performance and cost in storage systems
For people starting to invest in pre-trained models, there was a view that GPUs were expensive, while the storage cost was negligible, so they could choose the most expensive storage solution with the best performance. Typical high-performance file systems include GPFS, Lustre, Weka, and other high-performance NAS solutions. These systems often rely on all-flash storage (NVMe) and high-performance networks to deliver extreme performance.
However, as computing power, data, and team investments grew, several new facts emerged:
-
According to 01.AI’s latest paper, Yi: Open Foundation Models by 01.AI (the Yi paper), their pre-training dataset contains 3 trillion tokens, processed through byte-pair encoding (BPE) tokenization, with each token taking about 2 bytes. This means that 3 trillion tokens roughly equals 6 TB of data. However, preparing datasets for formal training needs multiple preprocessing steps such as data crawling, cleaning, and transformation, involving a large amount of experimentation. The data processed in these experiments is typically more than 100 times the size of the formal training dataset. With team expansion, more experimental results and intermediate data will be generated, along with various model checkpoints and log data. Therefore, the total data volume for pre-training is expected to reach 10 PB to 100 PB.
-
In the formal training phase, although the dataset size is fixed at 6 TB, enterprises can store all data in high-performance storage systems. However, the performance of high-performance file systems is related to capacity. For example, providing 250 MBps throughput per TB of capacity means that storing just the 6 TB dataset in a high-performance file system can only provide 1,500 MB/s throughput. To achieve the required I/O performance for training, the capacity of high-performance file systems needs to be increased.
Due to cost considerations, users typically do not store all data only in high-performance file storage systems. In terms of capacity planning, such solutions lack the elastic usage capabilities of S3 and scaling is inconvenient.
Users have started adopting a strategy that combines object storage (about $0.02/GB/month) with high-performance file storage. While this approach is more cost-effective, it requires additional manpower and time to handle tasks such as data synchronization, migration, and consistency management between the two storage systems. These tasks are not only tedious but also contradictory to the goal of efficiency.
To address the performance and cost issues above, JuiceFS has these capabilities:
- Cost-effective object storage: JuiceFS uses object storage as the data persistence layer. This significantly reduced storage costs.
- Elastic capacity management: It provides capacity planning capabilities similar to elastic file storage, with elastic scaling mechanisms enhancing efficiency and eliminating the need for manual management.
- High performance: Compared to dedicated high-performance file systems, the performance of distributed file systems is one of the users' main concerns. JuiceFS provides efficient read/write throughput for pre-training through a multi-level caching acceleration architecture. Monitoring data from user production environments shows peak I/O throughput exceeding 340 GB/s. For more JuiceFS performance tuning strategies, see 98% GPU Utilization Achieved in 1k GPU-Scale AI Training Using Distributed Cache.
In terms of cost, JuiceFS Enterprise Edition is priced at only 20% of the cost of high-performance file storage AWS FSx for Lustre. The hardware resources required for the caching layer can use NVMe drives equipped on GPU nodes, incurring no additional costs. As a result, users can obtain an elastic high-performance file storage solution at only 20% of the cost, comparable in performance to traditional high-performance file storage systems, with better scalability. Moreover, it eliminates the need for users to consider issues such as data synchronization, migration, and consistency management between data and object storage.
Why POSIX is essential in AI training
Preparing high-quality training data is the foundation of building excellent base models. Data preparation is a complex process, as demonstrated in the Yi paper:
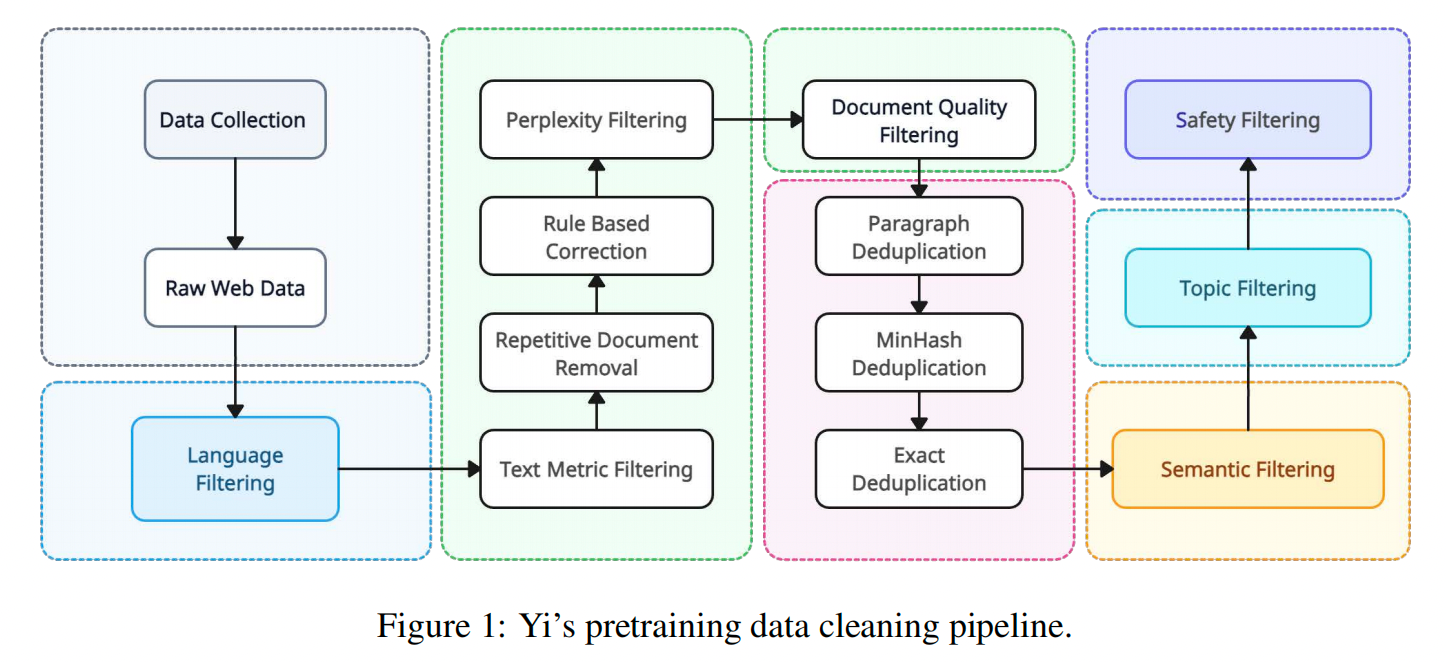
Each stage of data processing has unique requirements. Today there is still no unified paradigm for this process, and data engineers continue to experiment:
- Almost all data engineers use Python and they use Ray for parallel processing. If they use Spark, they program through PySpark. The flexibility and efficiency of these operations demand underlying file systems to have POSIX compatibility to efficiently meet various data processing needs.
- HDFS only supports append writes and does not support data processing methods that require overwrite operations, such as Pandas. Additionally, HDFS' Python SDK is not mature enough.
- Object storage solutions like S3 do not support efficient append or modification operations (only full replacements supported) and do not support renaming operations. Directory operation performance is slow. Although there are mature - Python SDKs, they still lack the simplicity and directness of POSIX. Furthermore, data processing may encounter bandwidth limitations in object storage and may face API queries per second (QPS) limits under high concurrency.
- When using solutions like s3fs to mount object storage like S3, it can support POSIX-style access. However, the performance of many operations can be much slower than expected. For example, overwriting a file requires downloading it locally for modification and then uploading it entirely again. This is different from partial overwrite operations in a file system. Renaming a directory also encounters similar issues. See Is POSIX Really Unsuitable for Object Stores? A Data-Backed Answer
- Using public-cloud NAS products, you can perform POSIX compatibility tests using pjdfstest. See POSIX Compatibility Comparison Among Four File Systems on the Cloud. Another issue is that NAS performance is linearly related to data volume, so using it may encounter the problem that the current data volume cannot meet computing needs.
Therefore, for data engineers, a fully functional POSIX file system is the best companion for data processing and cleaning tasks. JuiceFS is fully POSIX compliant and also supports HDFS and S3 API access. It effectively supports various computing loads throughout the data processing and cleaning process.
Regarding the crucial role of POSIX compatibility in AI training, you can refer to a case study, South Korea's No.1 Search Engine Chose JuiceFS over Alluxio for AI Storage.
Multi-cloud architecture: Challenges in data synchronization and consistency management
Whether for training or inference needs, the resources of a single data center or cloud region often cannot fully meet users' demands. Especially for applications targeting consumer-facing platforms, deploying across multiple regions is necessary to provide a better user experience. In such cases, users face challenges including dataset and model distribution, synchronization, and consistency management across multiple regions.
The figure below shows a user's initial data management scheme when adopting a multi-cloud architecture:
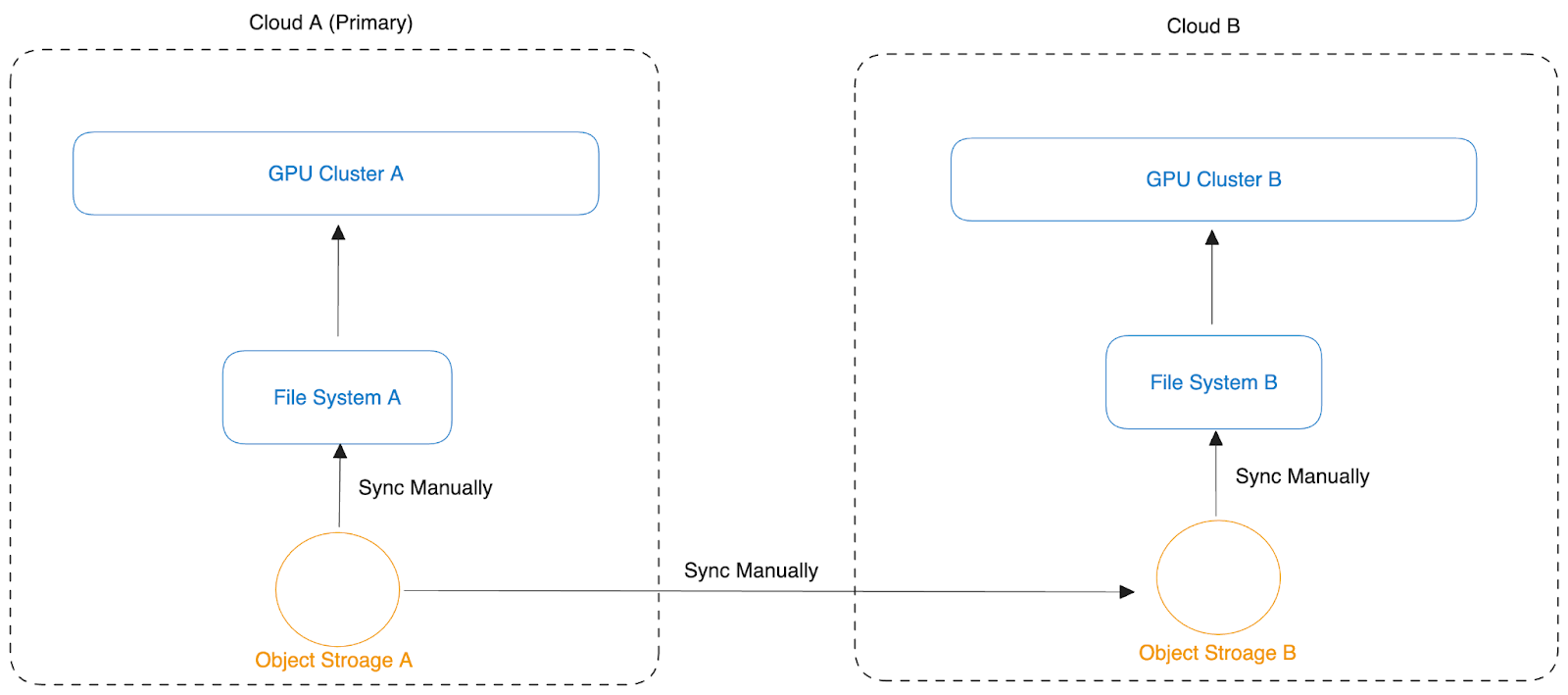
The user encountered these challenges:
- Data synchronization between object storage A and object storage B: While handling data synchronization between object storages, methods such as scheduled synchronization of specific data prefixes or designing object update callbacks to trigger synchronization work effectively for small-scale data processing. However, the complexity of these synchronization solutions sharply rises when dealing with large-scale data. Challenges include managing concurrent execution of synchronization tasks, ensuring the reliability of data synchronization, data recovery after task failures, system observability, traffic control, and data consistency verification.
- Data synchronization between high-performance file storage and object storage: Due to the limited capacity of high-performance file storage, manual decisions are needed to determine which data is necessary in the near term and schedule appropriate times to copy this data from object storage. When storage space is insufficient, coordination among numerous team members is required to decide which data to delete to free up space. This process introduces complexity as each person tends to retain their data to avoid deletion, making decisions about scaling or internal team coordination a complex issue. Scaling is not just about costs but also involves additional operational work and resource allocation. This increases the complexity and management difficulty of synchronization tasks.
- Data synchronization between high-performance file systems in different regions: After a user's task is completed in region A and scheduled to execute in region B, the data set used by task A must be accessible in region B, and its previous execution outputs and logs must also be accessible.
- Challenges in synchronization management and consistency guarantee: Choosing between strong consistency and eventual consistency depends on application requirements and the complexity of technical implementations. Eventual consistency requires defining its time window to ensure overall system reliability and expected behavior.
- Storage system differences: These systems often have slight differences in product performance, usage limitations, and management strategies. These differences require users to adopt refined synchronization and management methods to ensure data consistency and system efficiency.
Maintaining the data architecture above manually results in significant operational burdens. If there are more than two regions, all the mentioned issues become even more complex. To solve these problems in an automated manner, JuiceFS developed its mirroring functionality. It now becomes an essential feature in LLM training and inference operations.
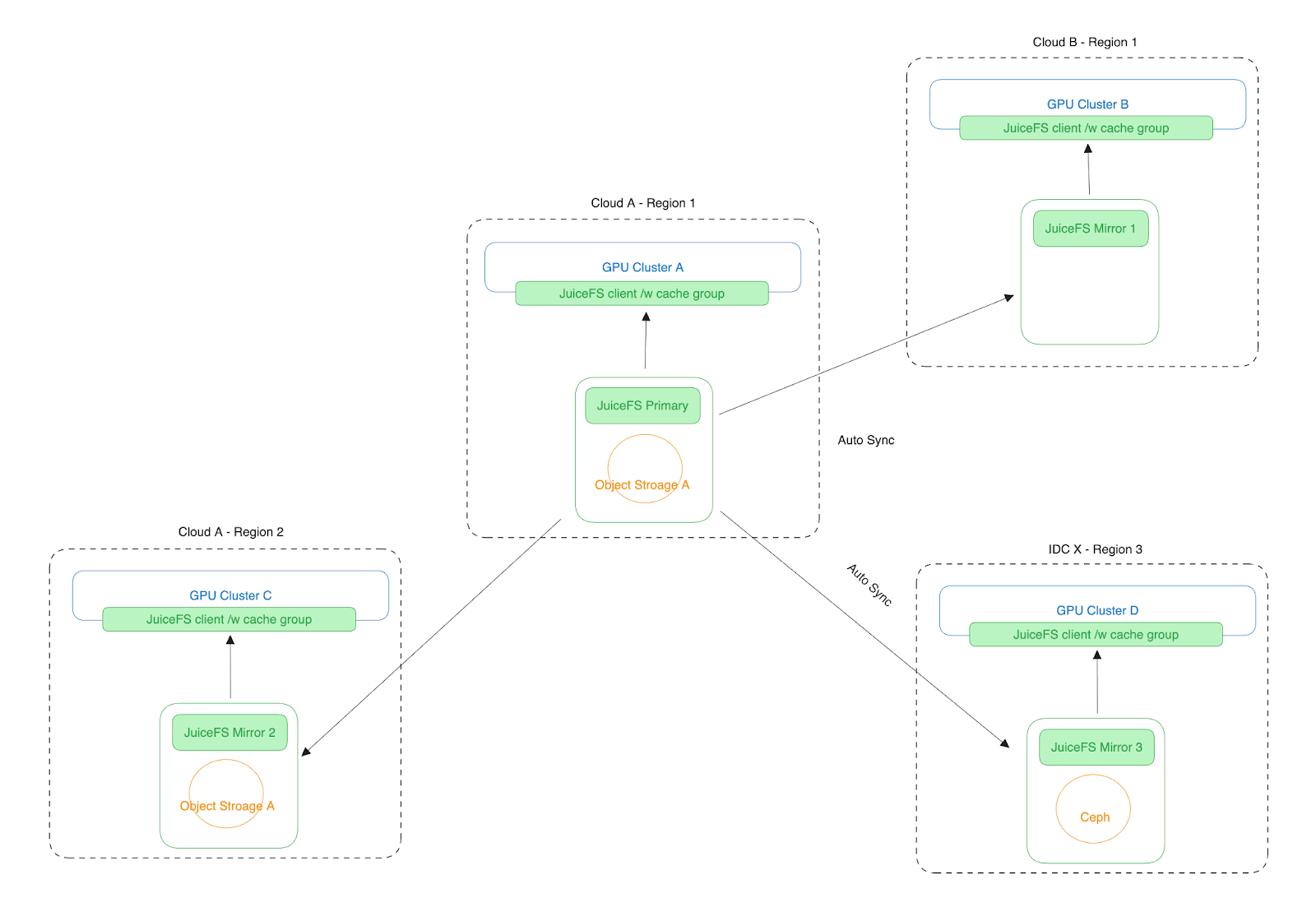
In JuiceFS' data mirroring solution, all data changes at primary sites are automatically synchronized to various mirror sites. Metadata synchronization is completed within defined time windows, achieving millisecond-level latency within the same city, approximately 10-30 milliseconds across cities within China, and sub-minute latency across continents. During specified time windows, mirror sites ensure data consistency.
The time taken for data synchronization is the same as transmitting a 4 MB file in a network environment. If data synchronization is incomplete, JuiceFS automatically handles the I/O paths when accessing files from mirror sites to ensure file accessibility. This mechanism may lead to temporary performance declines but does not affect program execution correctness. When users generate new data and write it to JuiceFS at mirror sites, the data is automatically written back to the data source site, and the write performance depends on network conditions. See how Zhihu, China’s Quora, uses JuiceFS mirroring functionality in a multi-cloud architecture.
Slow model loading leads to long GPU waiting time
Model loading refers to the process of fully reading and loading a model into the video memory. This process is involved in training startup, training resumption, and inference service deployment. Models are typically large files, with sizes ranging from tens of gigabytes to terabytes as model parameters increase, often stored in formats like pickle or safetensor. The loading process requires sequential reading from the storage system, and a key factor affecting speed is the throughput of single-threaded sequential reading. Currently, JuiceFS has achieved a model loading throughput performance of 1,500 MB/s. It can be improved to 3 GB/s after optimizations for model loading scenarios.
On the other hand, let's take the example of loading a pickle-format model using PyTorch. During sequential reading of the model file, the process also involves deserializing the pickle data, which is time-consuming. In our tests, loading a Llama 2 7B full-precision model from an in-memory disk, in pickle format with a size of 26 GB, achieved a throughput performance of 2.2 GB/s. Because memory is the fastest storage medium, we consider this as the limit. Loading the same model from JuiceFS achieved a throughput performance of 2.07 GB/s, which is 94% of the limit.
Due to such performance, an increasing number of AI users are storing models in JuiceFS for inference tasks. This speeds up model loading and saves significant GPU costs. See how BentoML reduced LLM loading time from 20+ to a few minutes. BentoML offers model deployment SaaS service that manages a large number of models for customers and is highly concerned about its model loading performance.
Conclusion
In the past two years, LLMs have rapidly evolved, with parameter sizes increasing rapidly. This not only means larger model sizes but also implies faster growth in training data scale, which poses significant challenges for storage systems.
JuiceFS' capabilities have been recognized by customers:
- Cost-effectiveness
- 100% POSIX compatibility while supporting HDFS and S3 protocols
- Elastic scalability of cluster throughput via caching clusters
- Automatic multi-cloud data synchronization, eliminating the inefficiency of manual migration and consistency management challenges
- Accelerating model deployment and saving inference costs
We’ll continue to share changes in AI development we’ve observed and explore storage solutions. If you’d like to exchange ideas with us, feel free to join JuiceFS discussions on GitHub and our community on Slack.